









大家好,欢迎来到《算法入门》系列。今天我们要聊的是机器学习中最基础、最经典的算法之一——线性回归。如果你是刚入门的朋友,不用担心,我们将用最简单、最通俗的语言带你从零开始理解它。既然是“入门”,那我们就从最基础的概念讲起。
1. 线性回归是什么?
线性回归,顾名思义,就是通过“线性”的方式来拟合数据,并找出自变量与因变量之间的关系。简单来说,线性回归的目标就是用一条直线来预测结果。
假设你有一组数据,想要预测某个变量(例如:房价)与其他变量(例如:房屋面积、卧室数量等)之间的关系。那么,线性回归就能帮助你建立这种关系,并通过一个公式来预测未来的结果。
举个例子
假设你是一个房地产公司老板,你有以下数据:
| 房屋面积 (平方米) | 房价 (万元) |
|---|---|
| 50 | 80 |
| 60 | 100 |
| 70 | 120 |
| 80 | 140 |
你可以看到,随着房屋面积的增加,房价也逐渐增加。线性回归的任务就是找出一个公式,预测在给定面积下,房价大概是多少。
2. 线性回归的数学模型
线性回归的核心思想是:假设输入变量(特征)与输出变量(目标)之间存在线性关系。我们可以用以下简单的公式来表示:
y
=
β
0
+
β
1
⋅
x
y = \beta0 + \beta1 \cdot x
y=β0+β1⋅x
其中:
- y:预测值(例如房价)
- x:输入特征(例如房屋面积)
- β₀:截距(也就是直线与y轴的交点)
- β₁:斜率(表示房屋面积每增加一平方米,房价增加的数量)
我们的目标就是通过数据,找到最适合的 β₀ 和 β₁。这就相当于在图上画一条直线,让这条直线最准确地通过所有数据点(或者至少离数据点最近)。
3. 如何训练线性回归模型?
3.1 最小二乘法
线性回归的训练过程实际上就是在找最合适的 β₀ 和 β₁。我们希望通过最小化一个叫做“损失函数”的东西来做到这一点。最常见的损失函数是均方误差 (MSE),也就是每个预测值与真实值之间差距的平方和,再取平均。
损失函数的公式如下:
M
S
E
=
1
n
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
