



 本文介绍了一种使用Python的requests库和os库爬取王者荣耀英雄及其皮肤高清图片的方法。通过获取英雄列表json文件,解析英雄名称和编号,进而下载对应图片。提供了两种实现方式,一种是直接使用requests进行下载,另一种是设置代理服务器防止被封禁。
本文介绍了一种使用Python的requests库和os库爬取王者荣耀英雄及其皮肤高清图片的方法。通过获取英雄列表json文件,解析英雄名称和编号,进而下载对应图片。提供了两种实现方式,一种是直接使用requests进行下载,另一种是设置代理服务器防止被封禁。
利用requests库和os库,大概30行代码,就能把页面上的图片给爬取下来!
打开百度搜索“王者荣耀”进入官网:https://pvp.qq.com/,按F12进入调试界面,然后按F5刷新界面,图中标识的herolist.json文件就是我们所需要的英雄列表,其中包括英雄编号、英雄名称、英雄类型、皮肤的名称等信息,在文件上右击复制链接http://pvp.qq.com/web201605/js/herolist.json
还说这么多干什么嘞,直接上代码
代码如下所示:
(方法一)
# -*- coding: utf-8 -*-
"""
__title__ = '爬取王者荣耀英雄及皮肤高清图片'
__author__ = '张佑'
__mtime__ = '2020/04/06'
# code is far away from bugs with the god animal protecting
I love animals. They taste delicious.
┏┓ ┏┓
┏┛┻━━━┛┻┓
┃ ☃ ┃
┃ ┳┛ ┗┳ ┃
┃ ┻ ┃
┗━┓ ┏━┛
┃ ┗━━━┓
┃ 神兽保佑 ┣┓
┃ 永无BUG! ┏┛
┗┓┓┏━┳┓┏┛
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛
"""
import os
import requests
#获取所有英雄列表json文件
url = 'https://pvp.qq.com/web201605/js/herolist.json'
