 文本分类与弱监督学习
文本分类与弱监督学习





数据介绍
语料下载地址:https://download.youkuaiyun.com/download/Yellow_python/12862983
新闻10分类样本总数19467,长度分布和类别分布如下:
from data10 import X, Y # 导入文本10分类
from pandas import Series
from collections import Counter
print(Counter(Y).most_common()) # 标签分类统计
print(Series(X).str.len().describe()) # 文本长度概览
| 类别 | 数量 | 类别 | 数量 |
|---|---|---|---|
| science | 2093 | car | 2066 |
| finance | 2052 | sports | 2017 |
| military | 2007 | medicine | 2000 |
| entertainment | 1906 | politics | 1865 |
| education | 1749 | fashion | 1712 |
| 统计指标 | 文本长度 |
|---|---|
| mean | 753.15 |
| std | 538.73 |
| min | 1 |
| 25% | 309 |
| 50% | 645 |
| 75% | 1065 |
| max | 2094 |
原理
极简代码
分类模型:逻辑回归;文本编码:TFIDF
import re, numpy as np
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from jieba import cut
np.random.seed(7)
N = 25000
STOP_WORDS = set('''
了 是 在 和 有 他 我 的 也 为 就 这 都 等 着 来 与 要 又 而 一个 之 以 她 去 那 但 把 我们 可 他们 并 自己 或 由 其 给 使 却
这个 它 已经 及 这样 这些 此 们 这种 如果 因为 即 其中 现在 一些 以及 同时 由于 所以 这里 因 曾 呢 但是 该 每 其他 应 吧 虽然
因此 而且 啊 应该 当时 那么 这么 仍 还有 如此 既 或者 然后 有些 那个 关于 于是 不仅 只要 且 另外 而是 还是 此外 这次 如今 就是
并且 从而 其它 尽管 还要 即使 总是 只有 只是 而言 每次 这是 就会 那是'''.strip().split()) # 情感分析时不用
def tokenizer(text):
for sentence in re.split('[^a-zA-Z\u4e00-\u9fa5]+', text):
for word in cut(sentence):
if word not in STOP_WORDS:
yield word
class Model:
def __init__(self):
self.vec = TfidfVectorizer(tokenizer=tokenizer, max_features=N)
self.clf = LogisticRegression(C=2, solver='liblinear')
def fit(self, x, y):
x = self.vec.fit_transform(x)
self.clf.fit(x, y)
return self
def predict(self, x):
return self.clf.predict(self.vec.transform(x))
def predict_probability_one(self, text):
"""单个文本分类并返回概率"""
proba = self.clf.predict_proba(self.vec.transform([text]))[0]
argmax = np.argmax(proba)
return self.clf.classes_[argmax], proba[argmax]
def classification_report(self, x_test, y_test):
y_pred = self.predict(x_test) # 预测
print('accuracy', np.average([y_test == y_pred]))
print('\033[034m%s\033[0m' % classification_report(y_test, y_pred)) # F1-score
def experiment(x, y, test_size=.9):
# 样本切分,设定测试集占比
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=test_size)
print('\033[033m', test_size, [i.shape for i in (x_train, x_test, y_train, y_test)], '\033[0m', sep='')
# 模型1
m1 = Model().fit(x_train, y_train)
