




 本文介绍了TensorFlow2.0中tf.data API的基础使用,包括从csv文件和tfrecord文件中读取数据,使用decode_csv解析csv,以及repeat、batch、shuffle等操作。详细探讨了如何构建和操作Dataset实例,如将输入参数转换为元组或字典,以及Example的序列化和解析。
本文介绍了TensorFlow2.0中tf.data API的基础使用,包括从csv文件和tfrecord文件中读取数据,使用decode_csv解析csv,以及repeat、batch、shuffle等操作。详细探讨了如何构建和操作Dataset实例,如将输入参数转换为元组或字典,以及Example的序列化和解析。
4_Tf.data_API使用
Dataset表示一系列元素的集合。其中的每个元素可以是单个或者多个Tensor对象。此外,Dataset包含了一系列作用于这些元素上的操作,包含map、flat_map、filter、repeat、shuffle、skip、take等,这类似于Spark中的RDD。
1、文章内容
- Dataset基础API使用
- Dataset读取csv文件
- Dataset读取tfrecord文件
2、API列表
- Dataset基础使用
- tf.dataDataset.from_tensor_slices
- repeat,batch,interleave,map,shuffle,list_files
- csv
- tf.data.TextLineDataset,tf.io.decode_csv
- Tfrecord
- tf.train.FloatList,tf.train.Int64List,tf.train.BytesList
- tf.train.Feature,tf.train.Features,tf.train.Example
- example.SerializeToString
- tf.io.ParseSingleExample
- tf.io.VarLenFeature,tf.io.FixedLenFeature
- tf.data.TFRecordDataset,tf.io.TFRecordOptions
2.1、dataset基本使用方法
- dataset基本使用方法:利用内存中的数据构造dataset,进行变化
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
#import keras
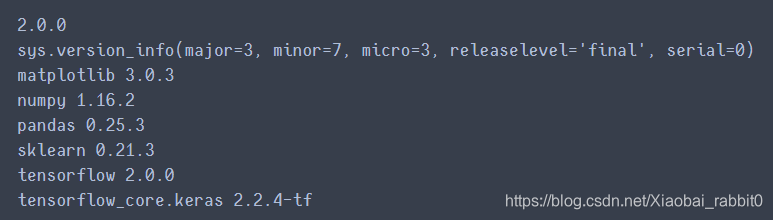
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
#从内存中构建数据集
dataset = tf.data.Dataset.from_tensor_slices(np.arange(10))
print(dataset)

#遍历dataset
for item  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 674
674




 到【灌水乐园】发言
到【灌水乐园】发言







