






在学术研究中,面对海量论文,快速梳理主题分布是提升效率的关键。本文以某国际学术会议的 数百 余篇论文为研究对象,手把手带你实现文本聚类全流程,对比不同算法效果,分享实操中的优化技巧,适合 NLP 初学者入门参考。
一、项目背景与目标
随着学术论文数量逐年增长,手动筛选和归类已难以满足需求。无监督聚类算法能自动将主题相似的论文聚为一类,帮助研究者快速定位核心方向。
核心目标:
- 掌握文本预处理、特征工程、多聚类算法(K-Means/DBSCAN/ 层次聚类)的实现与对比;
- 学会用肘部法确定最优聚类数、分析异常点、通过可视化解读聚类结果;
- 理解无监督学习在文本主题挖掘中的实际应用价值。
二、实验数据与环境
1. 数据说明
实验数据来源于公开数据集,包含约 600 篇会议论文的标题、摘要、关键词等字段。预处理步骤如下:
- 文本合并:将标题、摘要、关键词拼接为统一文本,用特殊分隔符(如
[TITLE_END])区分字段,避免语义混淆; - 清洗优化:通过分词、去停用词(如 “the”“and”)、词形还原(如 “running”→“run”)提升文本质量。
2. 环境配置
- 编程语言:Python
- 核心库:pandas(数据处理)、scikit-learn(特征工程与聚类)、matplotlib/seaborn(可视化)
三、完整实验流程
1. 文本预处理:从原始文本到干净特征
预处理是聚类效果的基础,直接影响后续特征质量。