MSE = \frac{1}{n} \sum{i=1}^{n} (yi - \hat{y}_i)^2
MSE=n1∑i=1n(yi−y^i)2
其中:
- y i y_i yi 是真实值
- y ^ i \hat{y}_i y^i 是预测值
- n n n 是样本数量
我们的目标是通过调整 β₀ 和 β₁ 的值,使得损失函数的值最小。直观上看,就是要让预测值尽可能接近真实值。
3.2 训练过程
训练过程的核心步骤是通过梯度下降法来优化参数。这是一个不断调整参数的过程。每次调整的方向都与当前误差的梯度有关,直到找到使得损失函数最小的参数。
4. 线性回归建模操作示例
4.1 使用上述数学实例建模
好,我们了解了线性回归的基本原理。接下来我们用 Python 实际操作一下,看看如何用线性回归来预测房价。
首先,我们需要导入一些必要的库:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
接着,我们准备一下数据:
# 房屋面积 (平方米)
X = np.array([[50], [60], [70], [80]])
# 房价 (万元)
y = np.array([80, 100, 120, 140])
然后,我们创建一个线性回归模型,并进行训练:
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X, y)
现在,我们可以查看模型的参数(β₀ 和 β₁):
# 截距(β₀)
print("截距 β₀:", model.intercept_)
# 斜率(β₁)
print("斜率 β₁:", model.coef_)
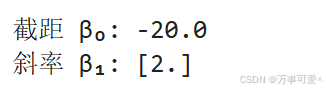
模型训练完成后,我们可以用它来进行预测:
# 预测房价
predictions = model.predict(X)
# 打印预测值
print("预测房价:", predictions)

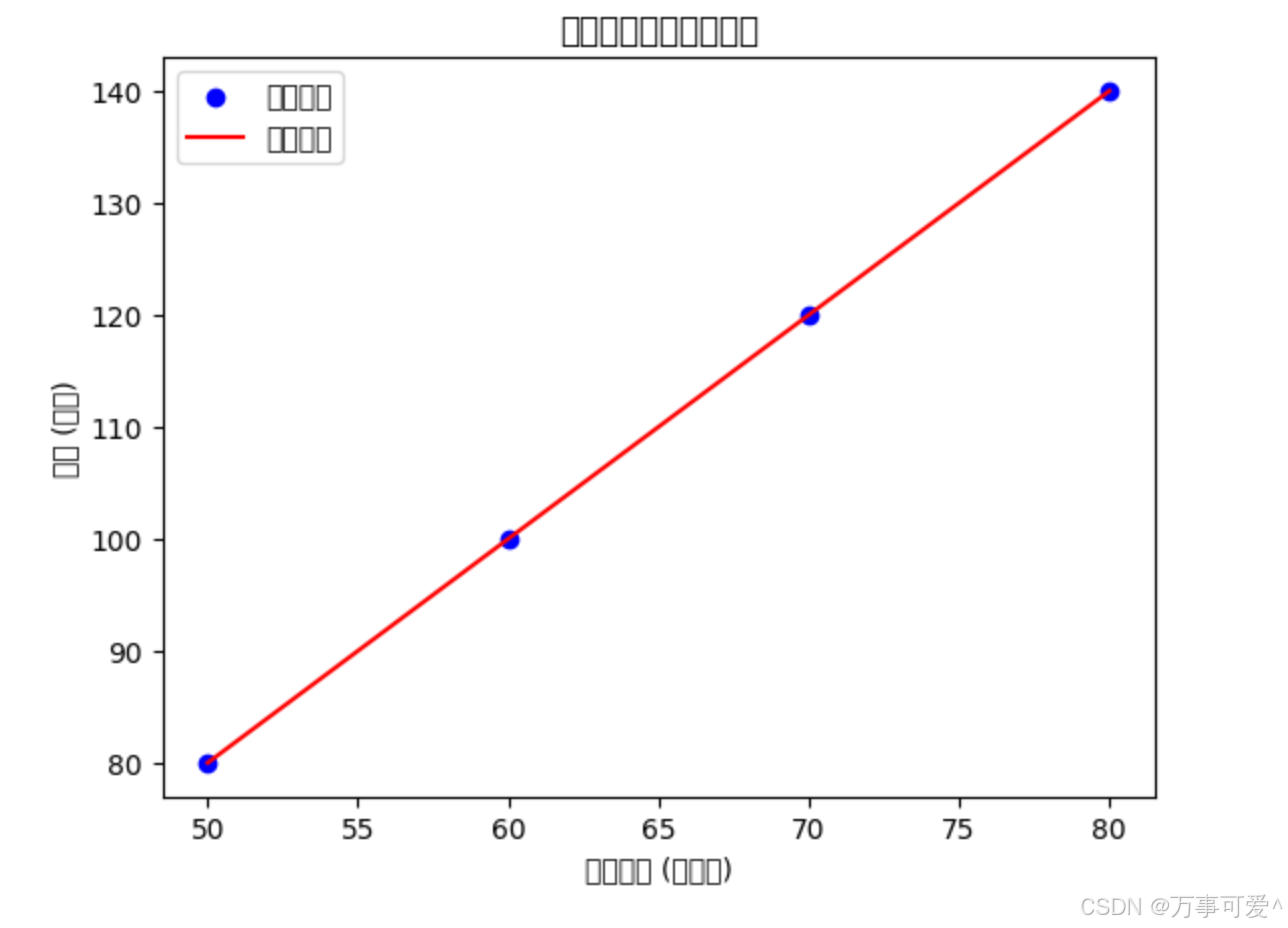
