







 本文介绍了如何使用Python的aiohttp库构建异步爬虫,爬取一个通过Ajax加载的图书网站数据。首先分析了网页结构和Ajax请求,然后通过aiohttp爬取列表页和详情页,最后将数据存储到MongoDB数据库中,利用异步IO提高爬取效率。
本文介绍了如何使用Python的aiohttp库构建异步爬虫,爬取一个通过Ajax加载的图书网站数据。首先分析了网页结构和Ajax请求,然后通过aiohttp爬取列表页和详情页,最后将数据存储到MongoDB数据库中,利用异步IO提高爬取效率。
aiohttp异步爬取实战
爬取对象
博客源地址:修能的博客
这次要实战爬取一个数据量比较大的网站https://spa5.scrape.center/
网页分析
这是一个图书网站,有几千本图书的信息,网站的数据是由JavaScript渲染出来的,数据可以由Ajax接口获取。
要成为的目标:
-
使用
aiohttp爬取全站的图书数据 -
将数据通过异步的方式保存到Monga数据库
准备工作
-
Python3.6及以上 -
了解Ajax爬取的基本原理和模拟方法
-
了解异步爬虫的基本原理和
asyncio库的基本用法 -
了解
aiohttp的基本方法 -
安装并成功运行
MongoDB数据库,而且安装异步爬虫库motorMango的异步存储,离不开Mango存储库motor,在终端输入即可pip install motor
页面源码分析
在开发者模式中查看XHR(Ajax)的数据。
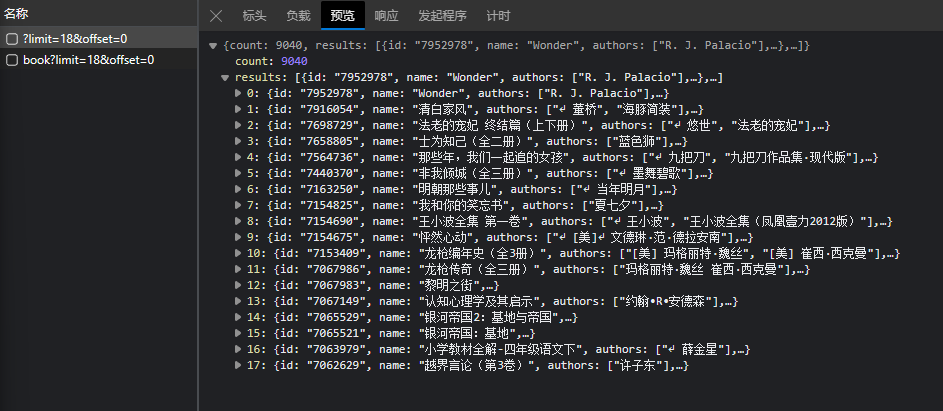
可以看到详情页的请求接口为:https://spa5.scrape.center/?limit=18&offset=0。
limit:表示每页最多由18个数据。offset:表示详情页的序号
在Ajax返回的数据中results字段包含当前页面里的18本图书信息,比较重要的信息就是id属性,在之后访问每本书的详情页时由需要id来构造URL。
点进一个图书的详情页,可以看到详情页的URL为:[Scrape | Book](https://spa5.scrape.center/detail/7952978)
所以可以看到URL的结构为https://spa5.scrape.center/detail/id
再对图书的详情页分析,在开发者工具查看XHR包
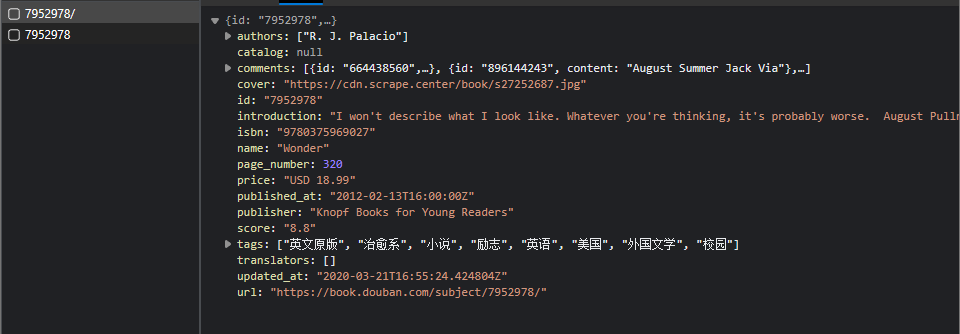
可以看到Ajax返回的数据就是图书的数据。
实现思路
完善的思路,但是实现的难度大
完善的异步爬虫应该能够充分利用资源进行全速爬取,实现的思路就是维护一个动态变化的爬取队列,每产生一个新的task,就将其放入爬取队列中,与专门的爬虫消费者从此队列中获取task并爬取,能够做到在最大的并发量的前提下充分利用等待时间进行额外的爬取处理。
简单的思路
- 首先爬取列表页
- 其次爬取详情页
难点在于并发执行,所以可以将爬取拆分为如下的两个阶段。
- 首先,异步爬取所有的列表页,可以将所有列表页的爬取任务集合到一起,并将其声明为由
task组成的列表 - 之后,将上一步爬取的列表页的所有内容并解析,将所有图书的id信息组合成所有详情页的爬取任务集合,并将其声明为
task组成的列表,解析异步爬取,同时爬取结果也以异步方式存储到MongoDB数据库。
代码编写
基本配置
"""基本配置"""
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s : %(message)s')
INDEX_URL = 'https://spa5.scrape.center/api/book/?limit=18&offset={offset}'
DETAIL_URL = 'https://spa5.scrape.center/detail/api/book/{id}'
PAGE_SIZE = 18
PAGE_NUMBER = 502
CONCURRENCY = 10
配置了一些参数:
- 日志配置
INDEX_URL:列表页的URL的构造DETAIL_URL:详情页的URL构造PAGE_SIZE:每页的数据量PAGE_NUMBER:详情页的数量CONCURRENCY:最大并发量
爬取列表页
"""爬取列表页"""
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
async def scrape_api(url):
async with semaphore:
try:
logging.info('scraping %s',url)
async with session.get(url) as response:
return await response.json()
except aiohttp.ClientError:
logging.error('error occurred while scraping %s',url,exc_info=True)
async def main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(scrape_index(page))
for page in range(1, PAGE_SIZE + 1)]
results = await asyncio.gather(*scrape_index_tasks)
logging.info('results %s', json.dumps(results, ensure_ascii=False, indent=2))
运行以下__main__函数
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())
爬取详情页
改写main()
async def main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(scrape_index(page))
for page in range(1, PAGE_SIZE + 1)]
results = await asyncio.gather(*scrape_index_tasks)
# logging.info('results %s', json.dumps(results, ensure_ascii=False, indent=2))
ids = []
