




 本文详细介绍了Spark MLlib的使用,包括环境配置、内置样本、回归、分类、流水线、频繁模式挖掘、协同过滤和聚类等核心功能。通过实例展示了如何使用Spark进行机器学习,涵盖了从数据加载、模型训练到预测的全过程,并探讨了SparkMLlib与SparkML的区别。此外,还提供了关键参数的解释,如协同过滤中的秩(rank)和正则化参数(regParam)。
本文详细介绍了Spark MLlib的使用,包括环境配置、内置样本、回归、分类、流水线、频繁模式挖掘、协同过滤和聚类等核心功能。通过实例展示了如何使用Spark进行机器学习,涵盖了从数据加载、模型训练到预测的全过程,并探讨了SparkMLlib与SparkML的区别。此外,还提供了关键参数的解释,如协同过滤中的秩(rank)和正则化参数(regParam)。
文章目录
0、环境配置
- CentOS7安装Scala和Spark
- Win10安装Scala和Spark
pom.xml额外配置
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.0.2</version>
</dependency>
- 创建
Hello.scala并写入外壳代码(复制用)
import org.apache.spark.sql.SparkSession
object Hello {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val spark: SparkSession = SparkSession.builder()
.master("local[*]").appName("a1").getOrCreate()
//隐式转换支持
import spark.implicits._
}
}
1、SparkMLlib简介
- 全称:Spark’s machine learning library
- 译名:Spark的机器学习库
| 主要功能 | 简述 | 详细 |
|---|---|---|
| ML Algorithms | 机器学习算法 | 分类、回归、聚类、协同过滤 |
| Featurization | 特征工程 | 特征的 抽取、转换、选择、降维 |
| Pipelines | 管道 | tools for constructing, evaluating, and tuning ML Pipelines |
| Persistence | 持久化 | 保存和加载模型 |
| Utilities | 实用工具 | 线性代数、统计学 |
补充说明
本攻略Spark版本≥3,建议使用基于DataFrame的APIspark.ml,称作Spark ML
2、内置样本(Data sources)
- Spark内置样本在
$SPARK_HOME/data - 我们去到Linux服务器,把内置样本上传到HDFS,然后可以进入
spark-shell来读数据
cd $SPARK_HOME/data/mllib/
hadoop fs -put sample_linear_regression_data.txt /
spark-shell
spark.read.format("libsvm").load("/sample_linear_regression_data.txt").show(5,99)
样本长相

3、回归(Regression)
数据续2
import org.apache.spark.ml.regression.LinearRegression
// 样本加载
val xy = spark.read.format("libsvm").load("/sample_linear_regression_data.txt")
// 建模
val lr = new LinearRegression().setMaxIter(9).setRegParam(.3).setElasticNetParam(.8)
// 训练
val lrModel = lr.fit(xy)
// 打印系数和截距
print(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
4、分类(Classification)
下面以文本分类为例
// 创建数据
val label2comment = Map(0 -> "好", 1 -> "中", 2 -> "差")
val sentenceDf = Seq(
(0, "优秀 好味 精彩 软滑 白嫩 干货 超神 醍醐灌顶 不要不要的"),
(1, "普通 一般般 无感 中规中矩 乏味 中立 还行 可以可以"),
(2, "难吃 金玉其外 发货慢 无语 弱鸡 呵呵 水货 渣渣 超鬼"),
).toDF("label", "sentence")
// 特征工程
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
// 分词
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsDf = tokenizer.transform(sentenceDf)
// 编码
val hashingTF = new HashingTF()
.setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(10)
val hashingDf = hashingTF.transform(wordsDf)
// TF-IDF训练+转换
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(hashingDf)
val tfidfDf = idfModel.transform(hashingDf)
tfidfDf.show(numRows = 9, truncate = false)
// 逻辑回归
import org.apache.spark.ml.classification.LogisticRegression
val lr = new LogisticRegression()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setProbabilityCol("Probability")
// 逻辑回归拟合
val fittedLr = lr.fit(tfidfDf)
// 预测
val prediction = fittedLr.transform(
idfModel.transform(
hashingTF.transform(
tokenizer.transform(
Seq("无感 还行", "呵呵 渣渣", "干货 好味").toDF("sentence")
)
)
)
)
prediction.show()
打印结果

5、流水线(Pipelines)
- pipeline译作管道,其复数形式pipelines可译为流水线
- 个人理解:把多道工序串成一条流水线
- 代码示例,留意
Pipeline(第26行)