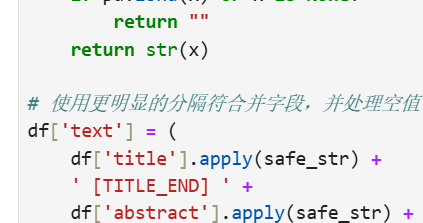

关键技巧:用[TITLE_END]等分隔符避免不同字段的语义混淆,手动维护轻量停用词表可减少外部依赖,适合离线环境。
2. 特征工程:TF-IDF 向量化
将文本转化为数值特征是聚类的前提,这里采用 TF-IDF(词频 - 逆文档频率)方法,突出主题词的重要性:

扩展:
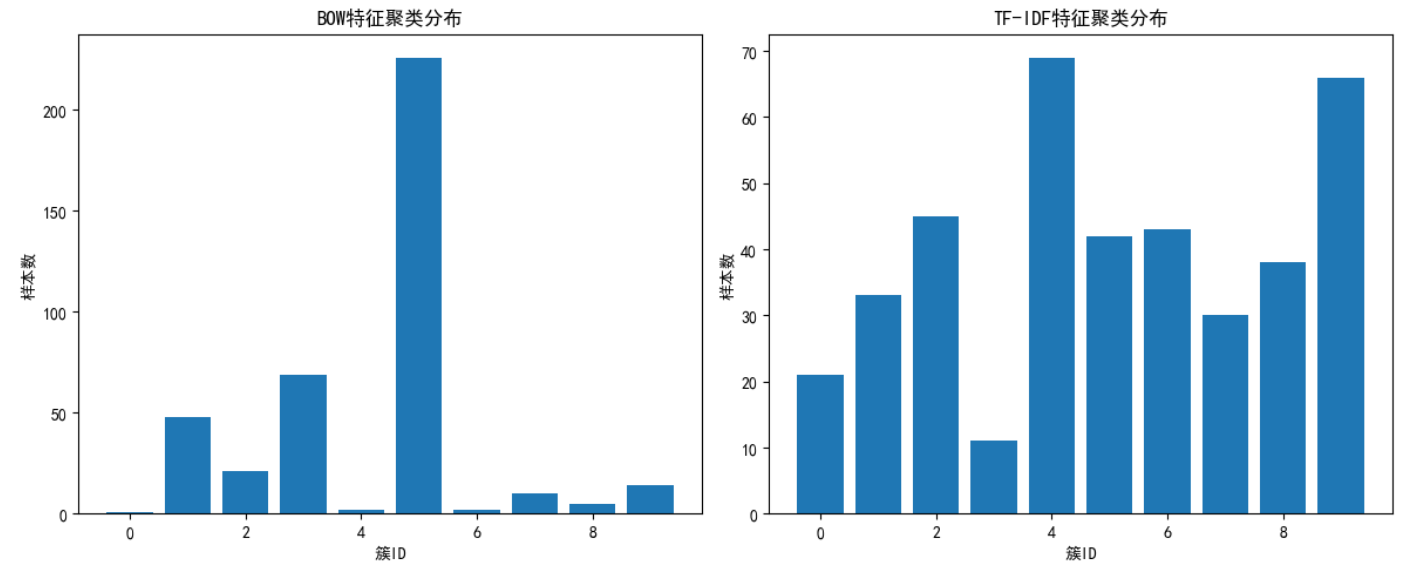
3. 聚类算法实战:K-Means vs DBSCAN
(1)K-Means 聚类(指定簇数)
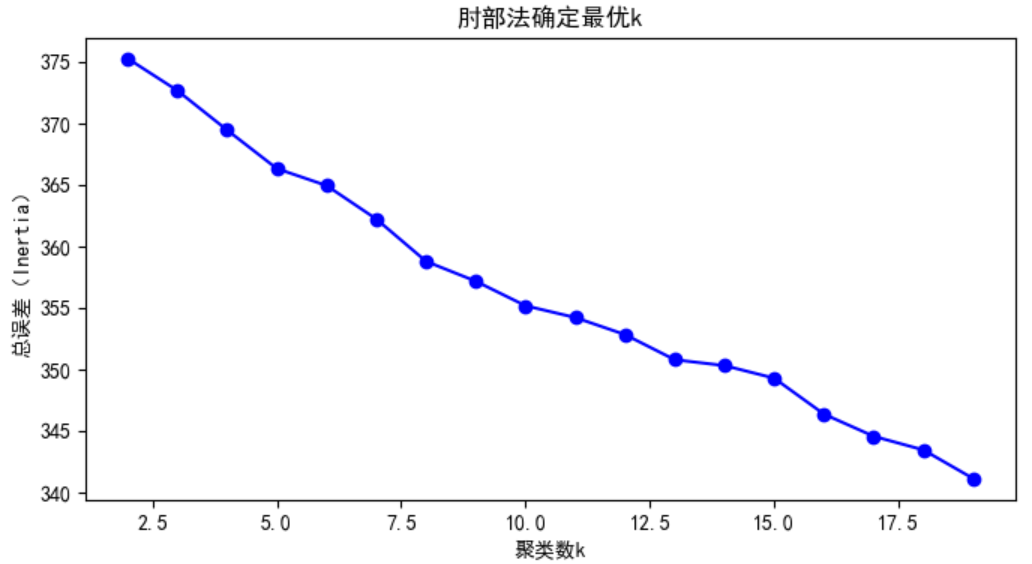
适合主题数量较明确的场景,需通过 “肘部法” 确定最优簇数k:
(2)DBSCAN 聚类(无需指定簇数)
基于密度的聚类算法,适合发现小众主题或非凸形状的簇:
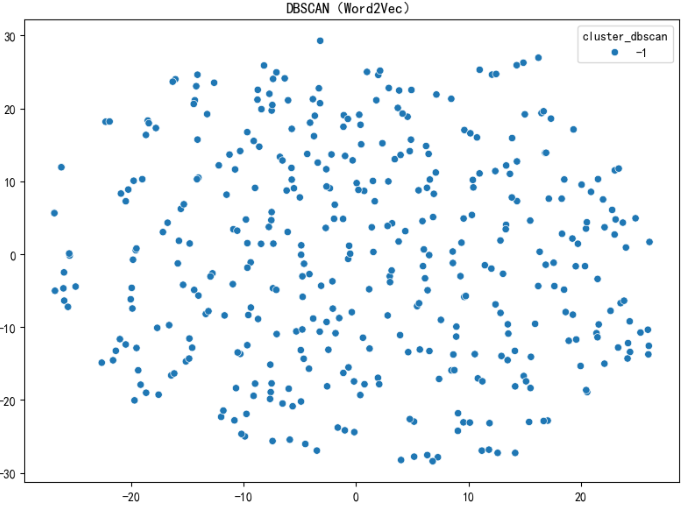
参数调优:eps过小会导致多数样本被标记为噪声(-1),过大则所有样本聚为一类,建议从 0.5 开始逐步调整。
4. 降维可视化:PCA 与 TSNE
高维特征无法直接可视化,通过降维技术将其转化为 2D 散点图,直观展示聚类效果:
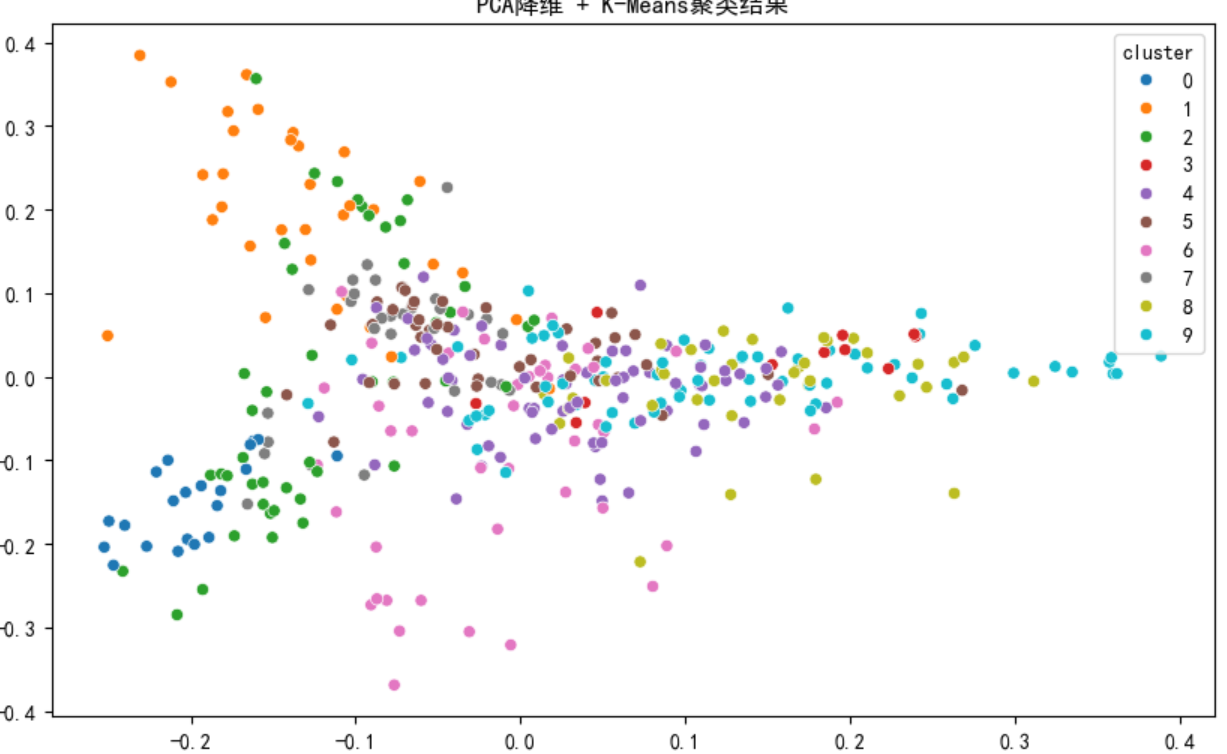
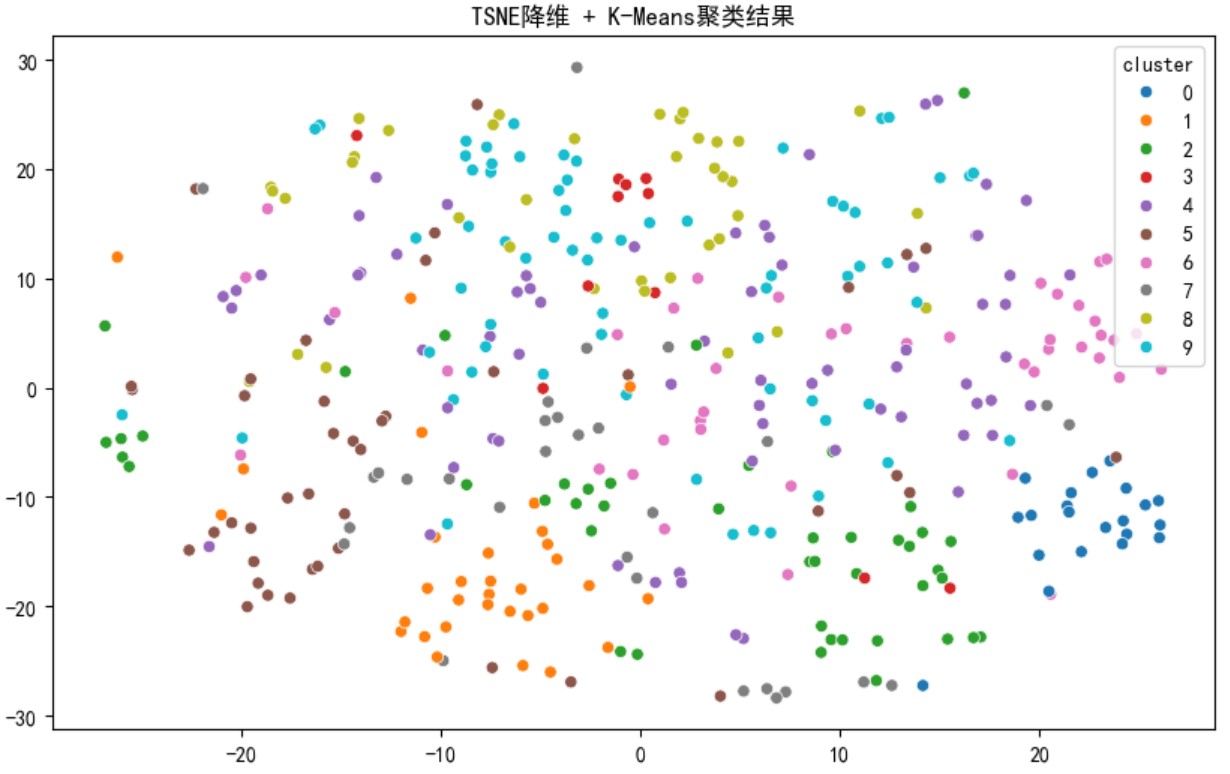
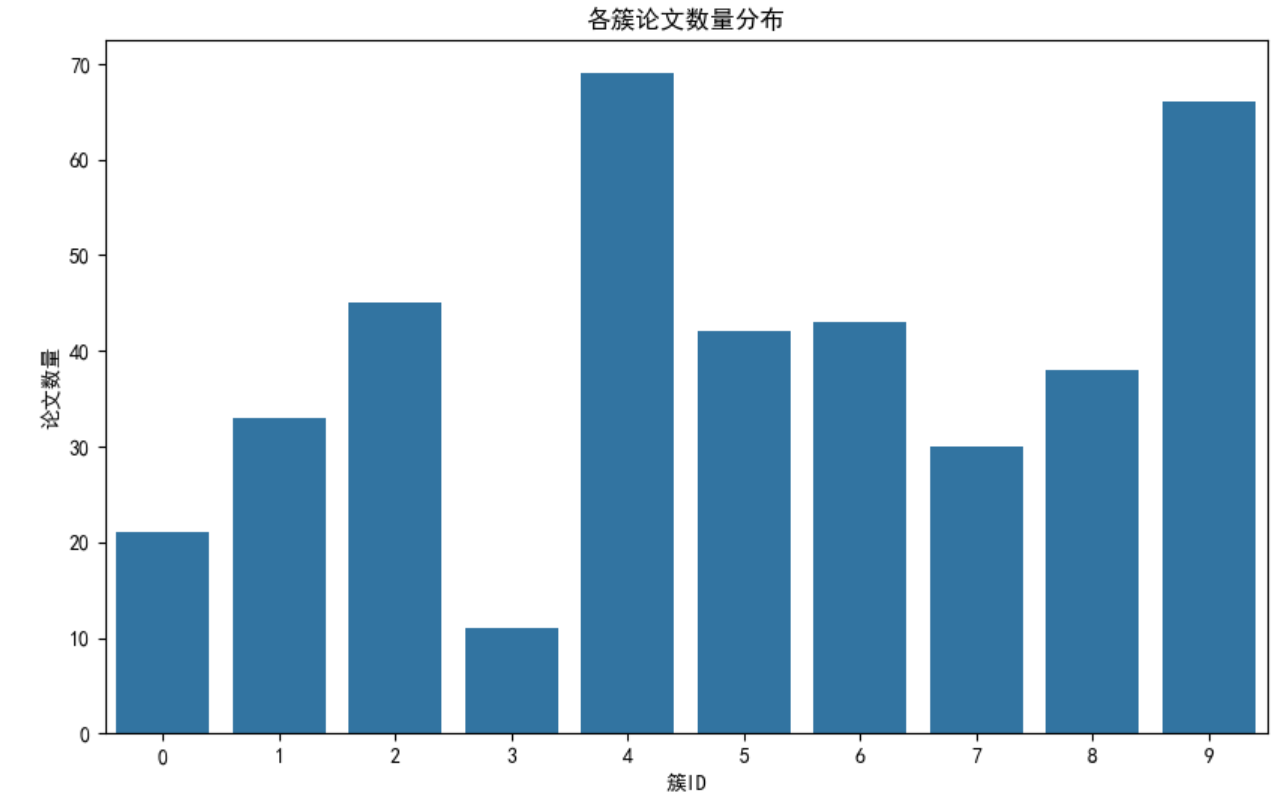