为了更直观地理解模型效果,我们可以绘制数据点和拟合的直线:
# 绘制数据点
plt.scatter(X, y, color='blue', label='实际数据')
# 绘制拟合直线
plt.plot(X, predictions, color='red', label='拟合直线')
# 添加标签
plt.xlabel('房屋面积 (平方米)')
plt.ylabel('房价 (万元)')
plt.title('房屋面积与房价的关系')
# 显示图例
plt.legend()
# 显示图形
plt.show()
运行这段代码后,你将看到和下面一样的一张图,图中包含了数据点(蓝色)和拟合的直线(红色)。这个直线就是你用线性回归模型预测房价的结果。
4.2 使用Kaggle数据集进行实践
为了具体演示如何应用线性回归,我们将使用一个来自 Kaggle 的数据集。使用波士顿房价数据集(Boston Housing Dataset),来帮助你理解线性回归的原理与应用。
4.2.1 波士顿房价数据集概述
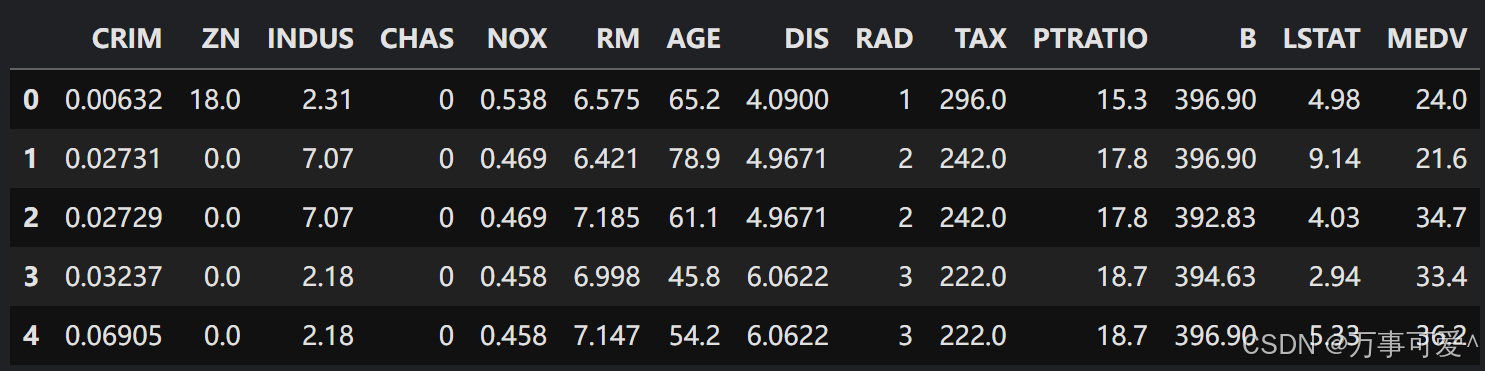
波士顿房价数据集包含了506个房屋信息,每条记录描述了一个区域的各类统计特征,包括犯罪率、房间数量、房屋年龄等,目标变量是房价的中位数(MEDV)。数据集中的特征包括:
- CRIM:该地区的犯罪率(每万人的犯罪数量)
- ZN:住宅用地的比例(大于25,000平方英尺的住宅用地比例)
- INDUS:非零售商业用地的比例
- CHAS:是否位于查尔斯河旁边(1=是,0=否)
- NOX:氮氧化物浓度(ppm)
- RM:每个住宅的平均房间数
- AGE:1940年之前建成的房屋的比例
- DIS:到波士顿五个就业中心的加权距离
- RAD:辐射性公路的可达性指数
- TAX:财产税率
- PTRATIO:学生与教师的比例
- B:表示黑人的比例,按公式 (B = 1000(Bk - 0.63)^2) 计算
- LSTAT:低社会经济状态的人口比例
- MEDV:房屋的中位数价格(目标变量)
我们的目标是找到一个最优的权重,使得通过这些权重计算出的预测值尽可能接近真实的房价。
