




 本文详细介绍了HBase的安装、配置、集群部署,包括依赖设置、配置文件编辑、高可用性配置、解决日志冲突和文件分发,以及常用命令和原理概述。涉及核心概念如Key-Value模型和数据模型,适合HBase入门者和运维人员参考。
本文详细介绍了HBase的安装、配置、集群部署,包括依赖设置、配置文件编辑、高可用性配置、解决日志冲突和文件分发,以及常用命令和原理概述。涉及核心概念如Key-Value模型和数据模型,适合HBase入门者和运维人员参考。
文章目录
Hbase简介
- HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库
- 数据存储在HDFS
- 物理存储结构【Key-Value】型,就像一个多维Map
- 特性:
延时低(冷热数据思想)
Key-Value可以映射为二维表,可作为巨型单表作为查询
提供 数据多版本溯源 功能 - 使用场景:
存储海量实时计算结果数据
字段会变更的场景 - 官网:http://hbase.apache.org/
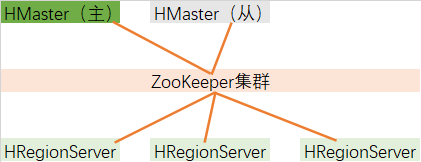
HBase集群部署
| 名称 | 下载地址 | 本文版本 |
|---|---|---|
| HBase | https://mirrors.bfsu.edu.cn/apache/hbase/ | 2.4.2 |
| 集群规划 | 服务名 | hadoop100 | hadoop101 | hadoop102 |
|---|---|---|---|---|
| HBase | HMaster | 1 | 1 | |
| HBase | HRegionServer | 1 | 1 | 1 |
HMaster借助ZooKeeper来管理HRegionServer
1、依赖
- 预装Hadoop、ZooKeeper集群并启动
- 集群环境变量添加
HBASE_HOME
2、上传HBase、解压、改名
tar -zxf hbase-2.4.2-bin.tar.gz -C /opt/
cd /opt
mv hbase-2.4.2 hbase
3、配置文件
cd $HBASE_HOME/conf/
3.1、hbase-env.sh
vi hbase-env.sh
在vim可以用:/HBASE_MANAGES_ZK查找
export HBASE_MANAGES_ZK=false
不启用HBase自带ZooKeeper,而使用自己装的ZooKeeper
3.2、hbase-site.xml
vi hbase-site.xml
加入到configuration里面
<!-- 数据存储到HDFS的哪里 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop100:8020/hbase</value>
</property>
<!-- 是否启用分布式集群:false是单机模式,true是分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper集群地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop100,hadoop101,hadoop102</value>
</property>
<!-- 是否开启安全性检查,此处关闭 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
重要补充:如果Hadoop是高可用的,那么就要用Hadoop的高可用集群名称
<property>
<name>hbase.rootdir</name>
<value>hdfs://myha/hbase</value>
</property>
3.3、regionservers
echo hadoop100 > regionservers
echo hadoop101 >> regionservers
echo hadoop102 >> regionservers
cat regionservers
或
cat $HADOOP_HOME/etc/hadoop/workers > regionservers
cat regionservers
3.4、backup-masters【高可用】
echo hadoop101 > backup-masters
