




 本文介绍了如何在Windows和Linux环境下使用MapReduce进行词频统计,包括创建Maven工程,配置依赖,编写Mapper和Reducer,以及三种运行方式:本地测试、打包上传到集群和本地提交到集群。此外,还展示了如何实现中文分词的Mapper类。
本文介绍了如何在Windows和Linux环境下使用MapReduce进行词频统计,包括创建Maven工程,配置依赖,编写Mapper和Reducer,以及三种运行方式:本地测试、打包上传到集群和本地提交到集群。此外,还展示了如何实现中文分词的Mapper类。
文章目录
Windows和Linux环境
https://yellow520.blog.youkuaiyun.com/article/details/115484893
MapReduce词频统计入门
YARN上跑MapReduce 原理简图

MapReduce词频统计 原理简图

1、创建名为WordCount的Maven工程
2、pom.xml加入依赖和插件
注意
mainClass要修改
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>a.b.c.MyDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3、在resources下创建log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
4、自定义Mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
5、自定义Reducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key, v);
}
}
6、程序执行入口
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 打包到集群,执行命令:hadoop jar WordCount-1.0-SNAPSHOT.jar a.b.c.MyDriver /input /output
*/
public class MyDriver {
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(MyDriver.class);
// 3 设置map和reduce类
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
// 8 退出
System.exit(result ? 0 : 1);
}
}
7、三种运行方式
7.1、本地测试
configuration => application
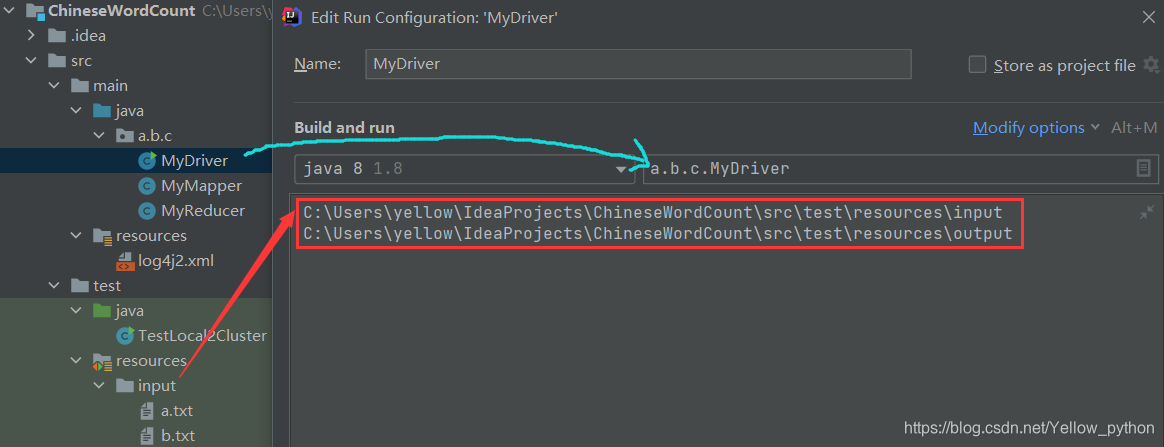
7.2、打包上传到集群,执行命令
Maven在IDEA的最右边
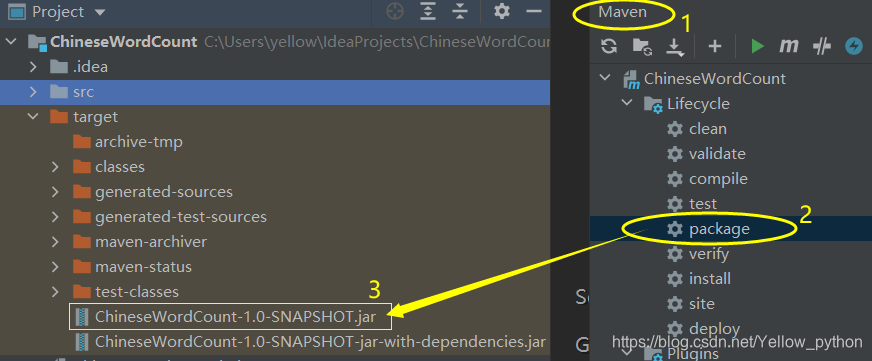
hadoop fs -mkdir /input
echo "a a b" > ~/b.txt
hadoop fs -put ~/b.txt /input/
hadoop jar WordCount-1.0-SNAPSHOT.jar a.b.c.MyDriver /input /output
7.3、本地提交到集群
新建
Local2Cluster.java文件
注意:
打包时用job.setJarByClass
打包后用job.setJar
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Local2Cluster {
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
// 0 配置
Configuration configuration = new Configuration();
// 指定active的NameNode的PRC地址
configuration.set("fs.defaultFS", "hdfs://hadoop100:8020/");
// 指定MapReduce运行在YARN上
configuration.set("mapreduce.framework.name", "yarn");
// 允许MapReduce运行在远程集群上
configuration.set("mapreduce.app-submission.cross-platform", "true");
// 指定active的ResourceManager地址
configuration.set("yarn.resourcemanager.hostname", "hadoop102");
// 1 封装任务
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
// 打包后注释掉,打包前不注释
//job.setJarByClass(Local2Cluster.class);
// 打包后把jar包路径复制到这里
// 打包前注释掉,打包后不注释
job.setJar("C:\\Users\\yellow\\IdeaProjects\\ChineseWordCount\\target\\ChineseWordCount-1.0-SNAPSHOT.jar");
// 3 设置map和reduce类
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
// 8 退出
System.exit(result ? 0 : 1);
}
}
修改
VM options
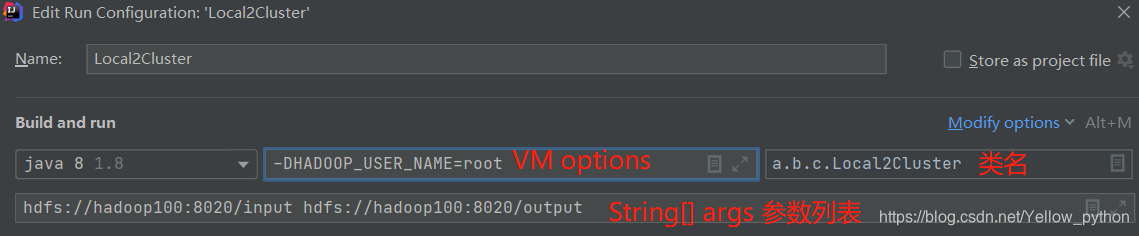
MapReduce+中文分词+词频统计
