



 博客以卷积和im2col+gemm实现卷积操作举例,介绍深度学习中Tensor的NC4HW4。阐述了NC4HW4的原理,即按行处理数据时,将前4个通道合并,不足补0。还说明了在NC4HW4中使用im2col+gemm实现卷积的方法,可对卷积进行加速计算。
博客以卷积和im2col+gemm实现卷积操作举例,介绍深度学习中Tensor的NC4HW4。阐述了NC4HW4的原理,即按行处理数据时,将前4个通道合并,不足补0。还说明了在NC4HW4中使用im2col+gemm实现卷积的方法,可对卷积进行加速计算。
【GiantPandaCV导语】以卷积和im2col+gemm实现卷积操作举例,来图解深度学习中Tensor的NC4HW4(其实应该是N{C/4+C%4>0?1:0}HW4),写成NC4HW4方便阅读.
什么是NC4HW4?
对于卷积操作, 根据计算机内存排布特点, 按行进行处理.处理完一个通道的数据, 转入下一个通道继续按行处理.
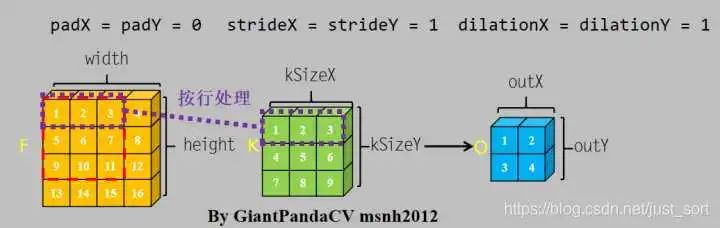
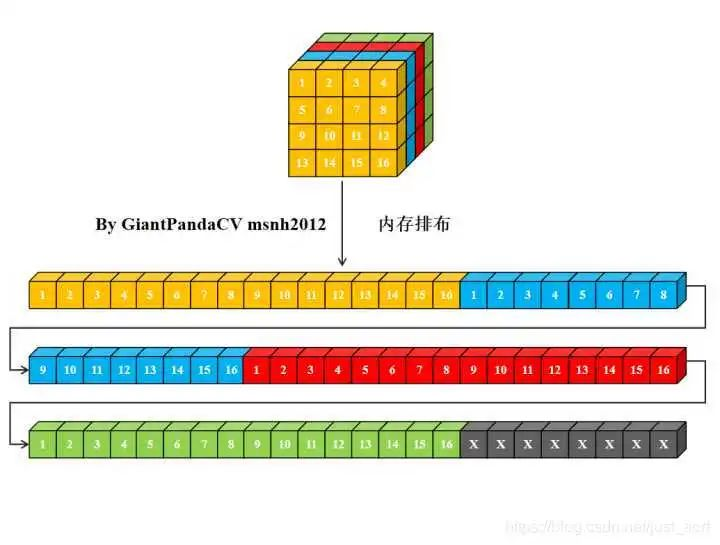
对于一个nchw格式的Tensor来说, 其在计算机中的内存排布是这样的:
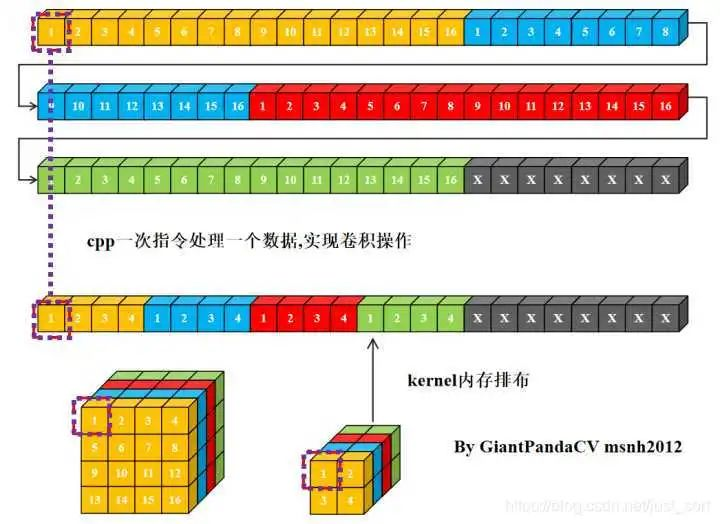
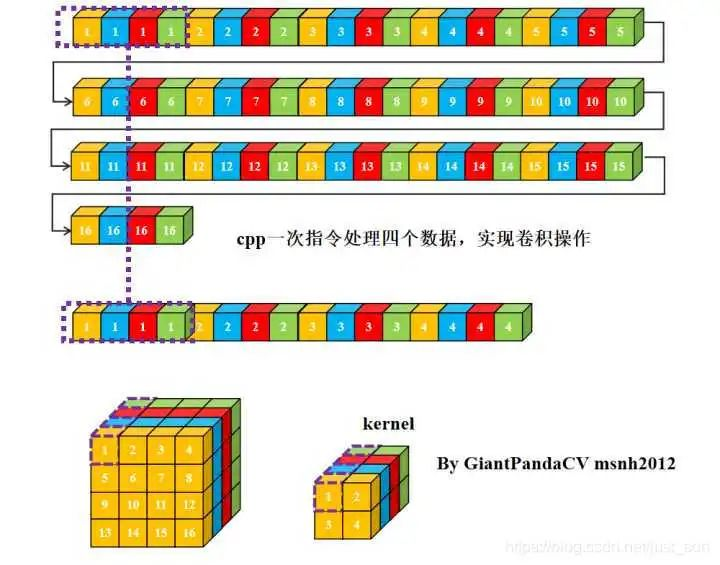
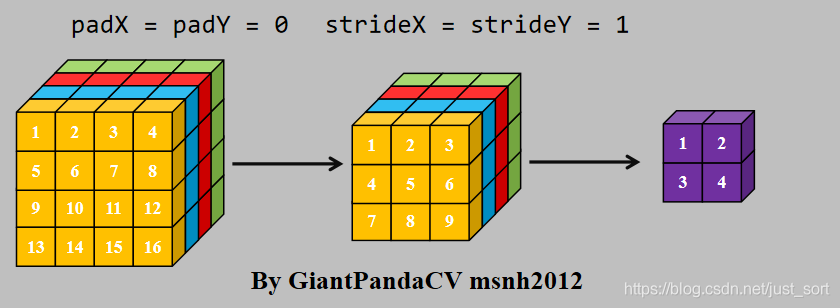
使用cpp一次指令处理一个数据, 用来处理卷积操作, 即循环实现乘法相加即可.
现在有一条指令处理4组数据的能力, 比如x86结构的sse指令,arm的neon指令.以及GPGPU的OpenGL和OpenCL,单次处理RGBA四组数据. 如果继续使用nchw内存排布的话, 是这样的.
