







Anomaly Detection with partially Observed Anomalies论文笔记
标签(空格分隔): 异常检测
一、 通过比较引出论文提出的方法
- PU(positive and Unlabled)learning
如果我们把异常视为这里的Positive Sample,那么PU learning这一概念就会和本论文中将要介绍的Anomaly Detection with partially Observed Anomalies有些相似了,不过二者最显著的区别是,在PU Learining中,Positive Samples之间是相似的,而在异常检测当中,异常与异常并不一定满足一定的模式。 - semi-supervised clustering
有了部分标记的信息,目的是尝试将未标记的样本分配到适当的集群。
二者共同存在的问题
我们不能说两个异常值之间的差异比一个异常值和一个非异常值之间的差异小。
二、本文方法ADOA(Anomaly Detection with partial Observed Anomalies)
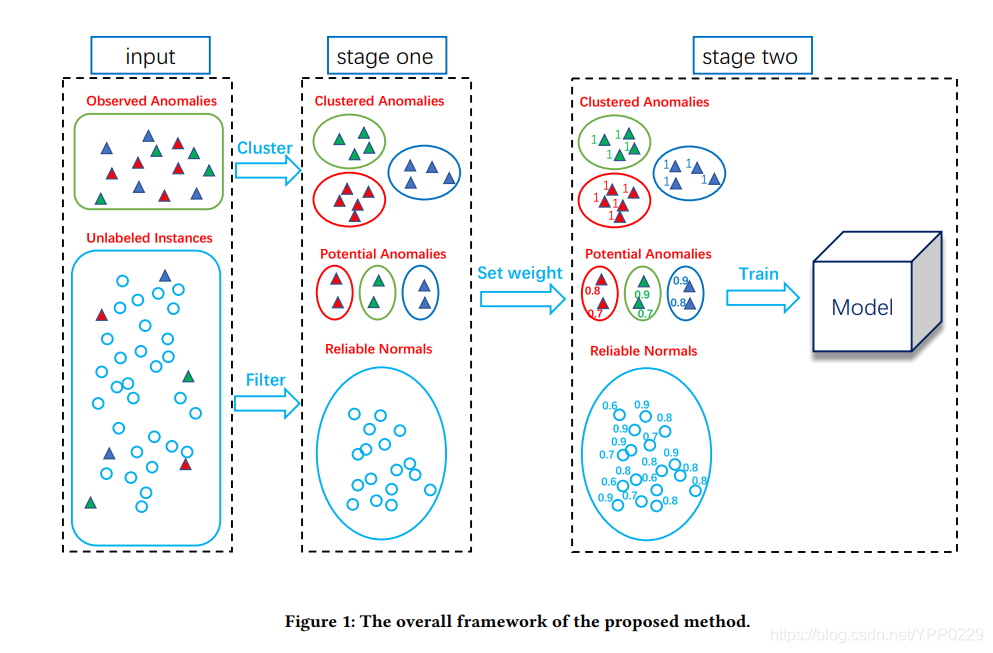
该算法主要有两个阶段:
- 首先,通过处理异常之间的差异,对观测到的异常进行聚类,对未标记的实例进行过滤,得到潜在的异常和可靠的正常实例
- 然后,利用上述实例,根据每个实例的标签置信度,为每个实例附加一个权重,并建立一个加权的多类模型,进一步将不同的异常与正常实例区分开来
实验结果表明,在上述情况下,现有方法的性能较差,所提方法的性能明显优于所有方法,验证了所提方法的有效性
In Stage One
- 应用聚类算法,对数据集中已知的异常点进行聚类,(可根据自己的需要选取聚类算法,本论文中选取的是K-means均值聚类)
- 通过Isolation Score 和 Similarity Score,将数据集中剩下的未标记的数据,划分为Potential Anomalies 和Reliable Normals.
Isolation Score(IS)
得出的是一个样本为异常值的分数
Similarity Score(SS)
计算的是一个样本和它最近的一个异常中心的距离
Total Score
take both the isolation score and the similarity score into consideration . T S ( x ) = θ I S ( x ) + ( 1 − θ ) S S ( x ) TS(x) = θIS(x) + (1 − θ)SS(x) TS(x)=θIS(x)+(1−θ)SS(x)
θ \theta θ 是[0,1]之间的值
α = 1 l ∑ i = 1 l T S ( x i ) \alpha = \frac{1}{l}\sum_{i=1}^{l}TS(x_i) α=l1i=1∑lTS(xi)
T S ( x ) > α TS(x)>\alpha TS(x)>α,就将x这个样本视为潜在的异常值,并把它放到最近的异常簇里
T S ( x ) < α TS(x)<\alpha TS(x)<α,就将x这个样本视为正常值
In Stage Two
给所有样本和所有已知的异常点设置权重值, 所有已知为异常点的权重设置为 1, 样本的权重值可由下面的公式计算得出
w
(
x
)
=
T
S
(
x
)
m
a
x
x
T
S
(
x
)
w(x)=\frac{TS(x)}{max_{x}TS(x)}
w(x)=maxxTS(x)TS(x)
TS分数越高,这个样本被赋予的权重值越大
K+1-class Model
每一个异常簇都被视为是一个类别,所以我们可以说在数据集中一共有K+1个类别,分别是K个异常簇,一个Nomal class,所以我们的目标函数,可以定义如下:
∑
i
w
i
l
(
y
i
,
f
(
x
i
)
)
+
λ
R
(
w
)
\sum_iw_il(y_i,f(x_i))+\lambda R(w)
i∑wil(yi,f(xi))+λR(w)
l
(
y
i
,
f
(
x
i
)
)
l(y_i,f(x_i))
l(yi,f(xi))是损失项,
R
(
w
)
R(w)
R(w)是正则化项



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