herolist = requests.get(url) # 获取英雄列表json文件
herolist_json = herolist.json() # 转化为json格式
hero_name = list(map(lambda x: x['cname'], herolist.json())) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'], herolist.json())) # 提取英雄的编号
# 下载壁纸图片
def downloadHeroPic():
i = 0
for j in hero_number:
# 创建文件夹
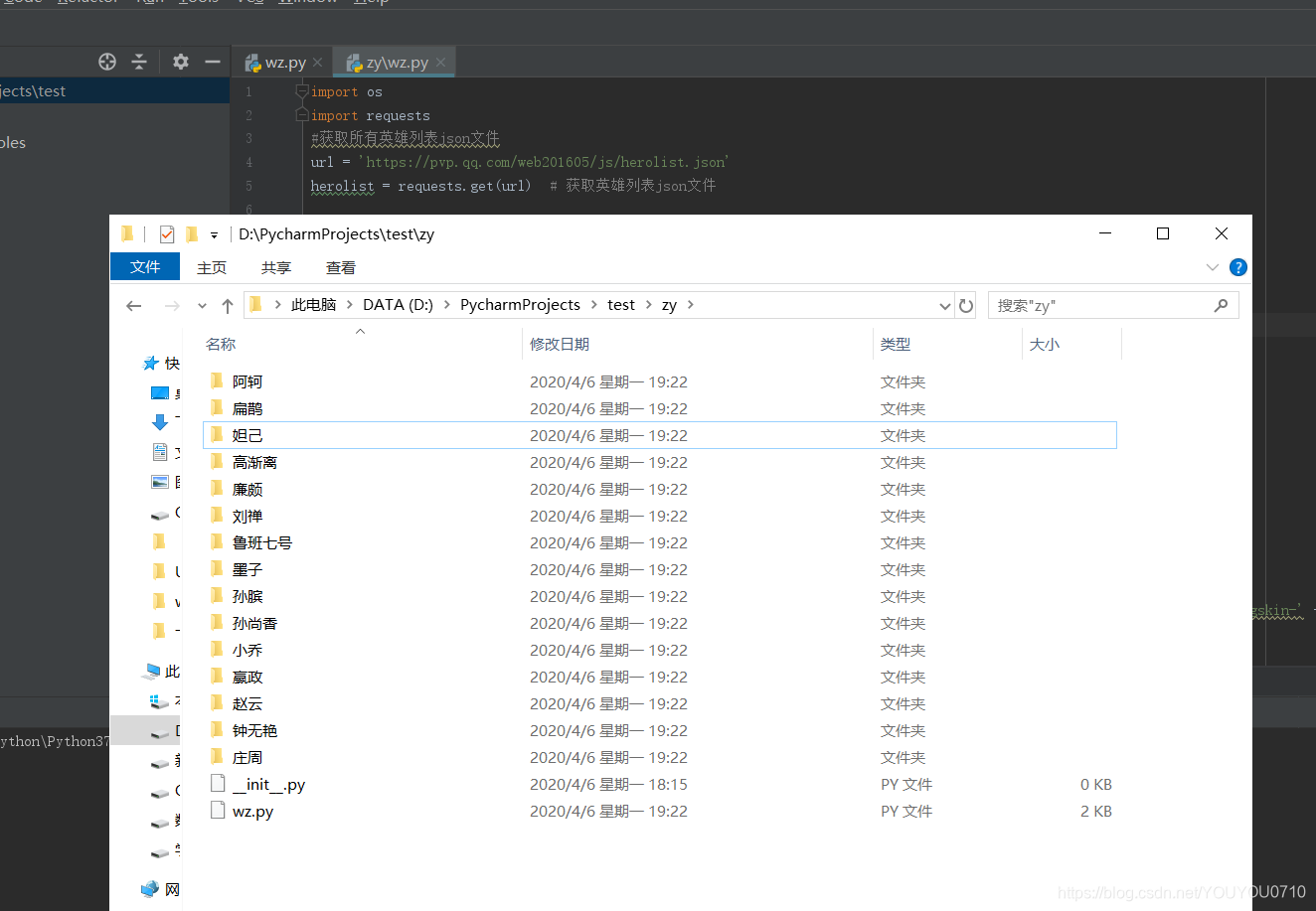
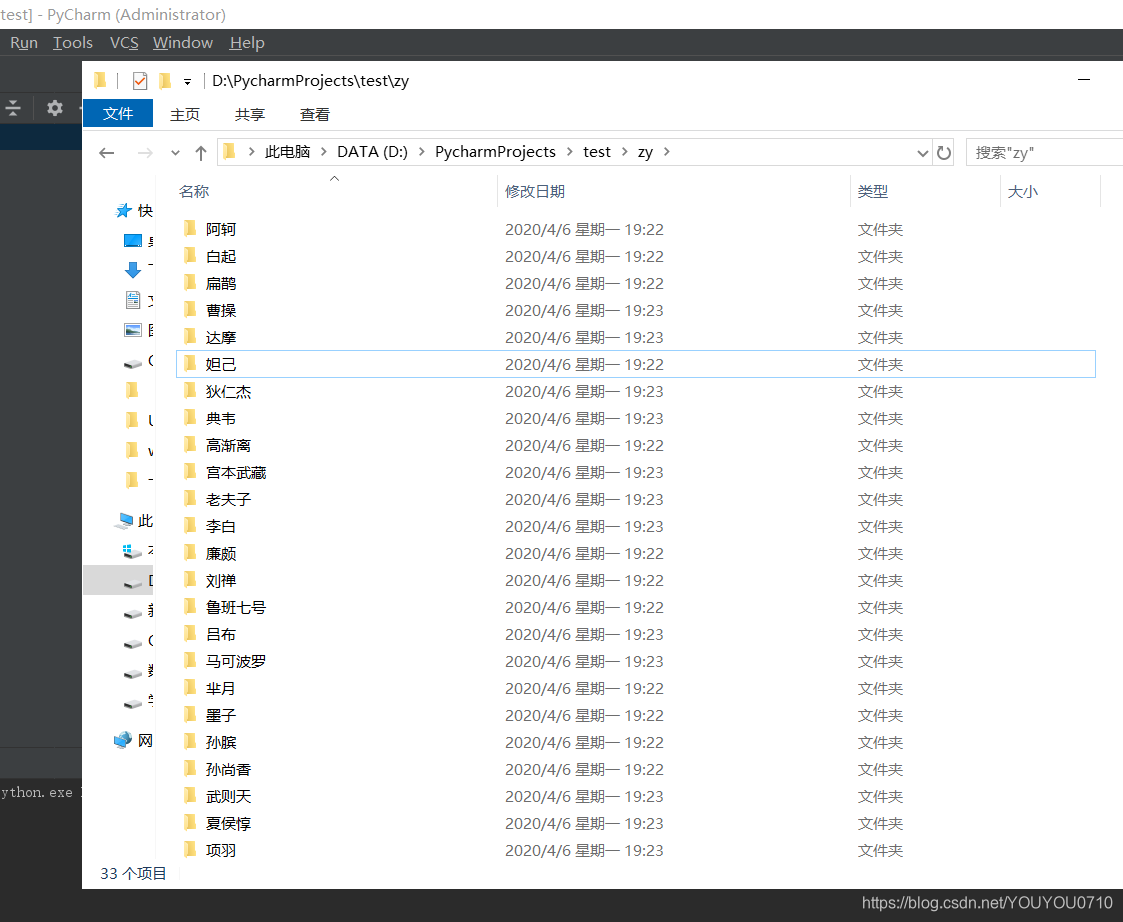
os.mkdir("D:\\PycharmProjects\\test\\zy\\" + hero_name[i])
# 进入创建好的文件夹
os.chdir("D:\\PycharmProjects\\test\\zy\\" + hero_name[i])
i += 1
#一般英雄皮肤数小于10,我们这里用10来遍历,如果存在就保存到本地
for k in range(10):
# 拼接url
onehero_link = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(j) + '/' + str(j) + '-bigskin-' + str(k) + '.jpg'
im = requests.get(onehero_link) # 请求url
if im.status_code == 200:
open(str(k) + '.jpg', 'wb').write(im.content) # 写入文件
downloadHeroPic()
print('完成啦!!!')
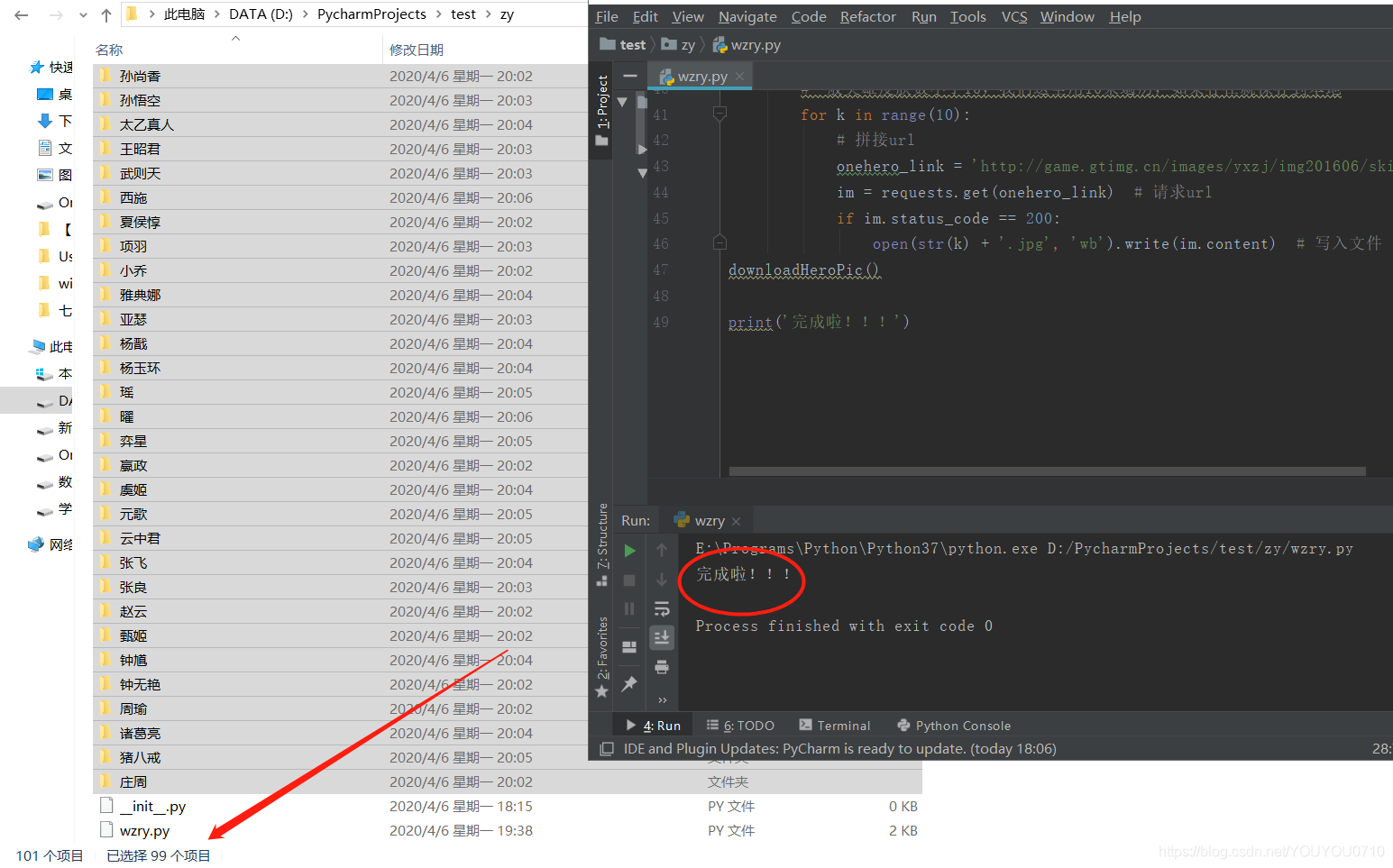