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// 训练集
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// 安装一个由【tokenizer hashingTF lr】串成的流水线
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// 输入训练数据来拟合pipeline
val model = pipeline.fit(training)
// 保存拟合好的pipeline到磁盘
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// 保存还没拟合的pipeline到磁盘
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// 加载拟合好的pipeline
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// 测试集
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// 预测
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
6、Frequent Pattern Mining
- 应用场景:商品关联
例如:
a b c
b c d
↓↓↓
ab共现1次
bc共现2次
ad共现0次
// 创建数据
val df = Seq(
"1 2 5",
"1 2 3 5",
"1 2"
).map(_.split(" ")).toDF("items")
// Frequent Pattern Growth 建模训练
import org.apache.spark.ml.fpm.FPGrowth
val fpGrowth = new FPGrowth().setItemsCol("items").setMinSupport(0.5).setMinConfidence(0.6)
val model = fpGrowth.fit(df)
// 共现频数
model.freqItemsets.show()
/*
+---------+----+
| items|freq|
+---------+----+
| [1]| 3|
| [2]| 3|
| [2, 1]| 3|
| [5]| 2|
| [5, 2]| 2|
|[5, 2, 1]| 2|
| [5, 1]| 2|
+---------+----+
*/
// 关联规则
model.associationRules.show()
/*
+----------+----------+------------------+----+
|antecedent|consequent| confidence|lift|
+----------+----------+------------------+----+
| [2, 1]| [5]|0.6666666666666666| 1.0|
| [5, 1]| [2]| 1.0| 1.0|
| [2]| [1]| 1.0| 1.0|
| [2]| [5]|0.6666666666666666| 1.0|
| [5]| [2]| 1.0| 1.0|
| [5]| [1]| 1.0| 1.0|
| [1]| [2]| 1.0| 1.0|
| [1]| [5]|0.6666666666666666| 1.0|
| [5, 2]| [1]| 1.0| 1.0|
+----------+----------+------------------+----+
*/
// 预测
model.transform(Seq(
"1 2",
"1 5",
"1 2 3 5",
"1 2 3",
"5 2"
).map(_.split(" ")).toDF("items")).show()
/*
+------------+----------+
| items|prediction|
+------------+----------+
| [1, 2]| [5]|
| [1, 5]| [2]|
|[1, 2, 3, 5]| []|
| [1, 2, 3]| [5]|
| [5, 2]| [1]|
+------------+----------+
*/
| 方法 | 说明 | 默认值 |
|---|---|---|
setItemsCol | 设置 输入列的名称 | items |
setMinSupport | 过滤低频;最低门槛=minSupport
×
\times
×size-of-the-dataset | 0.3 |
setMinConfidence | 设定置信度门槛,低于该值将被过滤;定义域[0,1] | 0.8 |
7、协同过滤(Collaborative Filtering)
- 思想:想看电影,但不造看啥,此时可以问兴趣相近的朋友,有什么好电影推荐。
以 Alternating Least Squares 交替最小二乘 矩阵分解 为例
一个稀疏矩阵,可以使用Alternating Least Squares分解成两个小矩阵相乘
然后两个小矩阵相乘,就可以估算出稀疏矩阵缺失的值
所谓交替,就是交替训练两个矩阵(固定I训练U,固定U训练I)
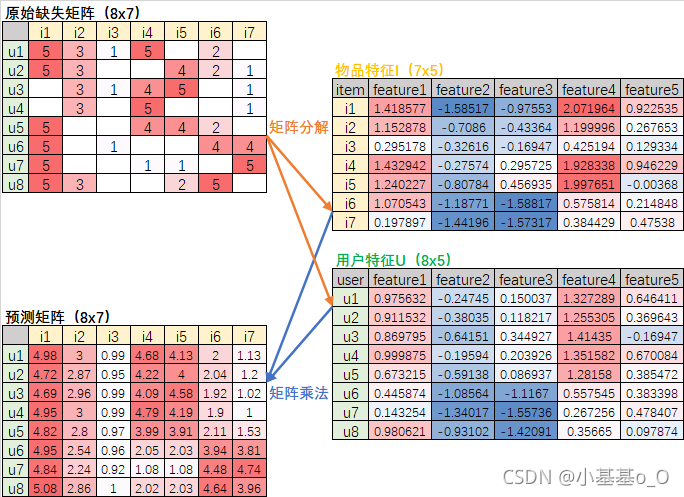
// 创建SparkSession对象
import org.apache.spark.sql.SparkSession
val spark: SparkSession = SparkSession.builder()
.master("local[*]").appName("a0").getOrCreate()
// 隐式转换支持
import spark.implicits._
// 创建数据
val df = Seq(
(1, 1, 5), (1, 2, 3), (1, 3, 1), (1, 4, 5), (1, 6, 2),
(2, 1, 5), (2, 2, 3), (2, 5, 4), (2, 6, 2), (2, 7, 1),
(3, 2, 3), (3, 3, 1), (3, 4, 4), (3, 5, 5), (3, 7, 1),
(4, 2, 3), (4, 4, 5), (4, 7, 1),
(5, 1, 5), (5, 4, 4), (5, 5, 4), (5, 6, 2),
(6, 1, 5), (6, 3, 1), (6, 6, 4), (6, 7, 4),
(7, 1, 5), (7, 4, 1), (7, 5, 1), (7, 7, 5),
(8, 1, 5), (8, 2, 3), (8, 5, 2), (8, 6, 5),
).toDF("user", "item", "rating")
// Alternating Least Squares (ALS) matrix factorization
import org.apache.spark.ml.recommendation.ALS