5. 聚类结果分析:挖掘主题与异常点



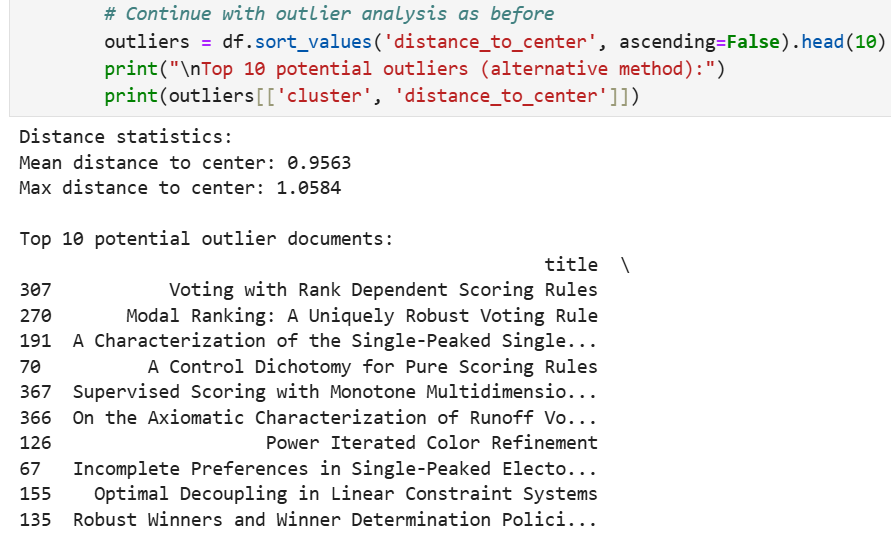
异常点分析
基于聚类的论文检索功能

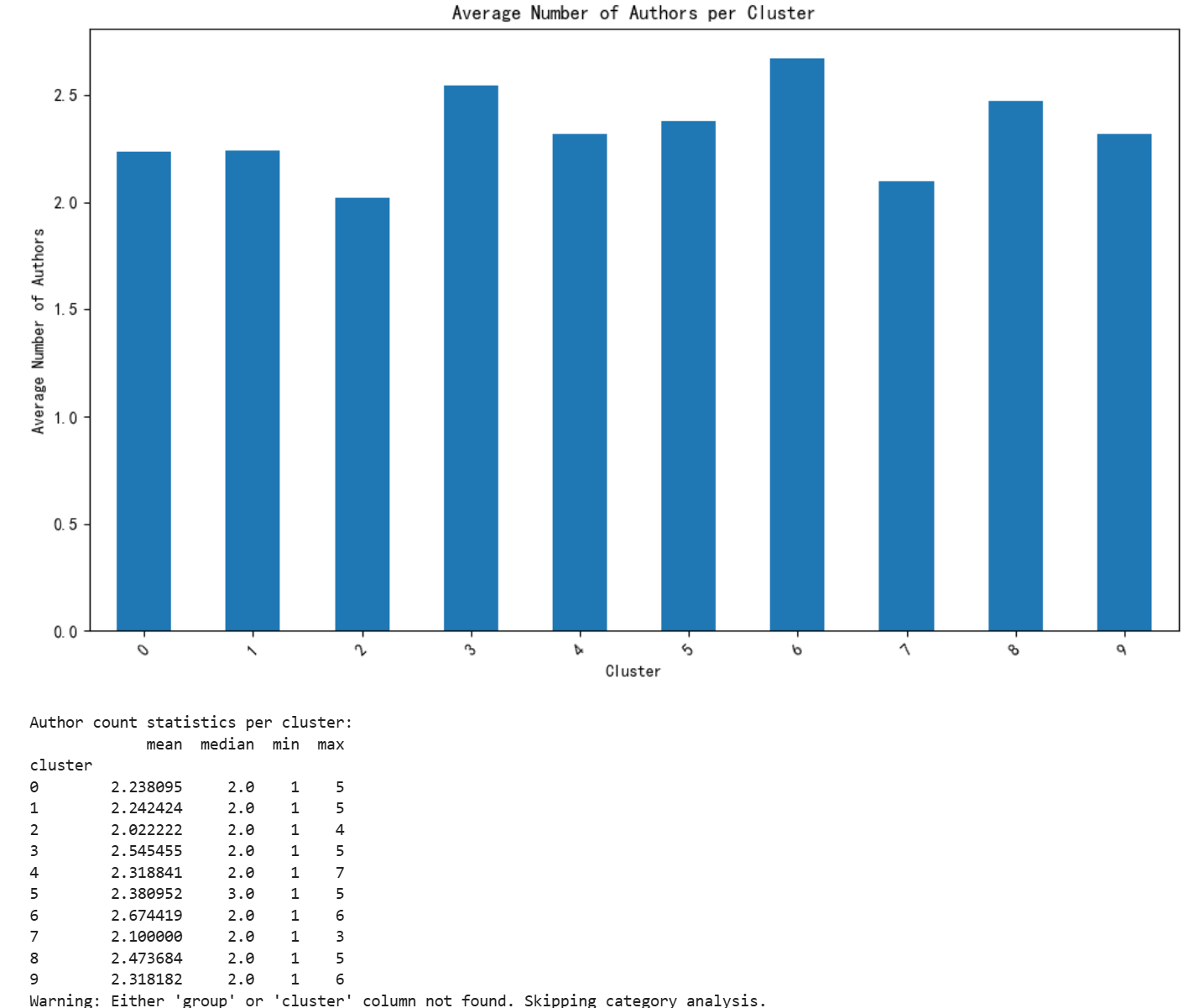
聚类与元数据的关联分析
四、实战避坑指南
- 空簇问题:K-Means 当
k过大(如 15)时会出现空簇,通过肘部法合理设置k(如 10)可解决; - 负号显示异常:绘图时出现 “Glyph 8722 missing” 警告,添加
plt.rcParams['axes.unicode_minus'] = False即可; - DBSCAN 全为噪声:
eps参数过小导致,逐步增大eps(如从 0.3→0.5)可生成有效簇; - 文本预处理不彻底:未过滤标点或停用词会导致特征冗余,需用正则分词 + 手动停用词表优化。
五、总结与展望
本次实验完整实现了文本聚类的全流程,对比 K-Means 与 DBSCAN 发现:
- K-Means 适合主题数量明确的场景,结果稳定但依赖
k值; - DBSCAN 无需预设簇数,能发现小众主题,但对参数敏感,需耐心调优。
最后,想和大家分享一个好用英语学习网站,www.b-techuniverseeducation.com里面有语言学习板块,现在可以免费学习。


















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