请求url的时候有时需要设置代理服务器,因为连续大量的请求,服务器会认为这是黑客攻击,会拒绝你当前ip的连接,导致请求失败,严重的话服务器会把你的ip或者与你同网段的ip地址拉入黑名单,导致一段时间无法访问连接。
当然,我们也有另一种方法:
(方法二)
# -*- coding: utf-8 -*-
"""
__title__ = '爬取王者荣耀英雄及皮肤高清图片'
__author__ = '张佑'
__mtime__ = '2020/04/06'
# code is far away from bugs with the god animal protecting
I love animals. They taste delicious.
┏┓ ┏┓
┏┛┻━━━┛┻┓
┃ ☃ ┃
┃ ┳┛ ┗┳ ┃
┃ ┻ ┃
┗━┓ ┏━┛
┃ ┗━━━┓
┃ 神兽保佑 ┣┓
┃ 永无BUG! ┏┛
┗┓┓┏━┳┓┏┛
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛
"""
from urllib import request, parse
import requests
# 设置request代理服务器
proxy_support = request.ProxyHandler({'http': 'http://xx.xx.xx.xx:xx'})
opener = request.build_opener(proxy_support, request.HTTPHandler)
request.install_opener(opener)
# 设置requests代理服务器
ip, port = ("125.126.222.12", "9999")
proxy_url = "http://{0}:{1}".format(ip, port)
proxy_dict = {
'https': proxy_url,
}
class wzry(object):
def __init__(self):
self.page = 0 # 抓取的起始页
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64)'} # 伪装成浏览器
def get_page(self):
try:
while self.page <= 10: # 设置抓取的结束页
url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?' \
'activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=' + str(
self.page) + '&i' \
'Order=0&iSortNumClose=1&iAMSAc' \
'tivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&' \
'iActId=2735&iModuleId=2735&_=1554873059538'
self.page = self.page + 1
req = request.Request(url, headers=self.headers)
response = request.urlopen(req)
data = response.read()
list_data = eval(data)['List']
for ls in list_data:
# 抓取图片url并替换特殊符号
sProdImgNo_6 = ls['sProdImgNo_6'].replace('%3A', ':').replace('%2F', '/').replace('%2E',
'.').replace(
'%5F', '_').replace('%2D', '-').replace('200', '0')
sProdName = ls['sProdName']
img_name = parse.unquote(sProdName) # 解码字符串
img = requests.get(sProdImgNo_6, proxies=proxy_dict, verify=False) # 抓取图片
print(f'正在抓取 {img_name} 高清皮肤......')