4、自定义Mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
class Tokenizer {
private static final double minDouble = -9e99;
private static final String reEn = "[a-zA-Z]+";
private static final String reNum = "[0-9]+%?|[0-9]+[.][0-9]+%?";
private HashMap<String, Integer> w2f; // word2frequency
private double logTotal;
private int maxLen = 1;
class Pair {
double _1;
int _2;
Pair(double a, int b) {
_1 = a;
_2 = b;
}
@Override
public String toString() {
return "(" + _1 + "," + _2 + ")";
}
}
public Tokenizer() {
w2f = new HashMap<>();
w2f.put("空调", 2);
w2f.put("调和", 2);
w2f.put("和风", 2);
w2f.put("风扇", 2);
w2f.put("和", 2);
int total = 0;
for (Map.Entry<String, Integer> kv : w2f.entrySet()) {
int len = kv.getKey().length();
if (len > maxLen) {
maxLen = len;
}
total += kv.getValue();
}
logTotal = Math.log10(total);
}
public HashMap<Integer, Pair> calculate(String clause) {
// 句子长度
int len = clause.length();
// 有向无环图
HashMap<Integer, ArrayList<Integer>> DAG = new HashMap<>();
// 词图扫描
for (int head = 0; head < len; head++) {
int tail = Math.min(len, head + maxLen);
DAG.put(head, new ArrayList<>());
DAG.get(head).add(head);
for (int mid = head + 2; mid < tail + 1; mid++) {
String word = clause.substring(head, mid);
if (w2f.containsKey(word)) {
DAG.get(head).add(mid - 1); // 词库匹配
} else if (word.matches(reEn)) {
DAG.get(head).add(mid - 1); // 英文匹配
} else if (word.matches(reNum)) {
DAG.get(head).add(mid - 1); // 数字匹配
}
}
}
// 最短路径
HashMap<Integer, Pair> route = new HashMap<>();
route.put(len, new Pair(0.0, 0));
// 动态规划
for (int i = len - 1; i > -1; i--) {
Pair maxStatus = new Pair(minDouble, 0);
for (Integer x : DAG.get(i)) {
double logFreq = Math.log10(w2f.getOrDefault(clause.substring(i, x + 1), 1));
double status = logFreq - logTotal + route.get(x + 1)._1;
if (status > maxStatus._1) {
maxStatus._1 = status;
maxStatus._2 = x;
}
}
route.put(i, maxStatus);
}
return route;
}
public ArrayList<String> cut(String clause) {
// 计算最短路径
HashMap<Integer, Pair> route = calculate(clause);
// 句子长度
int len = clause.length();
// 分词列表
ArrayList<String> words = new ArrayList<>();
// 根据最短路径取词
int x = 0;
while (x < len) {
int y = route.get(x)._2 + 1;
String l_word = clause.substring(x, y);
words.add(l_word);
x = y;
}
return words;
}
}
public class CnMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
Tokenizer tk = new Tokenizer();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
ArrayList<String> words = tk.cut(line);
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}


















 7974
7974






 到【灌水乐园】发言
到【灌水乐园】发言