m1.classification_report(x_test, y_test)
for threshold in (.9, .8, .7, .6, .5, .4, .3, .2):
# 高概率预测数据合并到训练集
x_mix, y_mix = x_train.tolist(), y_train.tolist()
for i in range(len(x_test)):
y_pred, proba = m1.predict_probability_one(x_test[i])
if proba > threshold:
x_mix.append(x_test[i])
y_mix.append(y_pred)
print('\033[035m%.1f\033[0m' % threshold, '合并后训练集数量', len(x_mix), len(y_mix))
# 模型2
m2 = Model().fit(x_mix, y_mix)
m2.classification_report(x_test, y_test)
from data10 import X, Y # 文本10分类
experiment(X, Y, test_size=.95)
experiment(X, Y, test_size=.9)
experiment(X, Y, test_size=.8)
experiment(X, Y, test_size=.7)
experiment(X, Y, test_size=.6)
experiment(X, Y, test_size=.5)
experiment(X, Y, test_size=.4)
附两组结果
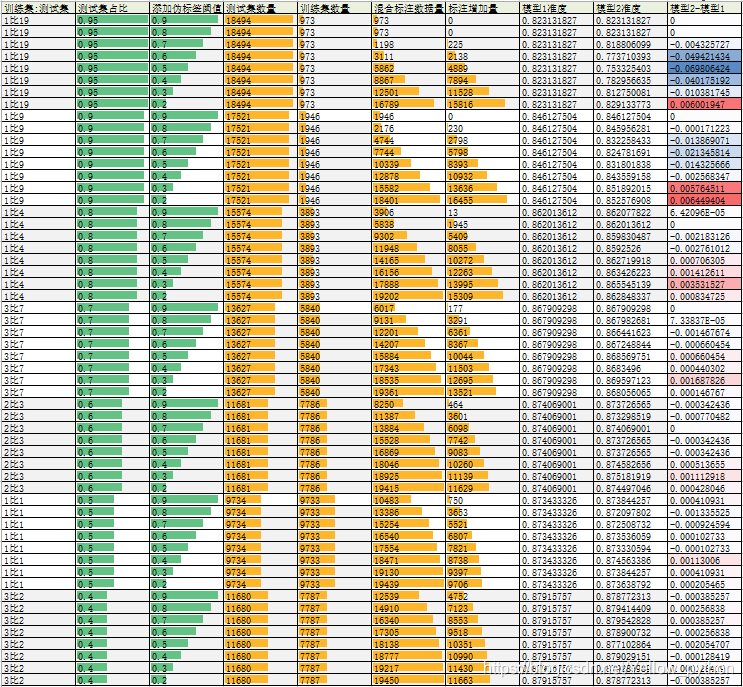
| 训练集:测试集 | 测试集占比 | 添加伪标签阈值 | 测试集数量 | 训练集数量 | 混合标注数据量 | 标注增加量 | 模型1准度 | 模型2准度 | 模型2-模型1 |
|---|---|---|---|---|---|---|---|---|---|
| 1比19 | 0.95 | 0.9 | 18494 | 973 | 973 | 0 | 0.823131827 | 0.823131827 | 0 |
| 1比19 | 0.95 | 0.8 | 18494 | 973 | 973 | 0 | 0.823131827 | 0.823131827 | 0 |
| 1比19 | 0.95 | 0.7 | 18494 | 973 | 1198 | 225 | 0.823131827 | 0.818806099 | -0.004325727 |
| 1比19 | 0.95 | 0.6 | 18494 | 973 | 3111 | 2138 | 0.823131827 | 0.773710393 | -0.049421434 |
| 1比19 | 0.95 | 0.5 | 18494 | 973 | 5862 | 4889 | 0.823131827 | 0.753325403 | -0.069806424 |
| 1比19 | 0.95 | 0.4 | 18494 | 973 | 8867 | 7894 | 0.823131827 | 0.782956635 | -0.040175192 |
| 1比19 | 0.95 | 0.3 | 18494 | 973 | 12501 | 11528 | 0.823131827 | 0.812750081 | -0.010381745 |
| 1比19 | 0.95 | 0.2 | 18494 | 973 | 16789 | 15816 | 0.823131827 | 0.829133773 | 0.006001947 |
| 1比9 | 0.9 | 0.9 | 17521 | 1946 | 1946 | 0 | 0.846127504 | 0.846127504 | 0 |
| 1比9 | 0.9 | 0.8 | 17521 | 1946 | 2176 | 230 | 0.846127504 | 0.845956281 | -0.000171223 |
| 1比9 | 0.9 | 0.7 | 17521 | 1946 | 4744 | 2798 | 0.846127504 | 0.832258433 | -0.013869071 |
| 1比9 | 0.9 | 0.6 | 17521 | 1946 | 7744 | 5798 | 0.846127504 | 0.824781691 | -0.021345814 |
| 1比9 | 0.9 | 0.5 | 17521 | 1946 | 10339 | 8393 | 0.846127504 | 0.831801838 | -0.014325666 |
| 1比9 | 0.9 | 0.4 | 17521 | 1946 | 12878 | 10932 | 0.846127504 | 0.843559158 | -0.002568347 |
| 1比9 | 0.9 | 0.3 | 17521 | 1946 | 15582 | 13636 | 0.846127504 | 0.851892015 | 0.005764511 |
