









大数据产业创新服务媒体
——聚焦数据 · 改变商业
最近这几天,业界关注度最高的无疑是DeepSeek的几个开源项目,几乎每一个都会在该领域里带来一些惊喜。
数据猿作为大数据领域的专业媒体,一直从数据层面来关注行业的进展。不得不说,在算法和算力层面很热闹,但相比之下,数据这个领域则要“冷清”很多。我们一直希望大模型的发展,能真是的带动大数据也腾飞一把。
所以,我们对DeepSeek最后一个开源项目尤为关注,因为这真的给数据领域带来了一个不小的惊喜。那这件事情到底会带来什么影响?
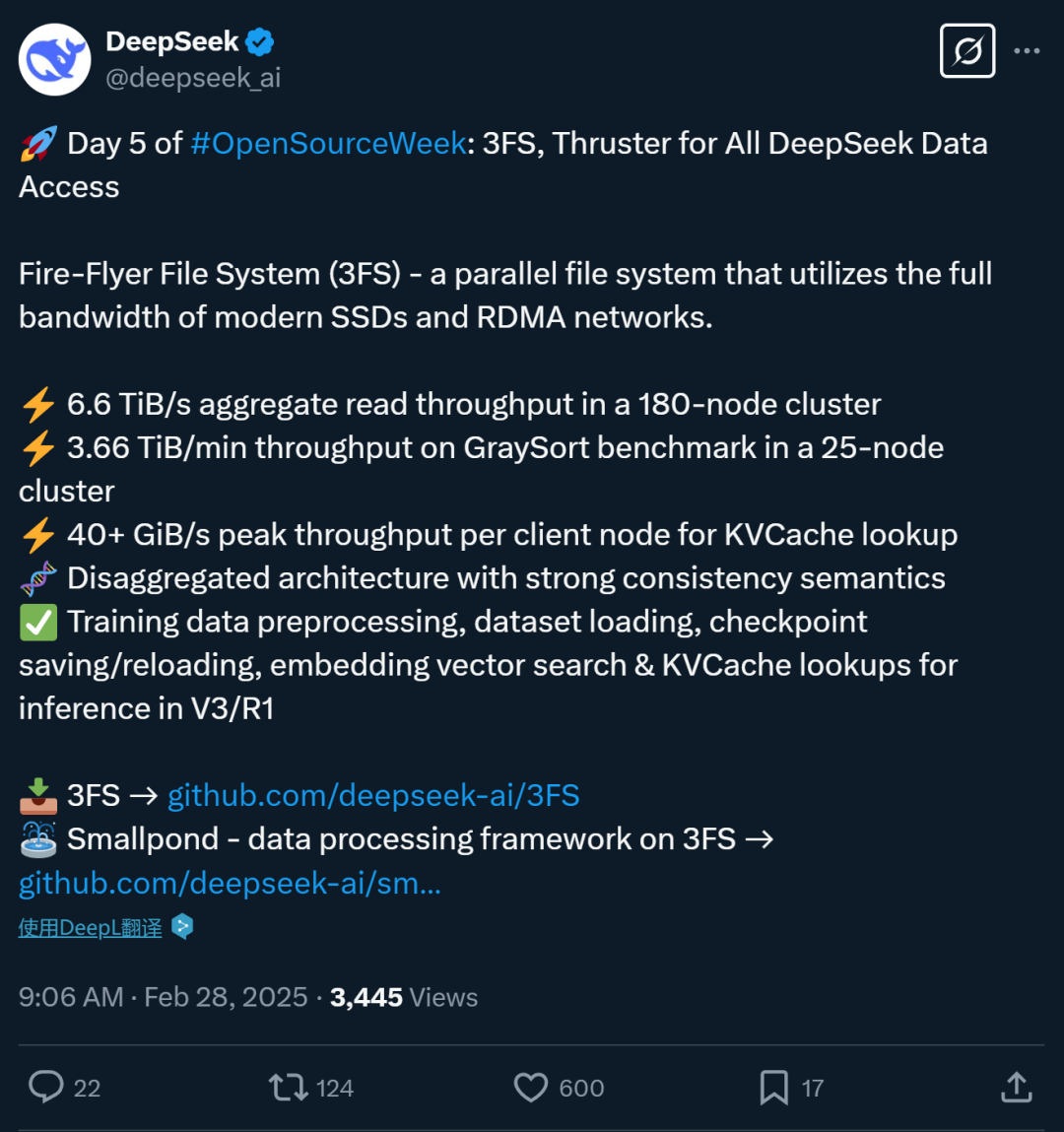
数据处理,成了整个“木桶”的短板
随着AI模型不断壮大,整个技术生态的痛点愈加显著。我们常常说,“大模型的训练就是一次彻底的折磨”——但真正的折磨,来自于数据处理,而非算力。今天,训练一个千亿甚至万亿参数的模大型,不仅需要海量数据,还需要在数据流动时极致的效率。
想象一下,你正在训练一个拥有数千亿参数的大模型,所需的训练数据可能多达数百TB,甚至更多。而这时,传统的分布式存储系统——如HDFS和NFS,已经完全无法跟上这种爆炸式增长的需求。它们就像老旧的高速公路,根本承载不住日益增多的车流。吞吐量太低、传输延迟太高,让数据流动几乎成了训练的“致命绊脚石”。
别看这些系统在小规模场景下还能应付,面对海量数据,它们的极限已经暴露。我们所期待的“加速”,往往在数据层的瓶颈面前,变成了空中楼阁。每一秒的延迟、每一次的数据访问堵塞,都直接影响着训练的速度和效果。想让一个超大规模模型训练迅速完成?你得先解开这道最难解的“数据瓶颈”。
推理阶段的“最后一公里”更致命!
可怕的并不只是训练阶段的数据延迟,推理阶段的延迟,才是致命的一击。很多人低估了推理时的“最后一公里”,认为只要模型训练好,推理就会顺利进行。错了!对于商业化应用来说,推理过程的延迟甚至比训练阶段更为关键。
以自动驾驶为例,1秒钟的推理延迟,足以让一辆车与另一辆车发生碰撞;而对于语音助手,1秒钟的迟钝反应,可能会直接影响到用户的使用体验,甚至让整个产品沦为“垃圾”。无论是在语音识别、图像处理,还是实时翻译等应用中,延迟是直接决定成败的命脉。
但现实是,现有的存储系统
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