for index_data in results:
if not index_data: continue
for item in index_data.get('results'):
ids.append(item.get('id'))
scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id)) for id in ids]
await asyncio.wait(scrape_detail_tasks)
await session.close()
添加爬取详情页的函数
"""爬取详情页"""
from motor.motor_asyncio import AsyncIOMotorClient
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'books'
MONGO_COLLECTION_NAME = 'books'
client = AsyncIOMotorClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
async def save_data(data):
logging.info('saving data %s', data)
if data:
return await collection.update_one({
'id': data.get('id')
}, {
'$set': data
}, upsert=True)
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
await save_data(data)
这里使用支持异步操作的motor中的AsyncIOMotorClient来进行异步的数据存储。
完整代码
import asyncio
import aiohttp
import logging
import json
from motor.motor_asyncio import AsyncIOMotorClient
import time
"""基本配置"""
start = time.time()
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s : %(message)s')
INDEX_URL = 'https://spa5.scrape.center/api/book/?limit=18&offset={offset}'
DETAIL_URL = 'https://spa5.scrape.center/api/book/{id}'
PAGE_SIZE = 18
PAGE_NUMBER = 502
CONCURRENCY = 10
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'books'
MONGO_COLLECTION_NAME = 'books'
client = AsyncIOMotorClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
"""爬取列表页"""
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
async def scrape_api(url):
async with semaphore:
try:
logging.info('scraping %s', url)
async with session.get(url) as response:
return await response.json()
except aiohttp.ClientError:
logging.error('error occurred while scraping %s', url, exc_info=True)
async def scrape_index(page):
url = INDEX_URL.format(offset=page)
return await scrape_api(url)
"""爬取详情页"""
async def save_data(data):
logging.info('saving data %s', data)
if data:
return await collection.update_one({
'id': data.get('id')
}, {
'$set': data
}, upsert=True)
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
await save_data(data)
async def main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(scrape_index(page))
for page in range(1, PAGE_NUMBER + 1)]
results = await asyncio.gather(*scrape_index_tasks)
# logging.info('results %s', json.dumps(results, ensure_ascii=False, indent=2))
ids = []
for index_data in results:
if not index_data: continue
for item in index_data.get('results'):
ids.append(item.get('id'))
scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id)) for id in ids]
await asyncio.wait(scrape_detail_tasks)
await session.close()
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())
end = time.time()
print('Cost time:',end-start)


















 2035
2035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