val als = new ALS().setRank(5) //rank:矩阵分解的秩
val model = als.fit(df)
// 物品特征
model.itemFactors.sort("id").show(false)
// 用户特征
model.userFactors.sort("id").show(false)
// 为每个用户推荐物品
model.recommendForAllUsers(7).sort("user").show(false)
// 为每个物品推荐用户
model.recommendForAllItems(8).sort("item").show(false)
| 常用参数 | 原文 | 译文 | 默认值 |
|---|---|---|---|
rank | Param for rank of the matrix factorization (positive) | 矩阵分解的秩,该参数是正数 | 10 |
implicitPrefs | Param to decide whether to use implicit preference | 是否使用隐含偏好 | false |
ratingCol | Param for the column name for ratings | 评价列名称 | rating |
userCol | Param for the column name for user ids | 用户列名称,该输入列的数据要求数字类型 | user |
itemCol | Param for the column name for item ids. | 物品列名称,该输入列的数据要求数字类型 | item |
regParam | Param for regularization parameter | 正则化参数,要求≥0 | 0.1 |
maxIter | Param for maximum number of iterations | 训练的最大迭代次数,要求≥0 | 10 |
8、聚类(Clustering)
// 创建SparkSession对象
import org.apache.spark.sql.SparkSession
val spark: SparkSession = SparkSession.builder()
.master("local[*]").appName("a0").getOrCreate()
// 创建数据
val dataset = spark.read.format("libsvm").load(
"D:\\coding\\scala\\lib\\spark-3.0.2\\data\\mllib\\sample_kmeans_data.txt")
dataset.show(false)
/*
+-----+-------------------------+
|label|features |
+-----+-------------------------+
|0.0 |(3,[],[]) |
|1.0 |(3,[0,1,2],[0.1,0.1,0.1])|
|2.0 |(3,[0,1,2],[0.2,0.2,0.2])|
|3.0 |(3,[0,1,2],[9.0,9.0,9.0])|
|4.0 |(3,[0,1,2],[9.1,9.1,9.1])|
|5.0 |(3,[0,1,2],[9.2,9.2,9.2])|
+-----+-------------------------+
*/
// 建模、训练
import org.apache.spark.ml.clustering.KMeans
val kmeans = new KMeans().setK(2)
val model = kmeans.fit(dataset)
// 预测
val predictions = model.transform(dataset)
predictions.show(false)
/*
+-----+-------------------------+----------+
|label|features |prediction|
+-----+-------------------------+----------+
|0.0 |(3,[],[]) |0 |
|1.0 |(3,[0,1,2],[0.1,0.1,0.1])|0 |
|2.0 |(3,[0,1,2],[0.2,0.2,0.2])|0 |
|3.0 |(3,[0,1,2],[9.0,9.0,9.0])|1 |
|4.0 |(3,[0,1,2],[9.1,9.1,9.1])|1 |
|5.0 |(3,[0,1,2],[9.2,9.2,9.2])|1 |
+-----+-------------------------+----------+
*/
// 聚类中心
println("Cluster Centers: ")
model.clusterCenters.foreach(println)
/*
[0.1,0.1,0.1]
[9.1,9.1,9.1]
*/
// 聚类评价:轮廓系数
import org.apache.spark.ml.evaluation.ClusteringEvaluator
val evaluator = new ClusteringEvaluator()
val silhouette = evaluator.evaluate(predictions)
println(s"Silhouette with squared euclidean distance = $silhouette")
/* Silhouette with squared euclidean distance = 0.9997530305375207 */
Appendix
| en | 🔉 | cn |
|---|---|---|
| antecedent | ˌæntɪˈsiːdnt | n. 前情;祖先;(语法)先行词;adj. 先前的;(语法)先行的 |
| consequent | ˈkɑːnsɪkwent | adj. 随之发生的,作为结果的;合乎逻辑的;n. (逻辑)后件,推断;分母 |
| confidence | ˈkɑːnfɪdəns | n. 信心;置信度 |
| lift | lɪft | (价格)上涨;(音量)提高 |
| collaborative | kəˈlæbəreɪtɪv | adj. 合作的,协作的 |
| ALS | Alternating Least Squares | 交替最小二乘法 通过最小化误差的平方和寻找数据的最佳函数匹配 |
| alternate | ˈɔːltərnət | v. (使)交替,(使)轮流 |
| factorization | ˌfæktərəˈzeɪʃən | n. [数] 因子分解;[数] 因式分解 |
| preference | ˈprefrəns | n. 偏爱;优先权 |


















 2578
2578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