| 1比9 | 0.9 | 0.2 | 17521 | 1946 | 18401 | 16455 | 0.846127504 | 0.852576908 | 0.006449404 |
| 1比4 | 0.8 | 0.9 | 15574 | 3893 | 3906 | 13 | 0.862013612 | 0.862077822 | 6.42096E-05 |
| 1比4 | 0.8 | 0.8 | 15574 | 3893 | 5838 | 1945 | 0.862013612 | 0.862013612 | 0 |
| 1比4 | 0.8 | 0.7 | 15574 | 3893 | 9302 | 5409 | 0.862013612 | 0.859830487 | -0.002183126 |
| 1比4 | 0.8 | 0.6 | 15574 | 3893 | 11948 | 8055 | 0.862013612 | 0.8592526 | -0.002761012 |
| 1比4 | 0.8 | 0.5 | 15574 | 3893 | 14165 | 10272 | 0.862013612 | 0.862719918 | 0.000706305 |
| 1比4 | 0.8 | 0.4 | 15574 | 3893 | 16156 | 12263 | 0.862013612 | 0.863426223 | 0.001412611 |
| 1比4 | 0.8 | 0.3 | 15574 | 3893 | 17888 | 13995 | 0.862013612 | 0.865545139 | 0.003531527 |
| 1比4 | 0.8 | 0.2 | 15574 | 3893 | 19202 | 15309 | 0.862013612 | 0.862848337 | 0.000834725 |
| 3比7 | 0.7 | 0.9 | 13627 | 5840 | 6017 | 177 | 0.867909298 | 0.867909298 | 0 |
| 3比7 | 0.7 | 0.8 | 13627 | 5840 | 9131 | 3291 | 0.867909298 | 0.867982681 | 7.33837E-05 |
| 3比7 | 0.7 | 0.7 | 13627 | 5840 | 12201 | 6361 | 0.867909298 | 0.866441623 | -0.001467674 |
| 3比7 | 0.7 | 0.6 | 13627 | 5840 | 14207 | 8367 | 0.867909298 | 0.867248844 | -0.000660454 |
| 3比7 | 0.7 | 0.5 | 13627 | 5840 | 15884 | 10044 | 0.867909298 | 0.868569751 | 0.000660454 |
| 3比7 | 0.7 | 0.4 | 13627 | 5840 | 17343 | 11503 | 0.867909298 | 0.8683496 | 0.000440302 |
| 3比7 | 0.7 | 0.3 | 13627 | 5840 | 18535 | 12695 | 0.867909298 | 0.869597123 | 0.001687826 |
| 3比7 | 0.7 | 0.2 | 13627 | 5840 | 19361 | 13521 | 0.867909298 | 0.868056065 | 0.000146767 |
| 2比3 | 0.6 | 0.9 | 11681 | 7786 | 8250 | 464 | 0.874069001 | 0.873726565 | -0.000342436 |
| 2比3 | 0.6 | 0.8 | 11681 | 7786 | 11387 | 3601 | 0.874069001 | 0.873298519 | -0.000770482 |
| 2比3 | 0.6 | 0.7 | 11681 | 7786 | 13884 | 6098 | 0.874069001 | 0.874069001 | 0 |
| 2比3 | 0.6 | 0.6 | 11681 | 7786 | 15528 | 7742 | 0.874069001 | 0.873726565 | -0.000342436 |
| 2比3 | 0.6 | 0.5 | 11681 | 7786 | 16869 | 9083 | 0.874069001 | 0.873726565 | -0.000342436 |
| 2比3 | 0.6 | 0.4 | 11681 | 7786 | 18046 | 10260 | 0.874069001 | 0.874582656 | 0.000513655 |
| 2比3 | 0.6 | 0.3 | 11681 | 7786 | 18925 | 11139 | 0.874069001 | 0.875181919 | 0.001112918 |
| 2比3 | 0.6 | 0.2 | 11681 | 7786 | 19415 | 11629 | 0.874069001 | 0.874497046 | 0.000428046 |
