







大牛数据采集平台
本文是自己开发的数据采集平台,基于datax,xxl-job、selenium等开源技术,实现各种数据源的数据采集,同时优化,实现的xxl-job的dag功能,xxl-job新增DAG任务。系统轻量级、用户易用、便于二次开发。
目前,XXL-JOB 并没有原生支持 DAG(有向无环图)功能。DAG 功能通常用于复杂的任务依赖管理和调度,而 XXL-JOB 主要提供的是简单的定时任务调度功能。
1 系统功能架构如下
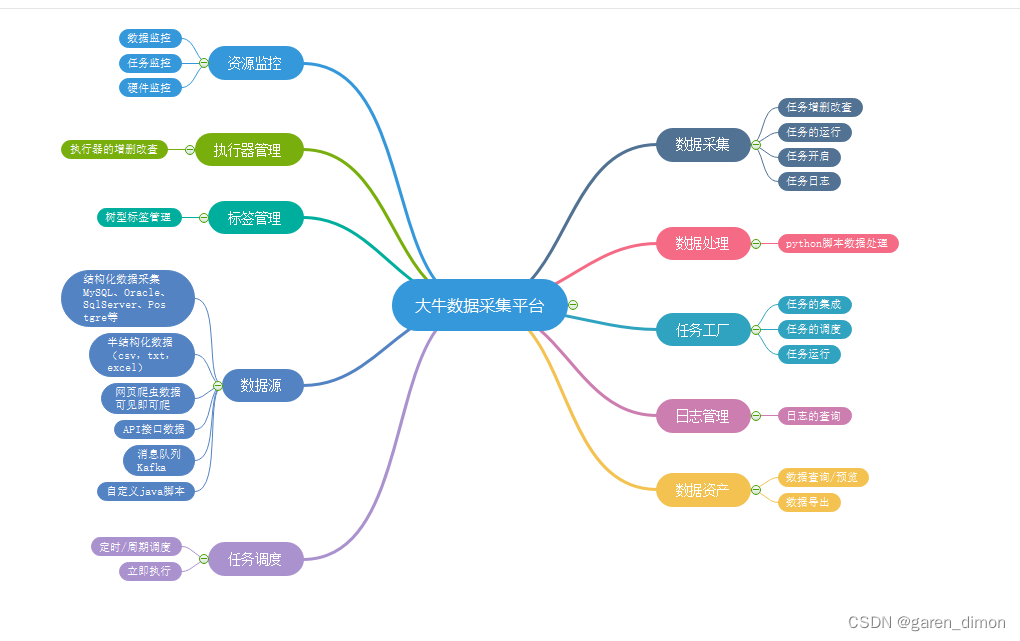
2 系统技术架构如下
2.1 系统调度模块
a 基于xxl-job组件,实现任务调度
b 新增任务DAG 工作流
2.2 数据采集模块:
a 基于datax组件,实现数据的采集
b datax中新增excel采集组件
c) datax中优化csv,txt组件, 支持动过ftp/sftp自动采集或者上传文件方式采集
d 新增api接口组件
e 新增自定义java脚本 -jar包组件
f 新增网页数据采集组件,可视化配置方式&

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









