




 本文介绍了使用Python爬取东方财富网股吧评论的过程,包括分析网页源代码,识别数据标签,以及获取每个股吧页面的评论并保存到Excel。尽管遇到标题内容不全的问题,但通过详细页爬取得到了完整数据。作者是一名金融专业的研究生,学习爬虫进行项目研究,后续计划进行情感分析。
本文介绍了使用Python爬取东方财富网股吧评论的过程,包括分析网页源代码,识别数据标签,以及获取每个股吧页面的评论并保存到Excel。尽管遇到标题内容不全的问题,但通过详细页爬取得到了完整数据。作者是一名金融专业的研究生,学习爬虫进行项目研究,后续计划进行情感分析。
利用python爬取东方财富网股吧评论(一)
python-东方财富网贴吧文本数据爬取
分享一下写论文时爬数据用到的代码,有什么问题或者改善的建议的话小伙伴们一起评论区讨论。涉及内容在前人的研究基础之上,探索适合自己一些知识点,本人非计算机专业,金融专业,学习爬虫用于项目研究,以此发表供大家学习与指点。
一、论文说明
论文需求:股吧中人们发表的评论和创业板股市价格波动
数据来源:东方财富网创业板股吧
数据标签:阅读、评论、标题、作者、更新时间,
实现功能:读取每个股吧的全部页面的评论并写入excel表中
二、实施过程
1.明确评论数据

2.查看网页源代码结构
① 网页源代码
首先打开网页的开发者工具(右击-检查)或者右击网页源代码,在源代码中查找对应字段的标签。
以下是大多数学者的分析:
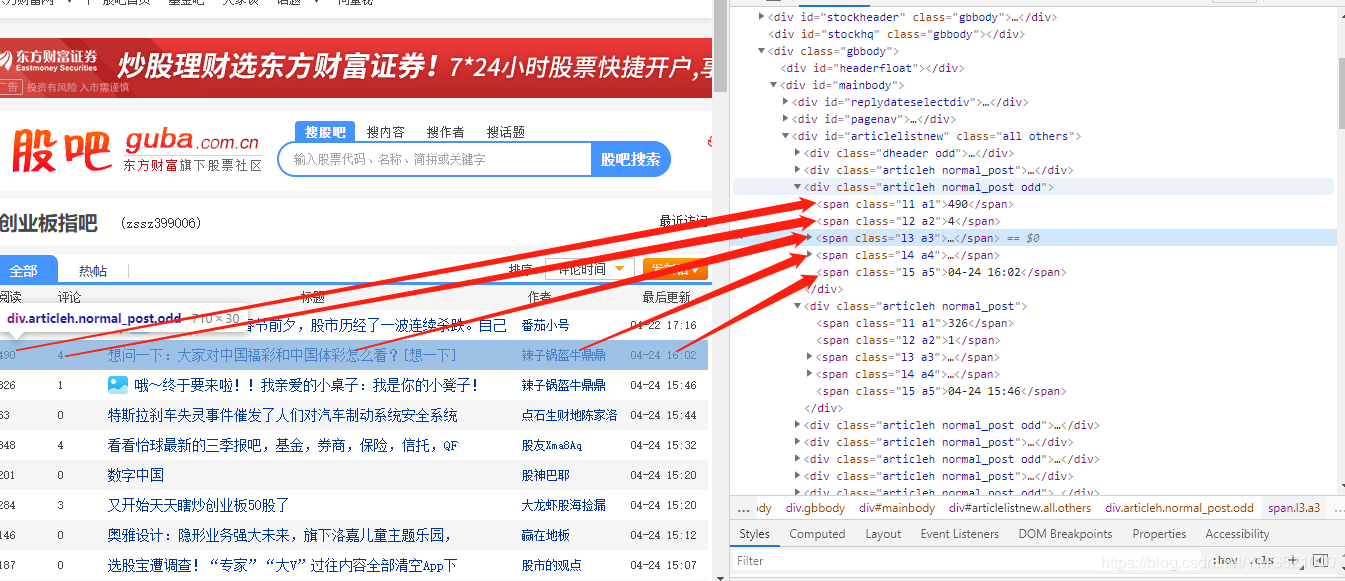
从图中可以看出,这五个字段分别位于行标签内,对应的属性分别是"l1 a1"、“l2 a2”、“l3 a3”、“l4 a4”、“l5 a5”。
如果单纯想要获取此网址所对应的数据,参考此方法都可以进行爬取。但是,爬取之后会发现标题内容是不全,缺失的:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6033
6033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