| 1比1 | 0.5 | 0.9 | 9734 | 9733 | 10483 | 750 | 0.873433326 | 0.873844257 | 0.000410931 |
| 1比1 | 0.5 | 0.8 | 9734 | 9733 | 13386 | 3653 | 0.873433326 | 0.872097802 | -0.001335525 |
| 1比1 | 0.5 | 0.7 | 9734 | 9733 | 15254 | 5521 | 0.873433326 | 0.872508732 | -0.000924594 |
| 1比1 | 0.5 | 0.6 | 9734 | 9733 | 16540 | 6807 | 0.873433326 | 0.873536059 | 0.000102733 |
| 1比1 | 0.5 | 0.5 | 9734 | 9733 | 17554 | 7821 | 0.873433326 | 0.873330594 | -0.000102733 |
| 1比1 | 0.5 | 0.4 | 9734 | 9733 | 18471 | 8738 | 0.873433326 | 0.874563386 | 0.00113006 |
| 1比1 | 0.5 | 0.3 | 9734 | 9733 | 19130 | 9397 | 0.873433326 | 0.873844257 | 0.000410931 |
| 1比1 | 0.5 | 0.2 | 9734 | 9733 | 19439 | 9706 | 0.873433326 | 0.873638792 | 0.000205465 |
| 3比2 | 0.4 | 0.9 | 11680 | 7787 | 12539 | 4752 | 0.87915757 | 0.878772313 | -0.000385257 |
| 3比2 | 0.4 | 0.8 | 11680 | 7787 | 14910 | 7123 | 0.87915757 | 0.879414409 | 0.000256838 |
| 3比2 | 0.4 | 0.7 | 11680 | 7787 | 16340 | 8553 | 0.87915757 | 0.879542828 | 0.000385257 |
| 3比2 | 0.4 | 0.6 | 11680 | 7787 | 17305 | 9518 | 0.87915757 | 0.878900732 | -0.000256838 |
| 3比2 | 0.4 | 0.5 | 11680 | 7787 | 18138 | 10351 | 0.87915757 | 0.877102864 | -0.002054707 |
| 3比2 | 0.4 | 0.4 | 11680 | 7787 | 18777 | 10990 | 0.87915757 | 0.879029151 | -0.000128419 |
| 3比2 | 0.4 | 0.3 | 11680 | 7787 | 19217 | 11430 | 0.87915757 | 0.879285989 | 0.000128419 |
| 3比2 | 0.4 | 0.2 | 11680 | 7787 | 19450 | 11663 | 0.87915757 | 0.878772313 | -0.000385257 |
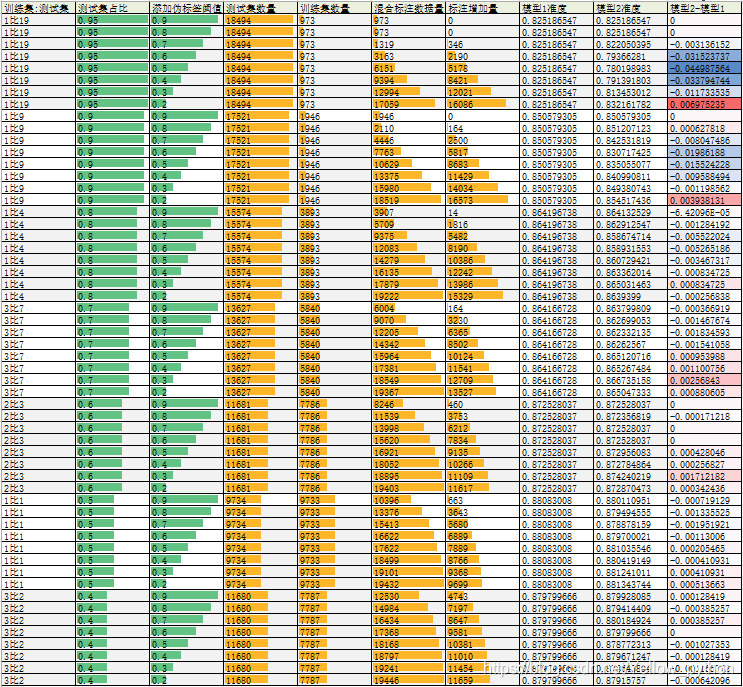
| 训练集:测试集 | 测试集占比 | 添加伪标签阈值 | 测试集数量 | 训练集数量 | 混合标注数据量 | 标注增加量 | 模型1准度 | 模型2准度 | 模型2-模型1 |
|---|---|---|---|---|---|---|---|---|---|
| 1比19 | 0.95 | 0.9 | 18494 | 973 | 973 | 0 | 0.825186547 | 0.825186547 | 0 |
| 1比19 | 0.95 | 0.8 | 18494 | 973 | 973 | 0 | 0.825186547 | 0.825186547 | 0 |
| 1比19 | 0.95 | 0.7 | 18494 | 973 | 1319 | 346 | 0.825186547 | 0.822050395 | -0.003136152 |
| 1比19 | 0.95 | 0.6 | 18494 | 973 | 3163 | 2190 | 0.825186547 | 0.79366281 | -0.031523737 |
| 1比19 | 0.95 | 0.5 | 18494 | 973 | 6151 | 5178 | 0.825186547 | 0.780198983 | -0.044987564 |
| 1比19 | 0.95 | 0.4 | 18494 | 973 | 9394 | 8421 | 0.825186547 | 0.791391803 | -0.033794744 |
| 1比19 | 0.95 | 0.3 | 18494 | 973 | 12994 | 12021 | 0.825186547 | 0.813453012 | -0.011733535 |