4、解决日志冲突
cd $HBASE_HOME/lib/client-facing-thirdparty/
mv slf4j-log4j12-1.7.30.jar slf4j-log4j12-1.7.30.jar.backup
5、文件分发
rsync -a $HBASE_HOME/ hadoop101:$HBASE_HOME/
rsync -a $HBASE_HOME/ hadoop102:$HBASE_HOME/
6、启停命令
启动前请确保ZooKeeper和Hadoop服务正在运行
start-hbase.sh
stop-hbase.sh
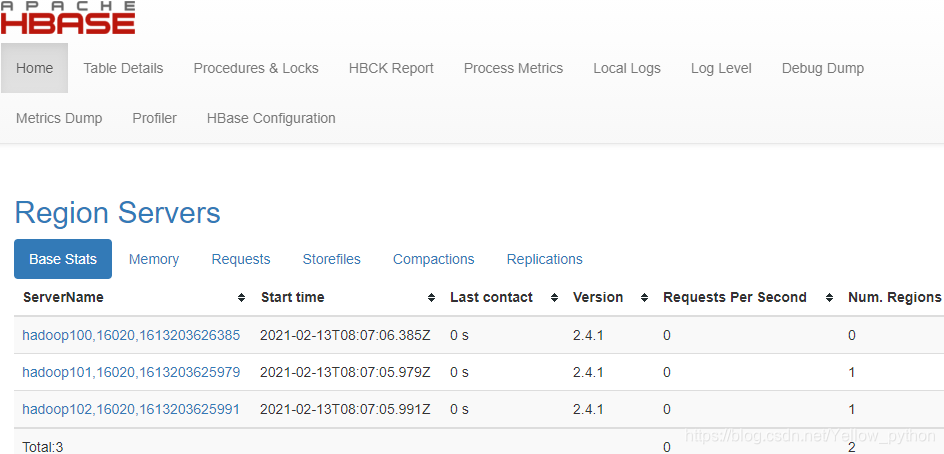
7、浏览器访问
端口
16010
常用命令
进入客户端
hbase shell
| 常用命令 | 说明 |
|---|---|
create_namespace | 创建命名空间(类似MySQL建库) |
list_namespace | 查看有哪些命名空间 |
create | 创建(类似MySQL建表) |
scan | 扫描(查数据) |
put | 写数据 |
get | 读数据(查数据) |
disable | 禁用 |
delete | 删除 |
drop | 终止 |
quit | 退出 |
操作
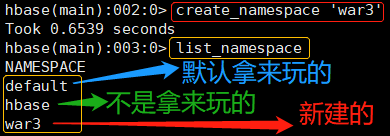
# 1、创建命名空间(相当于MySQL建库);查看有哪些命名空间
create_namespace 'war3'
list_namespace
# 2、创建表;查看表信息
create 'war3.hero','base_info','extra_info'
describe 'war3.hero'
# 3、插入数据到表
put 'war3.hero','I001','base_info:name','剑圣'
put 'war3.hero','I002','base_info:name','KOG'
put 'war3.hero','I002','extra_info:halo','荆棘'
put 'war3.hero','I003','base_info:name','守望者'
put 'war3.hero','I003','base_info:gender','女'
put 'war3.hero','I003','extra_info:weapon','丝袜'
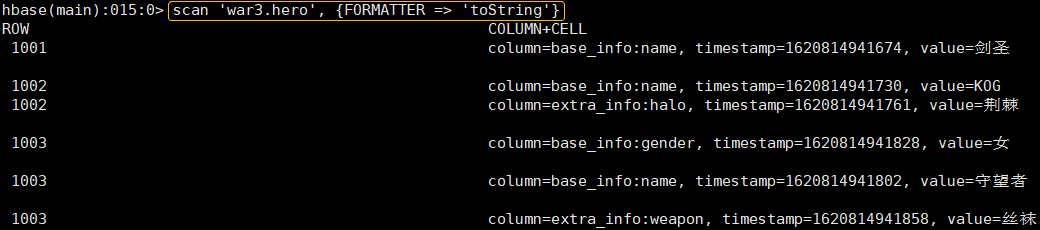
# 4、扫描查看表数据(FORMATTER => 'toString'用来显示中文)
scan 'war3.hero',{FORMATTER => 'toString'}
scan 'war3.hero',{STARTROW => '1001', STOPROW => '1003', FORMATTER => 'toString'}
# 5、查看【某个表】的【指定行】和【指定列】
get 'war3.hero','1002','base_info:name'
# 6、统计表数据行数
count 'war3.hero'
# 7、删除数据
## 7.1、删除某rowkey的全部数据:
deleteall 'war3.hero','1002'
## 7.2、删除某rowkey的某列数据:
delete 'war3.hero','1003','base_info:gender'
# 8、清空表数据
truncate 'war3.hero'
# 9、删除表
## 9.1、首先需要先让该表为disable状态:
disable 'war3.hero'
## 9.2、然后才能drop这个表:
drop 'war3.hero'
## 10、退出
quit
创建命名空间(建库);查看有哪些命名空间
全表扫描
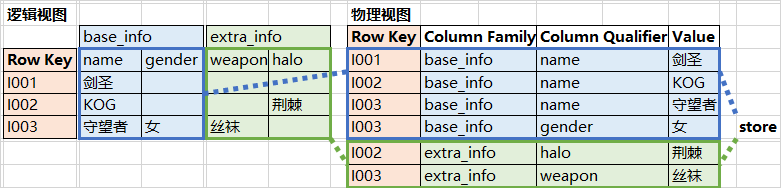
逻辑视图 & 物理视图
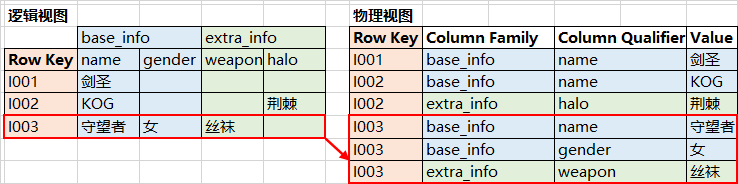
原理补充
架构简图
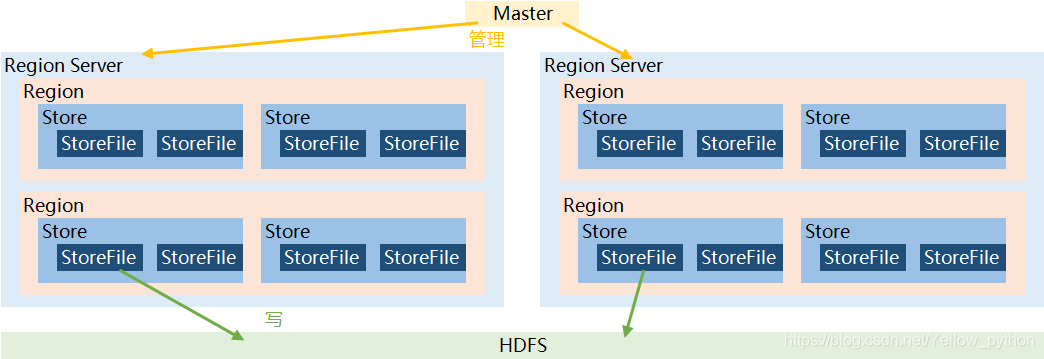
Master是Region Server的管理者
实现类:HMaster
对于表的操作:create、delete、alter
Region Server是Region的管理者
