 PySpark入门:SparkContext详解与使用
PySpark入门:SparkContext详解与使用







 本文详细介绍了PySpark中的核心组件SparkContext,包括其创建方式、主要方法如accumulator()、addFile()、broadcast()等,并通过实例演示了如何使用这些方法进行累加器、文件上传、广播变量等操作。SparkContext是PySpark编程的入口,负责作业提交、任务分发和应用注册。
本文详细介绍了PySpark中的核心组件SparkContext,包括其创建方式、主要方法如accumulator()、addFile()、broadcast()等,并通过实例演示了如何使用这些方法进行累加器、文件上传、广播变量等操作。SparkContext是PySpark编程的入口,负责作业提交、任务分发和应用注册。
SparkContext是PySpark的编程入口,作业的提交,任务的分发,应用的注册都会在SparkContext中进行。一个SparkContext实例代表着和Spark的一个连接,只有建立了连接才可以把作业提交到集群中去。实例化了SparkContext之后才能创建RDD和Broadcast广播变量。
-
1.创建方式
- 1.1 通过SparkSession获取SparkContext对象
- 1.2 引入pyspark.SparkContext进行创建,如下代码所示
from pyspark import SparkContext from pyspark import SparkConf conf = SparkConf() conf.set('master','local') sparkContext = SparkContext(conf=conf) rdd = sparkContext.parallelize(range(100)) print(rdd.collect()) sparkContext.stop()上面代码中的Sparkconf对象是Spark里面用来配置参数的对象,后续会着重讲解
-
2.SparkContext的内容(主要是方法讲解)
- 2.1 accumulator()
- 是Sparkcontext上用来创建累加器的方法。创建的累加器可以在各个task中进行累加,并且只能够支持add操作。该方法 支持传入累加器的初始值。这里以Accumulator累加器做1到50的加法作为讲解的例子
-
# 新建accumulator.py文件,内容如下: from pyspark import SparkContext,SparkConf import numpy as np conf = SparkConf() conf.set('master','spark://****:7077') context = SparkContext(conf=conf) acc = context.accumulator(0) print(type(acc),acc.value) rdd = context.parallelize(np.arange(101),5) def acc_add(a): acc.add(a) return a rdd2 = rdd.map(acc_add) print(rdd2.collect()) print(acc.value) context.stop()使用spark-submit accumulator.py运行

-
2.2 addFile()
-
addFile方法添加文件,使用SparkFiles.get方法获取文件 .
-
这个方法接收一个路径,该方法将会把本地路径下的文件上传到集群中,以供运算过程中各个node节点下载数据,路径可以是本地路径也可是hdfs路径,或者一个http,https,或者tfp的uri。如果上传的是一个文件夹,则指定recursize参数为True.上传的文件使用 SparkFiles.get(filename)的方式进行获取。
-
新建addFile.py文件,内容如下: from pyspark import SparkFiles import os import numpy as np from pyspark import SparkContext from pyspark import SparkConf tempdir = '/root/workspace/' path = os.path.join(tempdir,'num_data') with open(path,'w') as f: f.write('100') conf = SparkConf() conf.set('master','spark://hadoop-maste:7077') context = SparkContext(conf=conf) context.addFile(path) rdd = context.parallelize(np.arange(10)) def fun(iterable): with open(SparkFiles.get('num_data')) as f: value = int(f.readline()) return [x*value for x in iterable] print(rdd.mapPartitions(fun).collect()) context.stop()运行spark-submit addFile.py

-
这个例子是使用的本地的文件,接下来我们尝试一下hdfs路径下的文件。 新建hdfs_addFile.py文件,内容如下: from pyspark import SparkFiles import numpy as np from pyspark import SparkContext from pyspark import SparkConf conf = SparkConf() conf.set('master','spark://hadoop-maste:7077') context = SparkContext(conf=conf) path = 'hdfs://hadoop-maste:9000/datas/num_data' context.addFile(path) rdd = context.parallelize(np.arange(10)) def fun(iterable): with open(SparkFiles.get('num_data')) as f: value = int(f.readline()) return [x*value for x in iterable] print(rdd.mapPartitions(fun).collect()) context.stop()运行spark-submit hdfs_addFile.py

需要注意的是addFile默认识别本地路径,若是hdfs路径,需要指定hdfs://hadoop-maste:9000协议、uri及端口信息。借助该方法,在pyspark里任务运行中可以读取几乎任何位置的文件来参与计 算!
-
-
2.3 applicationId
-
用于获取注册到集群的应用的id
-
print('applicationId:',context.applicationId)
-
-
-
2.4 binaryFiles() 读取二进制文件。
-
该方法用于读取二进制文件例如音频、视频、图片,对于每个文件器返回一个tuple,tuple的第一个元素为文件的路径,第二个参数为二进制文件的内容。
在hdfs的/datas/pics文件目录下上传了两张图片,使用binaryFiles读取/datas/pics目录中的二进制图片数据 -
新建binaryFiles.py文件,内容如下: from pyspark import SparkContext ,SparkConf import numpy as np conf = SparkConf() conf.set('master','spark://hadoop-maste:7077') context = SparkContext(conf=conf) rdd = context.binaryFiles('/datas/pics/') print('applicationId:',context.applicationId) result = rdd.collect() for data in result: print(data[0],data[1][:10]) context.stop()运行spark-submit binaryFiles.py