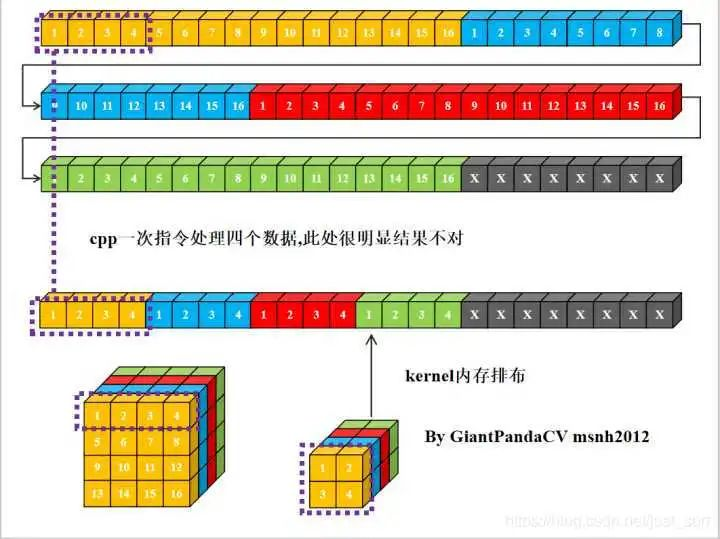
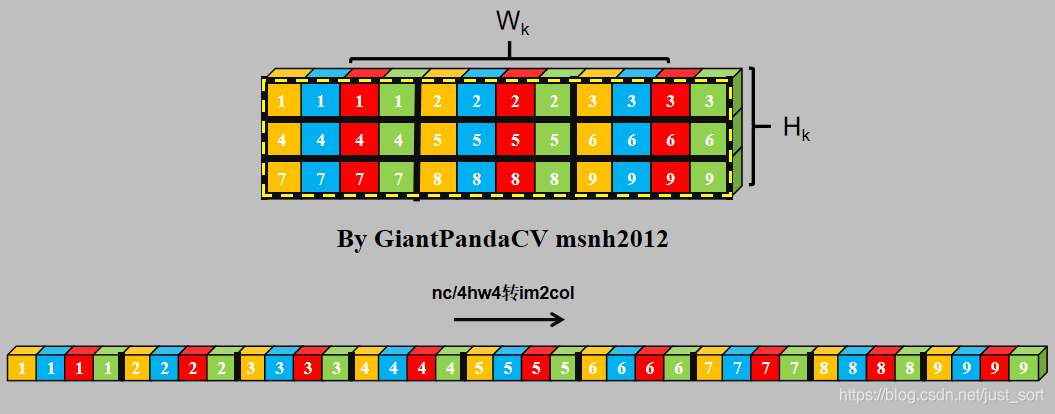
根据按行处理特点, 对于Feature和kernel的宽不是4倍数进行处理, 会出现错误. 图中的kernel很明显以已经到了第二行的值。那么有没有方法在按行处理的思想上, 一次处理4个数,而不受影响.答案是有的, 即NC4HW4.即把前4个通道合并在一个通道上, 依次类推, 在通道数不够4的情况下进行补0.

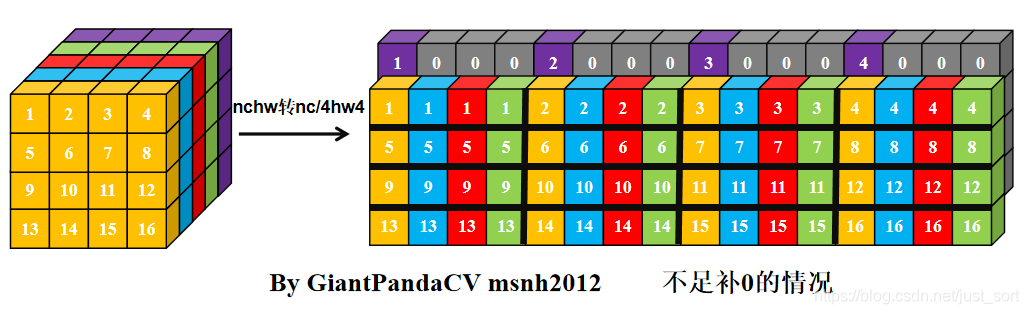
经过NC4HW4重排后的Tensor在内存中的排布情况如下:
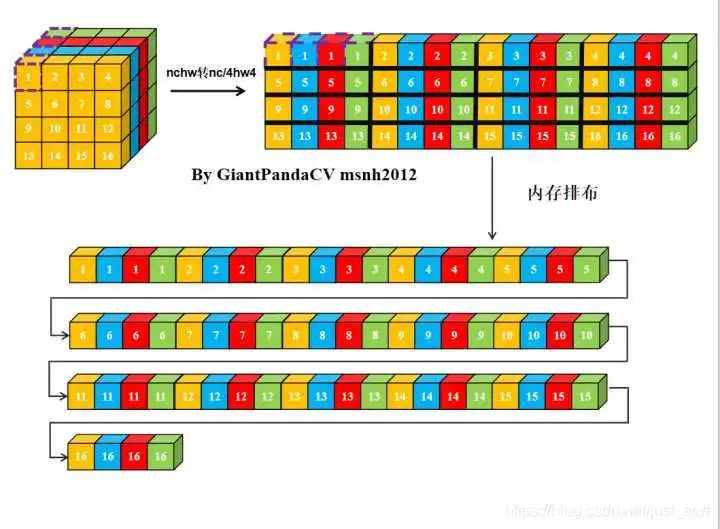
那么, 此时在进行单次指令处理4组数据的处理,就没有问题了.只不过处理结果也是NC4HW4结构的,需要在结果输出加上NC4HW4转nchw.