实现类:HRegionServer
对于数据的操作:get、put、delete
对Region操作,例如:Region切分…
概念视图(Conceptual View)、物理视图(Physical View)
概念视图(Conceptual View)
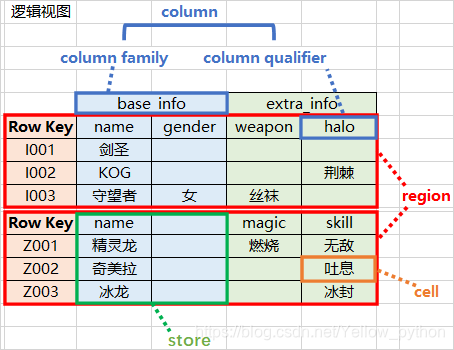
物理视图(Physical View)
store
数据模型(Data Model)
| 数据模型 | 说明 | 补充说明 |
|---|---|---|
| NameSpace | 命名空间;每个namespace下面有多个table | |
| table | 由多个row组成 | |
| row | A row in HBase consists of a row key and one or more columns with values associated with them | row储存按row key的字母顺序排列 |
| column | 由 1个column family 和 1个column qualifier 组成 | 用冒号:分隔 |
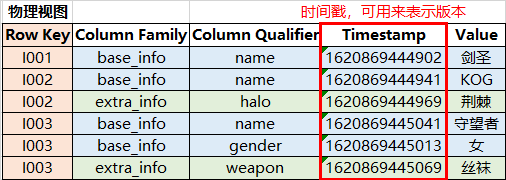
| cell | row、column family和column qualifier3者联合确定 | 包含 1个value 和 1个timestamp |
| timestamp | 伴随value写入,可作为版本的标识符 | 默认是RegionServer的时间,也可指定 |
-
Column Family
- Column families physically colocate a set of columns and their values, often for performance reasons. Each column family has a set of storage properties, such as whether its values should be cached in memory, how its data is compressed or its row keys are encoded, and others. Each row in a table has the same column families, though a given row might not store anything in a given column family. Column Qualifier
-
A column qualifier is added to a column family to provide the index for a given piece of data. Given a column family
content, a column qualifier might becontent:html, and another might becontent:pdf. Though column families are fixed at table creation, column qualifiers are mutable and may differ greatly between rows.
Appendix
| en | 🔉 | cn |
|---|---|---|
| quorum | ˈkwɔːrəm | n. 法定人数 |
| thirdparty | third party | n. 第三者,第三方 |
| conceptual | kənˈseptʃuəl | adj. 概念上的 |
| family | ˈfæməli | n. 家庭;[化]族;adj. 家庭的;家族的 |
| qualifier | ˈkwɑːlɪfaɪər | n. [语] 修饰语;限定符;修饰符;资格赛;取得资格的人 |
| mutable | ˈmjuːtəbl | adj. 可变的;易变的 |
| compaction | kəmˈpækʃən | n. 压紧;精简;密封;凝结 |


















 3713
3713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