# 写入文件
with open(f'D:/PycharmProjects/test/{img_name}.jpg', 'wb') as f:
f.write(img.content)
except request.URLError as e:
if hasattr(e, 'reason'):
print(f'抓取失败,失败原因:{e.reason}')
class main():
wzry().get_page()
if __name__ == '__main__':
main()
print('抓取完成。。。')
最终结果如下所示:
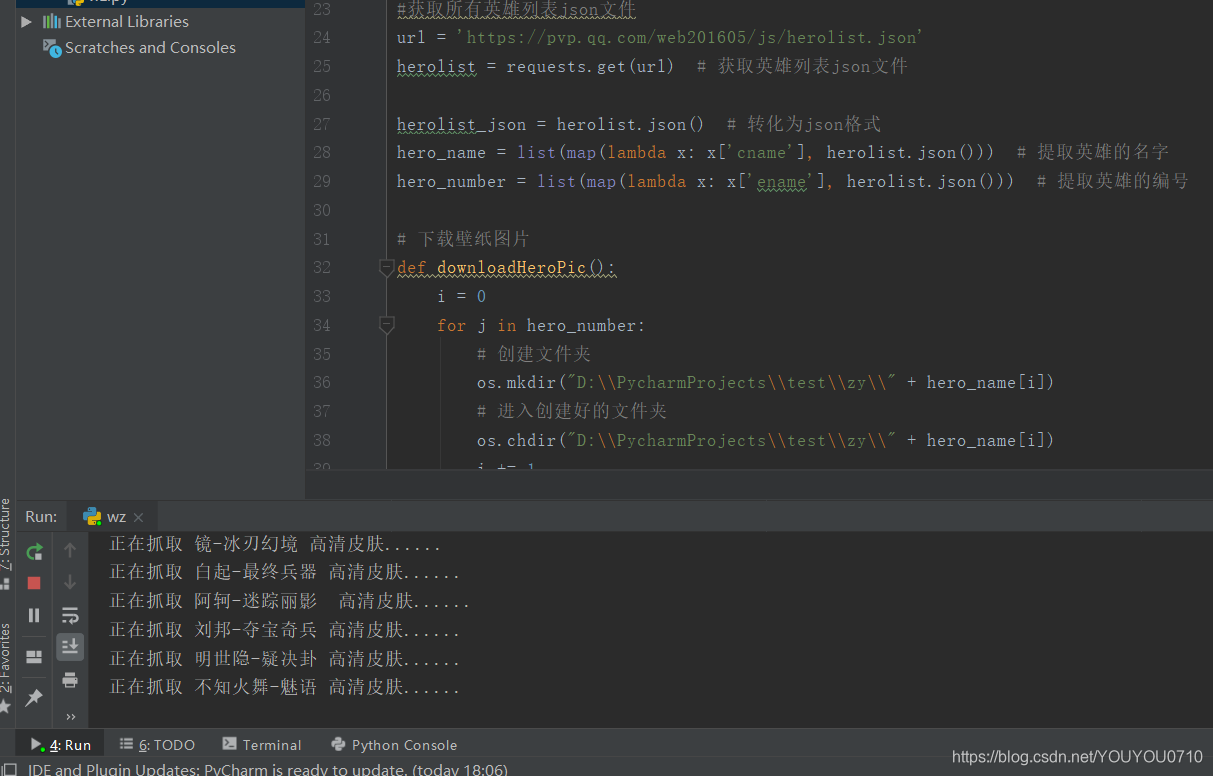
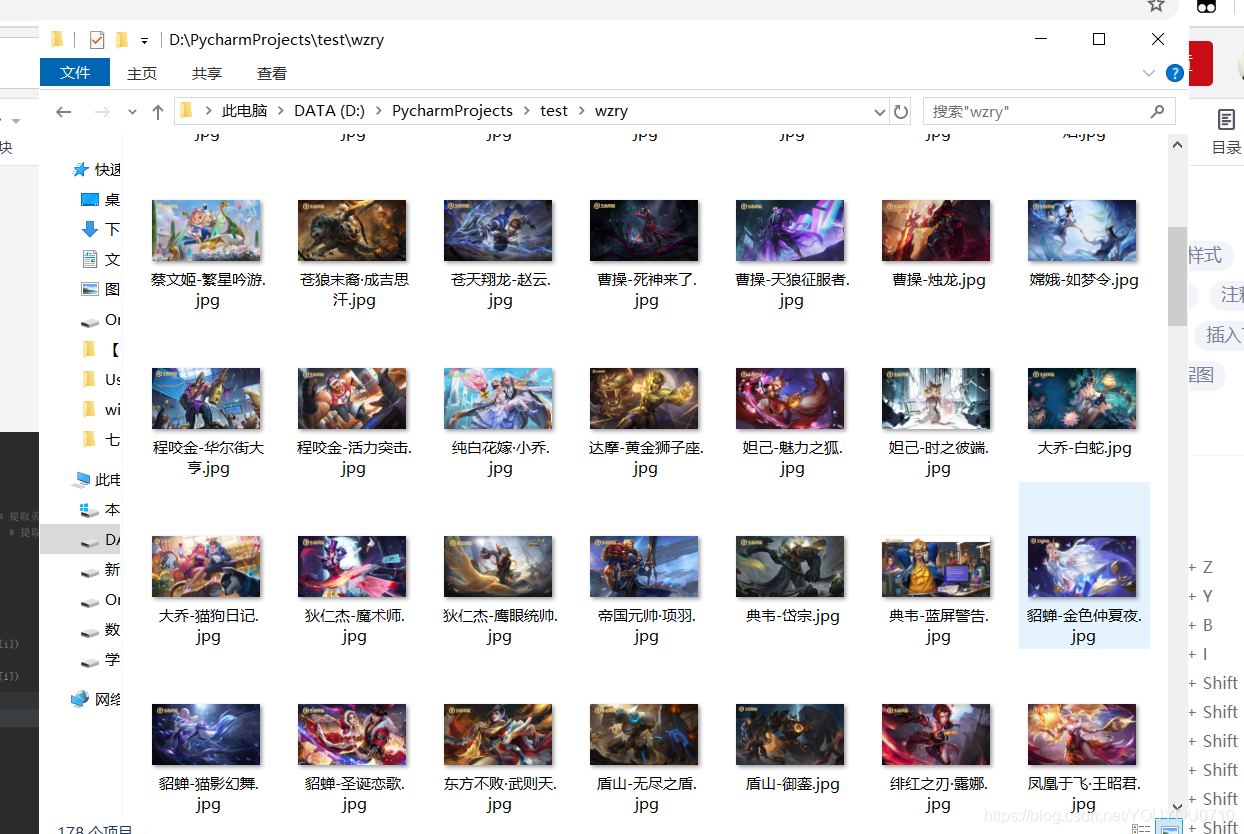
当然,如果你想要获取这些资源,但是你却比较懒,你也可以点击后面的这个链接:王者荣耀英雄及皮肤高清图片
或者扫描二维码,回复关键字“王者荣耀”



















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