NC4HW4中使用im2col+gemm实现卷积:
im2col+gemm在深度学习中是最常用的对卷积进行加速计算的方案。最早在caffe框架中支持。思路如下:
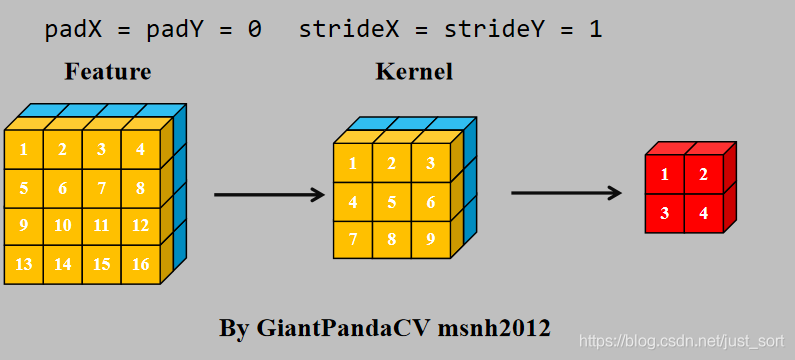
使用im2col+gemm进行计算:
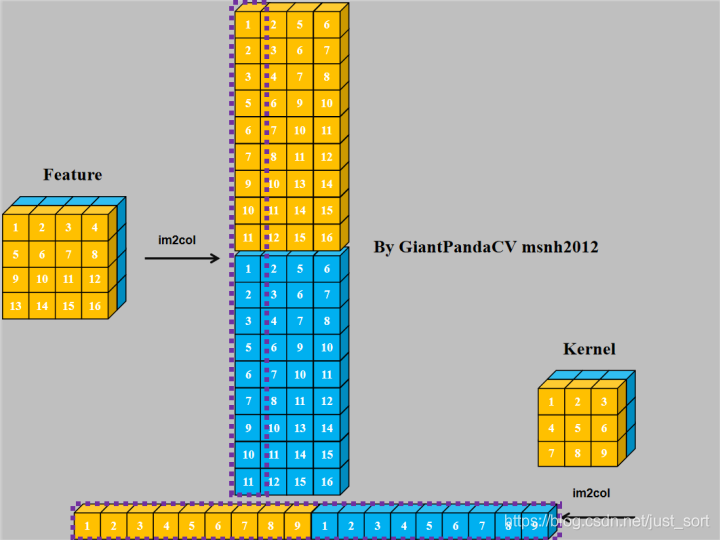
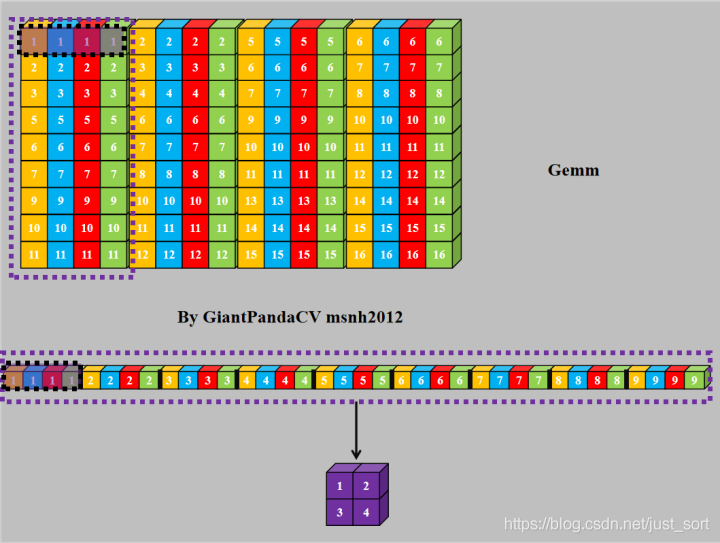
对于NC4HW4内存排布的Tensor来说,同样可以采用im2col+gemm来处理.