| 1比19 | 0.95 | 0.2 | 18494 | 973 | 17059 | 16086 | 0.825186547 | 0.832161782 | 0.006975235 |
| 1比9 | 0.9 | 0.9 | 17521 | 1946 | 1946 | 0 | 0.850579305 | 0.850579305 | 0 |
| 1比9 | 0.9 | 0.8 | 17521 | 1946 | 2110 | 164 | 0.850579305 | 0.851207123 | 0.000627818 |
| 1比9 | 0.9 | 0.7 | 17521 | 1946 | 4446 | 2500 | 0.850579305 | 0.842531819 | -0.008047486 |
| 1比9 | 0.9 | 0.6 | 17521 | 1946 | 7763 | 5817 | 0.850579305 | 0.830717425 | -0.01986188 |
| 1比9 | 0.9 | 0.5 | 17521 | 1946 | 10629 | 8683 | 0.850579305 | 0.835055077 | -0.015524228 |
| 1比9 | 0.9 | 0.4 | 17521 | 1946 | 13375 | 11429 | 0.850579305 | 0.840990811 | -0.009588494 |
| 1比9 | 0.9 | 0.3 | 17521 | 1946 | 15980 | 14034 | 0.850579305 | 0.849380743 | -0.001198562 |
| 1比9 | 0.9 | 0.2 | 17521 | 1946 | 18519 | 16573 | 0.850579305 | 0.854517436 | 0.003938131 |
| 1比4 | 0.8 | 0.9 | 15574 | 3893 | 3907 | 14 | 0.864196738 | 0.864132529 | -6.42096E-05 |
| 1比4 | 0.8 | 0.8 | 15574 | 3893 | 5709 | 1816 | 0.864196738 | 0.862912547 | -0.001284192 |
| 1比4 | 0.8 | 0.7 | 15574 | 3893 | 9375 | 5482 | 0.864196738 | 0.858674714 | -0.005522024 |
| 1比4 | 0.8 | 0.6 | 15574 | 3893 | 12083 | 8190 | 0.864196738 | 0.858931553 | -0.005265186 |
| 1比4 | 0.8 | 0.5 | 15574 | 3893 | 14279 | 10386 | 0.864196738 | 0.860729421 | -0.003467317 |
| 1比4 | 0.8 | 0.4 | 15574 | 3893 | 16135 | 12242 | 0.864196738 | 0.863362014 | -0.000834725 |
| 1比4 | 0.8 | 0.3 | 15574 | 3893 | 17879 | 13986 | 0.864196738 | 0.865031463 | 0.000834725 |
| 1比4 | 0.8 | 0.2 | 15574 | 3893 | 19222 | 15329 | 0.864196738 | 0.8639399 | -0.000256838 |
| 3比7 | 0.7 | 0.9 | 13627 | 5840 | 6004 | 164 | 0.864166728 | 0.863799809 | -0.000366919 |
| 3比7 | 0.7 | 0.8 | 13627 | 5840 | 9070 | 3230 | 0.864166728 | 0.862699053 | -0.001467674 |
| 3比7 | 0.7 | 0.7 | 13627 | 5840 | 12205 | 6365 | 0.864166728 | 0.862332135 | -0.001834593 |
| 3比7 | 0.7 | 0.6 | 13627 | 5840 | 14342 | 8502 | 0.864166728 | 0.86262567 | -0.001541058 |
| 3比7 | 0.7 | 0.5 | 13627 | 5840 | 15964 | 10124 | 0.864166728 | 0.865120716 | 0.000953988 |
| 3比7 | 0.7 | 0.4 | 13627 | 5840 | 17381 | 11541 | 0.864166728 | 0.865267484 | 0.001100756 |
| 3比7 | 0.7 | 0.3 | 13627 | 5840 | 18549 | 12709 | 0.864166728 | 0.866735158 | 0.00256843 |
| 3比7 | 0.7 | 0.2 | 13627 | 5840 | 19367 | 13527 | 0.864166728 | 0.865047333 | 0.000880605 |