4.2.1 数据预处理
在进行线性回归建模之前,我们首先需要对数据进行一些预处理。以下是对波士顿数据集的一些基本操作:
导入所需库并加载数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 加载波士顿房价数据集
df = pd.read_csv('/kaggle/input/the-boston-houseprice-data/boston.csv')
df.head()
输出结果如下所示:
4.2.2 数据分析与可视化
了解数据的分布情况和相关性是建模过程中的重要一步。可以通过散点图、热力图等可视化工具帮助分析数据特征与目标变量之间的关系。
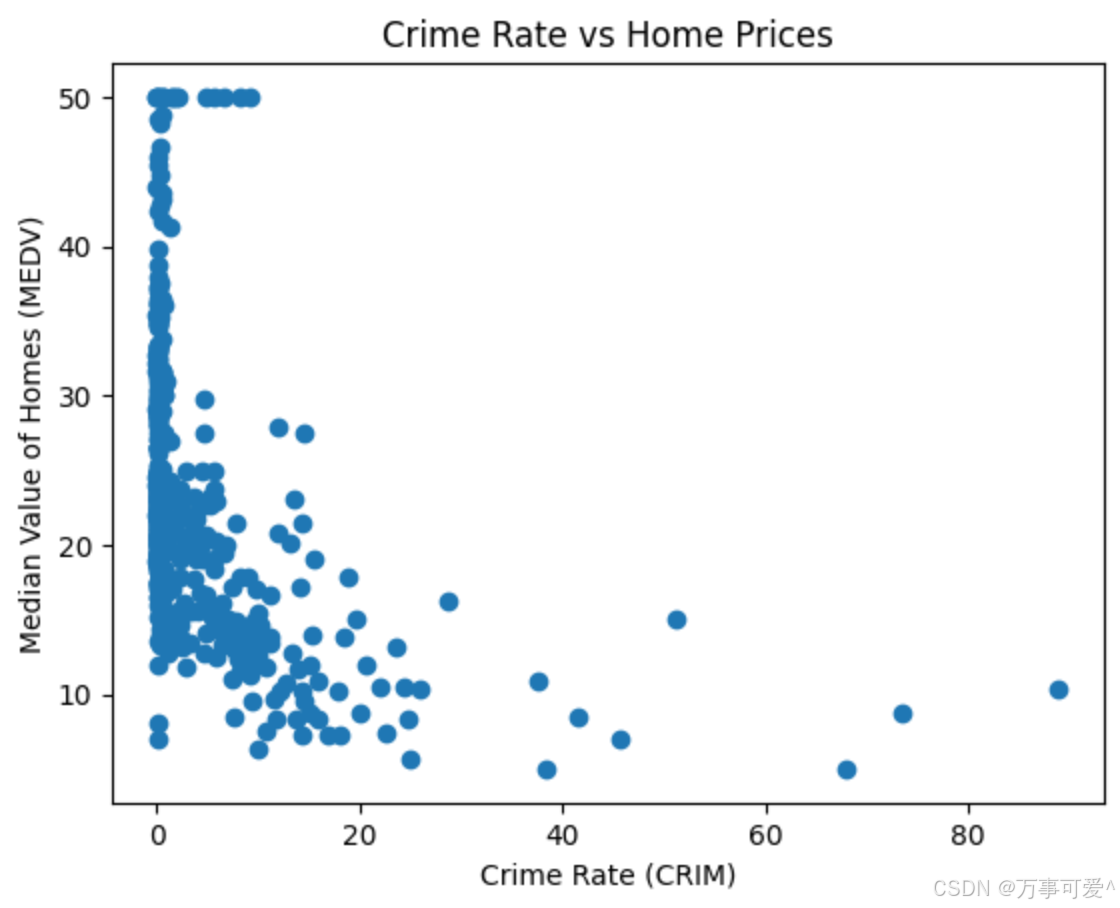
# 可视化CRIM与MEDV的关系
plt.scatter(df['CRIM'], df['MEDV'])
plt.xlabel('Crime Rate (CRIM)')
plt.ylabel('Median Value of Homes (MEDV)')
plt.title('Crime Rate vs Home Prices')
plt.show()
# 相关性矩阵
corr_matrix = df.corr()
import seaborn as sns
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.show()
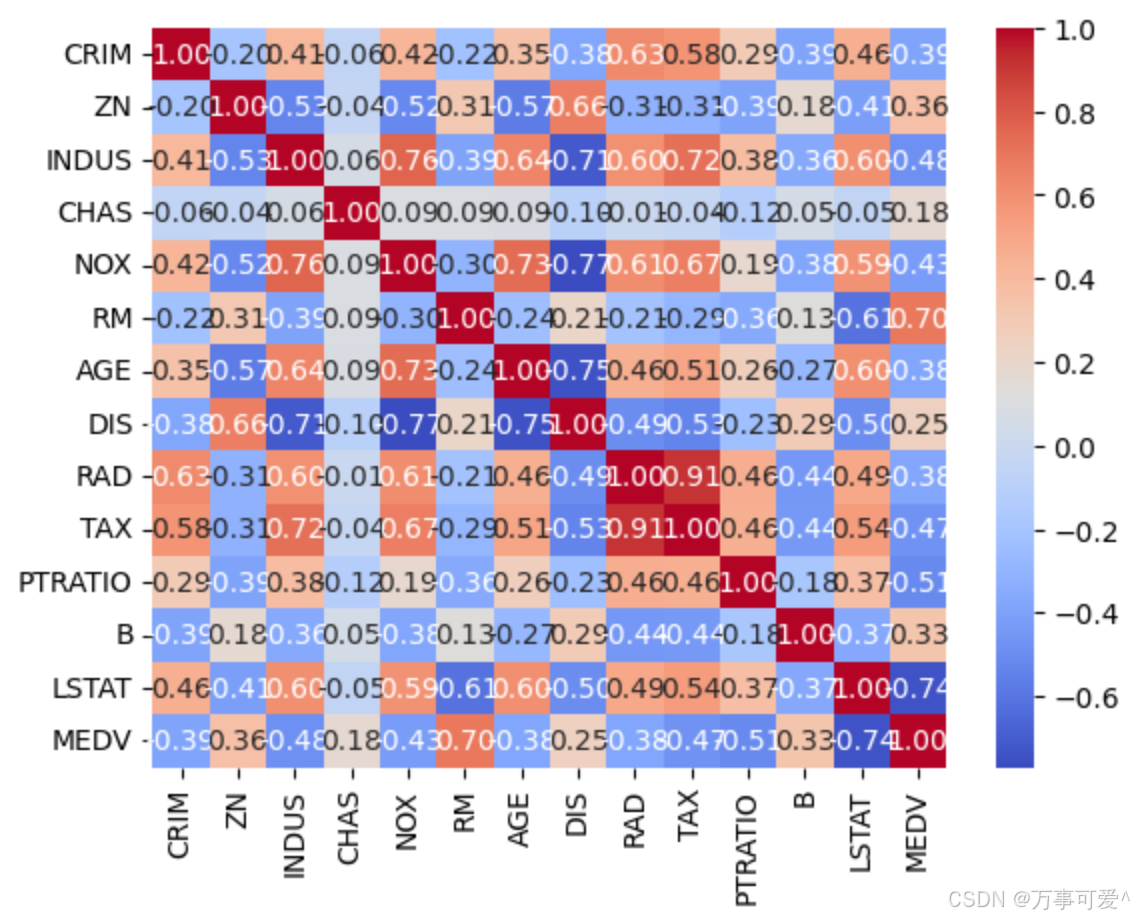
4.2.3 数据分割
我们将数据集分为训练集和测试集,用于模型训练和验证。
# 特征与目标变量
X = df.drop('MEDV', axis=1)
y = df['MEDV']
# 分割数据集(80% 训练集,20% 测试集)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
这里的random_state=42是设置随机种子,如果你和我设置成一样,就可以得到完全一样的结果。
4.2.4 训练线性回归模型