-
-
2.5 .broadcast()广播变量
-
SparkContext上的broadcast方法用于创建广播变量,对于大于5M的共享变量,推荐使用广播。广播机制可以最大限度的减少网络IO, 从而提升性能。接下来例子中,广播一个‘hello’字符串,在各个task中接收广播变量,拼接返回。新建broadcast.py文件,内容如下。
-
from pyspark import SparkContext ,SparkConf import numpy as np conf = SparkConf() conf.set('master','spark://hadoop-maste:7077') context = SparkContext(conf=conf) broad = context.broadcast(' hello ') rdd = context.parallelize(np.arange(27),3) print('applicationId:',context.applicationId) print(rdd.map(lambda x:str(x)+broad.value).collect()) context.stop()运行spark-submit broadcast.py

-
-
2.6 defaultMinPartitions 获取默认最小的分区数
-
print('defaultMinPartitions:',context.defaultMinPartitions)
-
-
2.7 emptyRDD() 创建一个空的RDD ,该RDD没有分区,也没有任何数据
-
-
2.8 getConf() 方法返回作业的配置对象信息
-
-
2.9 setLogLevel() 设置日志级别,通过这个设置将会覆盖任何用户自定义的日志等级设置。取值有:ALL, DEBUG, ERROR, FATAL, INFO, OFF, TRACE, WARN
-
-
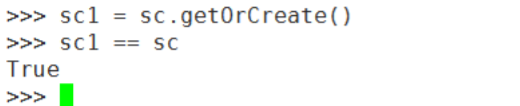
2.10 getOrCreate() 得到或者是创建一个SparkContext对象,该方法创建的SparkContext对象为单例对象。该方法可以接受一个 Sparkconf对象。
-
-
2.11 .textFile() 和 saveAsTextFile() 读取/保存 位于HDFS上的文本文件
-
2.12 .parallelize() 使用python集合创建RDD,可以使用range函数,当然也可也使用numpy里面的arange方法来创建
-
2.13 saveAsPickleFile() 和 pickleFile() 将RDD保存为python中的pickle压缩文件格式。
-
-
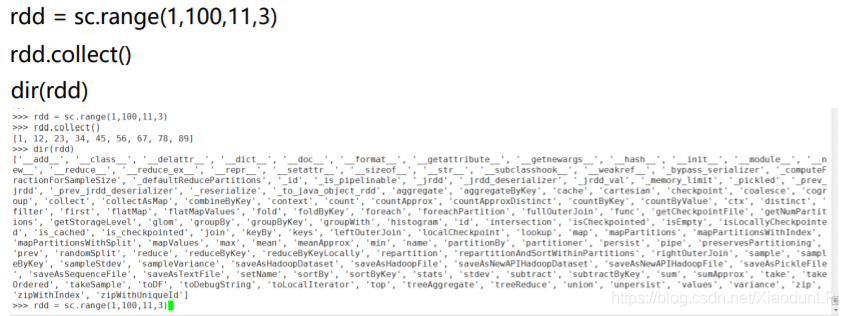
2.14 range(start, end=None, step=1, numSlices=None)
-
按照提供的起始值和步长,创建RDD numSlices用于指定分区数
-
-
-
2.15 runJob(rdd, partitionFunc, partitions=None, allowLocal=False)
-
在给定的分区上运行指定的函数
-
partitions用于指定分区的编号,是一个列表。若不指定分区默认为所有分区运行partitionFunc函数
-

-
-
-
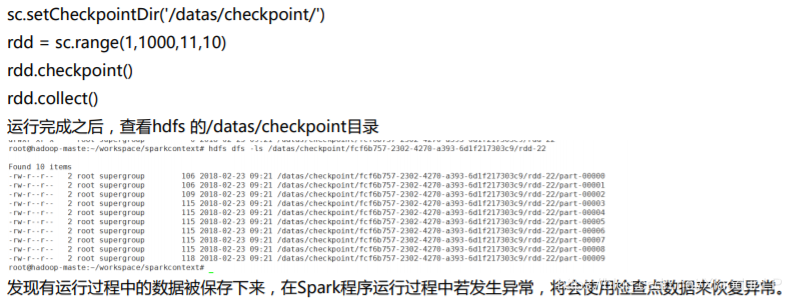
2.16 setCheckpointDir(dirName)
-
设置检查点的目录,检查点用于异常发生时错误的恢复,该目录必须为HDFS目录。
-
-
-
2.17 sparkUser() 获取运行当前作业的用户名
-
-
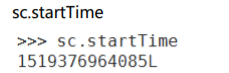
2.18 startTime 返回作业启动的时间
-
-
2.19 statusTracker() 方法用于获取StatusTracker对象,通过该对象可以获取活动的Jobs的id,活动的stage 的id。job的信息,stage的信 息。可以使用这个对象来实时监控作业运行的中间状态数据。
-
-
2.20 stop()方法用于停止SparkContext和cluster的连接。一般在书写程序最后一行都要加上这句话,确保作业运行完成之后连接和cluster 集群断开。
-
2.21 uiWebUrl返回web的url
-
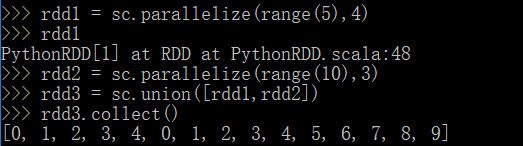
2.22 union(rdds) 用合并多个rdd为一个rdd
-
-
分区不一样依旧可以union操作,这个和rdd的zip操作有区别,后续会讲到
-
-
2.23 version获取版本号
-
- 2.1 accumulator()
























 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