| 2比3 | 0.6 | 0.9 | 11681 | 7786 | 8246 | 460 | 0.872528037 | 0.872528037 | 0 |
| 2比3 | 0.6 | 0.8 | 11681 | 7786 | 11539 | 3753 | 0.872528037 | 0.872356819 | -0.000171218 |
| 2比3 | 0.6 | 0.7 | 11681 | 7786 | 13998 | 6212 | 0.872528037 | 0.872528037 | 0 |
| 2比3 | 0.6 | 0.6 | 11681 | 7786 | 15620 | 7834 | 0.872528037 | 0.872528037 | 0 |
| 2比3 | 0.6 | 0.5 | 11681 | 7786 | 16921 | 9135 | 0.872528037 | 0.872956083 | 0.000428046 |
| 2比3 | 0.6 | 0.4 | 11681 | 7786 | 18052 | 10266 | 0.872528037 | 0.872784864 | 0.000256827 |
| 2比3 | 0.6 | 0.3 | 11681 | 7786 | 18895 | 11109 | 0.872528037 | 0.874240219 | 0.001712182 |
| 2比3 | 0.6 | 0.2 | 11681 | 7786 | 19403 | 11617 | 0.872528037 | 0.872870473 | 0.000342436 |
| 1比1 | 0.5 | 0.9 | 9734 | 9733 | 10396 | 663 | 0.88083008 | 0.880110951 | -0.000719129 |
| 1比1 | 0.5 | 0.8 | 9734 | 9733 | 13376 | 3643 | 0.88083008 | 0.879494555 | -0.001335525 |
| 1比1 | 0.5 | 0.7 | 9734 | 9733 | 15413 | 5680 | 0.88083008 | 0.878878159 | -0.001951921 |
| 1比1 | 0.5 | 0.6 | 9734 | 9733 | 16622 | 6889 | 0.88083008 | 0.879700021 | -0.00113006 |
| 1比1 | 0.5 | 0.5 | 9734 | 9733 | 17622 | 7889 | 0.88083008 | 0.881035546 | 0.000205465 |
| 1比1 | 0.5 | 0.4 | 9734 | 9733 | 18499 | 8766 | 0.88083008 | 0.880419149 | -0.000410931 |
| 1比1 | 0.5 | 0.3 | 9734 | 9733 | 19101 | 9368 | 0.88083008 | 0.881241011 | 0.000410931 |
| 1比1 | 0.5 | 0.2 | 9734 | 9733 | 19432 | 9699 | 0.88083008 | 0.881343744 | 0.000513663 |
| 3比2 | 0.4 | 0.9 | 11680 | 7787 | 12530 | 4743 | 0.879799666 | 0.879928085 | 0.000128419 |
| 3比2 | 0.4 | 0.8 | 11680 | 7787 | 14984 | 7197 | 0.879799666 | 0.879414409 | -0.000385257 |
| 3比2 | 0.4 | 0.7 | 11680 | 7787 | 16434 | 8647 | 0.879799666 | 0.880184924 | 0.000385257 |
| 3比2 | 0.4 | 0.6 | 11680 | 7787 | 17368 | 9581 | 0.879799666 | 0.879799666 | 0 |
| 3比2 | 0.4 | 0.5 | 11680 | 7787 | 18168 | 10381 | 0.879799666 | 0.878772313 | -0.001027353 |
| 3比2 | 0.4 | 0.4 | 11680 | 7787 | 18797 | 11010 | 0.879799666 | 0.879671247 | -0.000128419 |
| 3比2 | 0.4 | 0.3 | 11680 | 7787 | 19241 | 11454 | 0.879799666 | 0.878643894 | -0.001155772 |
| 3比2 | 0.4 | 0.2 | 11680 | 7787 | 19446 | 11659 | 0.879799666 | 0.87915757 | -0.000642096 |
结论
多数情况不提升,某些情况下有轻微提升,有空再做更多微调


















 25
25





 到【灌水乐园】发言
到【灌水乐园】发言









