







这里是X,这学期我将学习一门课程叫做“scikit-learn机器学习”,这里是我上课笔记,记录我自己学习这门课程的过程,还有老师上课讲的知识点,我都记录在这里了,有任何问题也欢迎私信,对你有帮助的话也别忘了关注和收藏、以及订阅哦(可能内容会有点乱毕竟是及时记下来的,但是我会尽量整理好的)
机器学习第一课

不要企图用机器学习去适应所有功能,只能用机器学习来完成某一具体“任务”
机器学习最常见的例子就是人脸识别了,人脸识别的可靠性从哪里看出来呢,就是“银行”,众所周知,银行肯定是最需要可靠性工具的地方,现在很多银行取卡或者做一些工作的时候都必须进行人脸识别,也可想而知人脸识别的可靠性,包括像手写识别等的各种不同的识别功能都属于机器学习的一部分🤞🤞🤞
我们该如何完成这些任务,我们要做的就是将很多具体的问题转换成抽象问题(数值化)
这个到底是什么问题,这个问题可以看成什么问题?分类问题?回归问题?

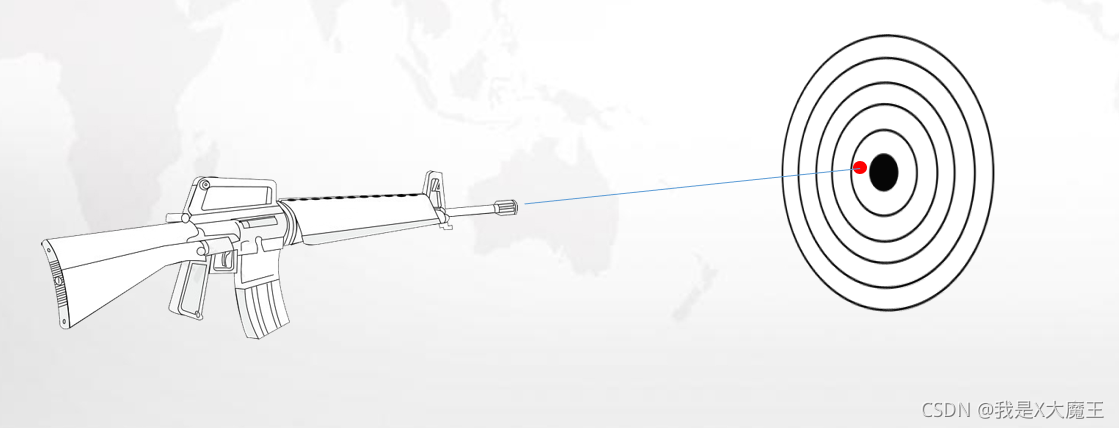
可以将这个过程看成是打靶的过程
1.1任务类型
🦒分类
许许多多的问题都可以归为分类问题,比如在自动驾驶中,该不该踩刹车?就分为踩刹车和不踩刹车;下围棋时候,机器将下棋分为该不该下里?下哪里才是最合适的?等等问题都是可以分为很多的情况下讨论🙌
这个和香港、澳门回归的“回归”是不一样的,那么这个“回归”到底是什么意思,比如我国2021年生产国民总值为1.62亿元,去年是1.61亿元,收集到很多的数据之后我们对这些数据进行比较、拟合
🦒聚类大小比较有没有意义??谷歌、手机会不定期给你推荐一些软件,淘宝等,那么它们的推荐就是将人群分类,然后根据分类的人群再给对应人群推广告,聚类问题不一定有具体的数字
🦒降维
简化问题
机器学习是人工智能的一部分,所有的机器学习面对的只是数据,没有数据什么都免谈,学习各种各样的model,根据数据位,不断给位数据