使用Scikit-learn的LinearRegression类,我们可以非常简单地训练一个线性回归模型:
# 创建线性回归模型
model = LinearRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 输出模型的截距和回归系数
print('截距 (Intercept):', model.intercept_)
print('回归系数 (Coefficients):', model.coef_)

4.2.5 模型评估
训练完成后,我们可以在测试集上进行预测,并评估模型的性能。常用的回归模型评估指标包括均方误差(MSE)和决定系数(R²)。
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算均方误差(MSE)和决定系数(R²)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'均方误差 (MSE): {mse}')
print(f'决定系数 (R²): {r2}')

可以看到效果并不是太好,不过这里只做演示使用,后续讲到模型优化部分,我在教大家如何优化当前模型。
4.2.6 可视化回归结果
我们还可以通过可视化预测结果来观察模型的拟合情况:
import matplotlib.pyplot as plt
# 设置画布的大小
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, c='steelblue', label='数据点', alpha=0.7)
# 添加对角线(表示理想情况下的预测)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'r--', label='理想线')
plt.xlabel('真实值 (True Values)', fontsize=14, color='darkgreen')
plt.ylabel('预测值 (Predictions)', fontsize=14, color='darkgreen')
plt.title('True vs Predicted Home Prices', fontsize=16, fontweight='bold', color='navy')
# 设置轴刻度标签的字体大小和颜色
plt.tick_params(axis='both', which='major', labelsize=12, colors='gray')
# 设置图例的位置和字体大小
plt.legend(loc='upper left', fontsize=12)
plt.show()
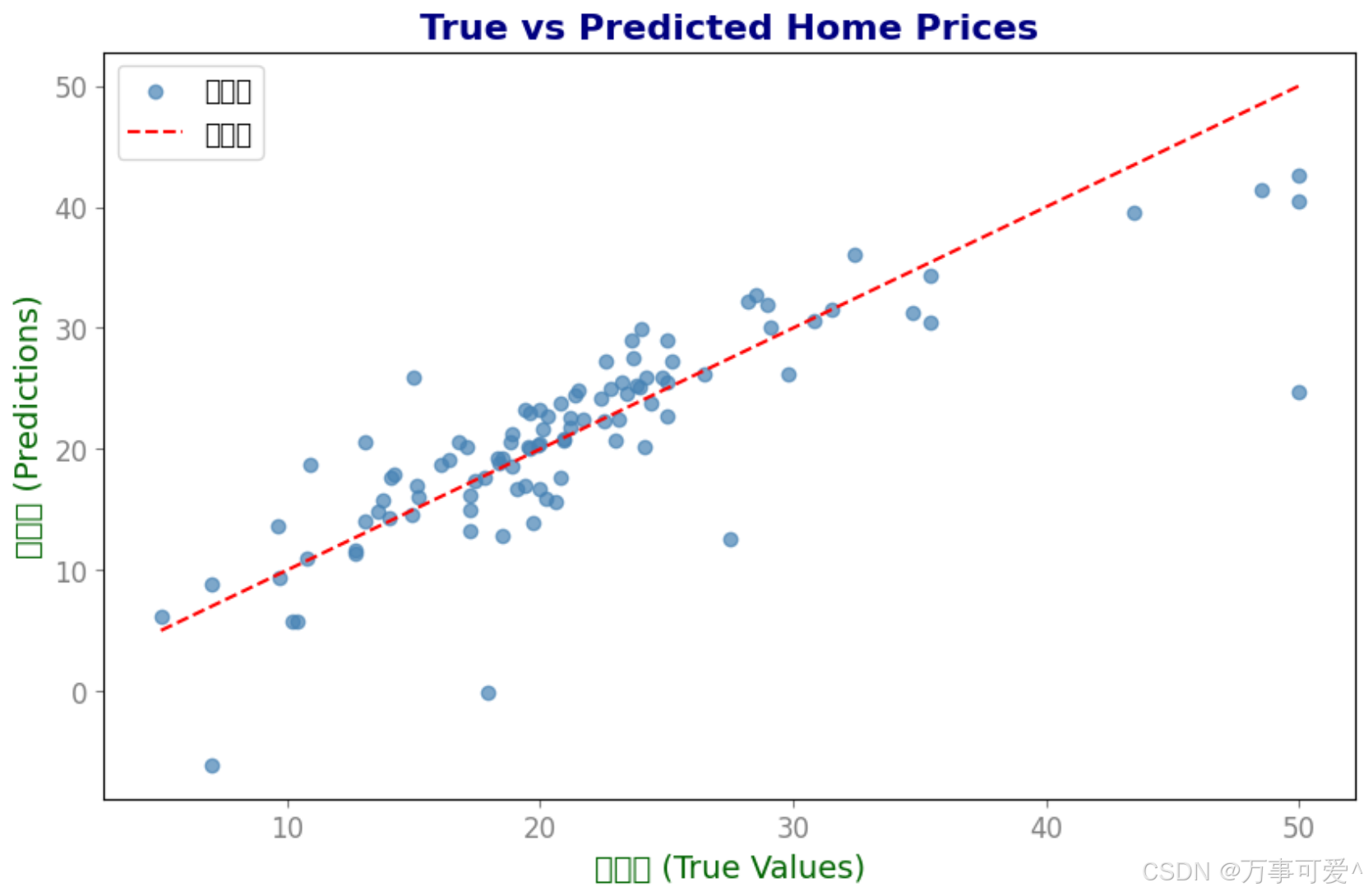
这张图会显示测试集中的实际房价与预测房价的对比。红色虚线表示完美预测的情况,即预测值与实际值完全一致。
5.总结
回顾一下上述所学到的内容:
- 线性回归是通过找一条直线来拟合数据,进而预测结果。
- 线性回归的核心是找到合适的 β₀ 和 β₁,让预测值尽量接近真实值。
- 训练模型的过程中,我们通过最小二乘法来最小化损失函数。
- 使用 Python 和 sklearn 库,我们可以快速实现线性回归并进行预测。
- 线性回归是一种基于输入特征和目标变量之间线性关系的回归模型。 数据的准备和清洗是模型训练的第一步。
- 训练模型后,通过评估指标(如MSE和R²)来判断模型的性能。
- 可视化实际值与预测值的对比有助于更直观地了解模型效果。
线性回归虽然简单,但它是机器学习的基础,为更复杂的模型打下了坚实的基础。希望你能通过今天的学习,对线性回归有一个清晰的理解。如果你对这个算法有任何问题,随时可以问我哦!
好了到了这里各位道友就开始正式迈入金丹期了,预祝各位道友丹途坦荡。
下次我们将继续探索其他机器学习算法,敬请期待!
数据集地址:https://www.kaggle.com/datasets/fedesoriano/the-boston-houseprice-data

















 1969
1969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









