




 集成学习通过结合多个模型的预测,实现性能提升。文章介绍了如何通过数据样本、输入特征、输出结果和算法参数的扰动增加模型多样性,并讨论了简单平均、加权平均等结合策略。文中还讲解了Bagging和Boosting两种集成算法,以及它们在降低模型方差和偏差上的区别。
集成学习通过结合多个模型的预测,实现性能提升。文章介绍了如何通过数据样本、输入特征、输出结果和算法参数的扰动增加模型多样性,并讨论了简单平均、加权平均等结合策略。文中还讲解了Bagging和Boosting两种集成算法,以及它们在降低模型方差和偏差上的区别。
最新分享,第一时间送达!
本文是《机器学习宝典》第 16篇,读完本文你能够对集成学习有一个简单的认识和理解。
上一篇介绍了面试常考的一个问题:回归决策树,这一篇我们来介绍下集成学习。在生活中,你是不是也会遇到这样的场景:当你对一件事情的判断没有把握的时候,通常会再咨询几个人,听听他们的观点,最后再做出决策。其实这反映出了一个思想:群体决策通常比个体决策更优,用句俗语来说就是:三个臭皮匠顶个诸葛亮。将这个思想应用于机器学习中就是集成学习(ensemble learning)。
为什么集成学习能够提升效果呢
为什么集成学习能够比单模型的效果更好呢?我们从以下几个角度考虑下:
从统计的角度来看,机器学习的任务可用认为是寻找一个最佳的假设空间。在没有充足的数据情况下,学习任务可以找到多个性能差不多的假设空间。如果融合多个模型的预测及过,可以降低预测错误的风险。外面的曲线表示假设空间,内部的曲线表示在训练集上具有不错性能的假设,点 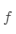 表示真实的假设 。我们看到,通过平均这些性能不错的假设,可以得到一个逼近 的优化假设 。
表示真实的假设 。我们看到,通过平均这些性能不错的假设,可以得到一个逼近 的优化假设 。
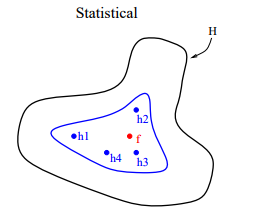
从计算的角度来看,很多优化算法采用局部搜索的方式来寻找最佳参数,这样很容易陷入局部最优解。融合多个模型可以看做是同一个训练集、从不同的起始点进行局部搜索,然后进行结合。这样可以降低陷入局部最优解的风向。
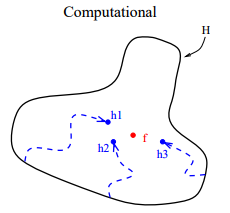
从表示的角度来看,理论上,如果给出足够的训练数据,很多算法可以表示所有的情况,例如神经网络和决策树。但是在很多实际应用中,能够用于训练的数据是有限的。有些学习任务的真实假设可能不在当前学习算法所考虑的假设空间中,此时如果使用单模型肯定无效 。模型融合可以使假设空间扩大,从而使得这些学习任务可能得到正确的表示。
在集成学习中,参与融合的模型叫做基模型,想要使得集成学习的效果好,基模型应该”好而不同“。也就是说,基模型的准确率不能太低,同时基模型之间的多样性(差异性)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