分类和回归也是最常见的监督学习机器的学习任务,而最常见的无监督学习任务是在数据集内发现互相关联的观测值群值,也就是聚类,降维也是常用的无监督学习的任务类型
1.2数据
有监督:有标签的
无监督:
半监督:
变量输入都是必不可少的,数据又可以分为几个部分:
1、训练集2、测试集3、验证集4、交叉验证(train)
2、测试集常用给自己留存起来的,看看训练完的效果(test)
3、在训练过程,用来监控用的,监控训练过程,这个过程有没有问题(validation)
4、怎么用到验证集?我们会用到交叉验证的方法
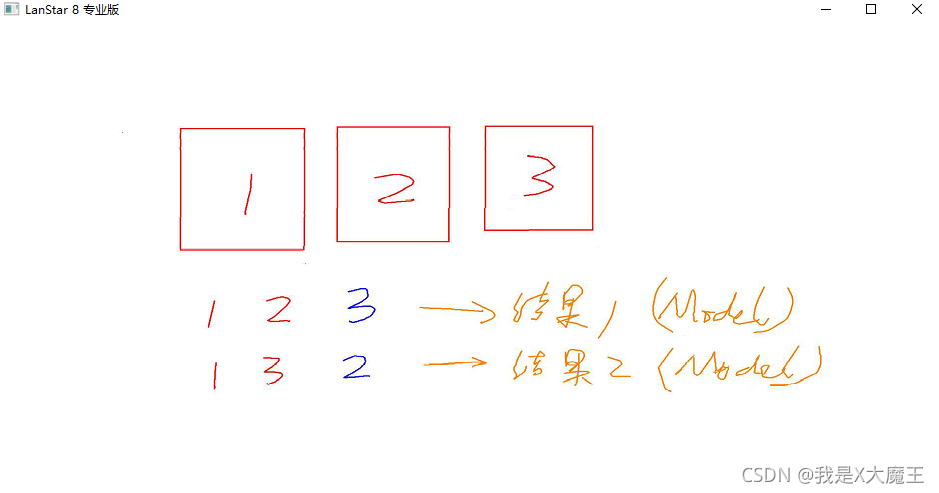
一般来说得到的结果一般平均、或者加权平均得到最终的模型
几个重要的概念
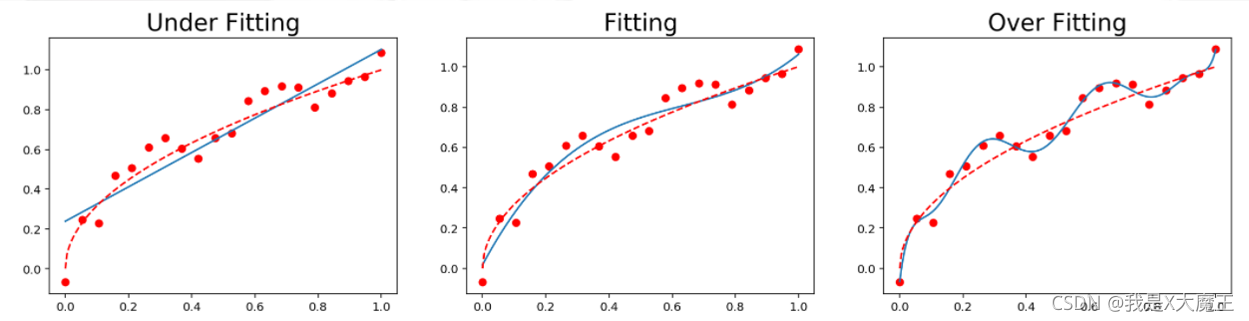
过拟合、欠拟合
过拟合:就是本身你完成的很好,但是和最终想要呈现的效果不一致
欠拟合:拟合的不够,训练的不够
偏差:一般用偏差来形容我们的loss(图中就是靠近把心的点很多,那么偏差就小,否则就大)
方差:在图中点很集中(不管在不在把心,总之就是一群点聚集在一起,那么就是方差小,否则就是方差大)
方差比较小,偏差比较大这种情况比较好处理,比较容易解决
方差比较大,偏差比较小这种情况比较难处理,比较不稳定
具体看图:

得到的loss,具体判断他们的指标取决于你当前用什么方法解决

MAE就是换成绝对值就行了
超参数:人定的参数就是超参数
深入:什么是机器学习?
入门阶段来看:最重要的就是选模型,然后选择一些超参数,超参数就是不断地去摸索,也同时靠经验和运气💛




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