有如下卷积,可以使用NC4HW4内存排布方式,使用指令集优化对卷积进行加速.
NCHW转NC4HW4.
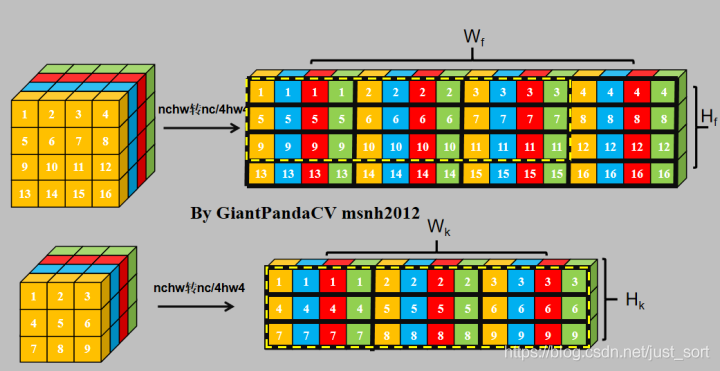
NC4HW4对feature进行im2col
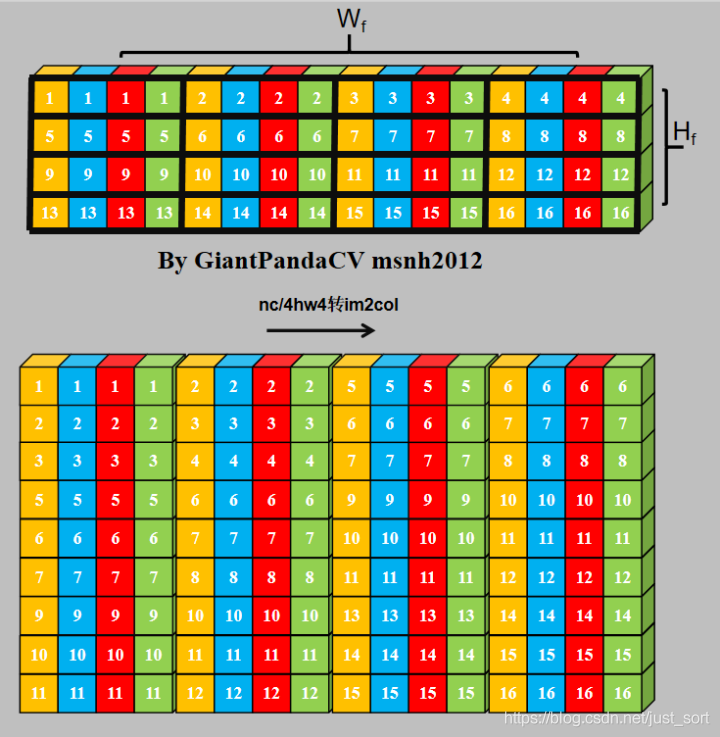
NC4HW4对kernel进行im2col
使用SSE,Neon,OpenCL或OpenGL实现Gemm.
最后
文末福利
各位猿们,还在为记不住API发愁吗,哈哈哈,最近发现了国外大师整理了一份Python代码速查表和Pycharm快捷键sheet,火爆国外,这里分享给大家。
这个是一份Python代码速查表

下面的宝藏图片是2张(windows && Mac)高清的PyCharm快捷键一览图

怎样获取呢?可以添加我们的AI派团队的程序媛姐姐
一定要备注【高清图】哦
????????????????????

➕我们的程序媛小姐姐微信要记得备注【高清图】哦
来都来了,喜欢的话就请分享、点赞、在看三连再走吧~~~


















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









