




 本文详细介绍了希尔排序的原理,包括预排序的过程,以及其与直接插入排序的对比。通过实例演示和时间复杂度讨论,展现了希尔排序在处理大规模数据时的优势。
本文详细介绍了希尔排序的原理,包括预排序的过程,以及其与直接插入排序的对比。通过实例演示和时间复杂度讨论,展现了希尔排序在处理大规模数据时的优势。
鼠鼠最近学习了希尔排序,做个笔记!
希尔排序也是插入排序的一种捏!本篇博客也是用排升序来举例捏!
希尔排序是基于直接插入排序的,是由大佬D.L.Shell提出的。
目录
1.希尔排序
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个 组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。如果不好懂没关系,继续看下面讲解:
鼠鼠上一篇博客介绍了直接插入排序应用时待排序的数组越接近有序,直接插入排序算法的时间效率越高。基于这个,D.L.Shell将希尔排序分为预排序和直接插入排序!
1.1.预排序
对待需排序数组,D.LShell不直接使用直接插入排序。他先搞一搞预排序。
预排序:
首先需排序数组分成gap组(若干组)。举个栗子吧:
让所有距离为gap的数分为一组,如图举例分为了gap=3组:蓝色组、红色组和绿色组。
然后分别将蓝色组、红色组和绿色组的数据进行直接插入排序,这样每组数据排列都有序了,如图:
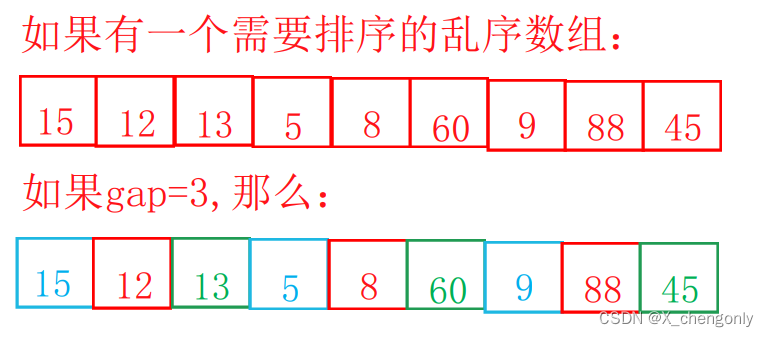

预排序其实大有作用,它能让待排序的乱序数组中大的数据尽量往后靠,让小的数据尽量往前靠,这样的话待排序的乱序数组就更接近有序(我们期待的那种有序,下同)。
那么我们来看看代码的推理过程:
1.我们先搞定蓝色组的直接插入排序的“单趟”:
int end ; int tmp = a[end + gap]; for (end; end >= 0; end -= gap) { if (tmp < a[end]) { a[end + gap] = a[end]; } else { break; } } a[end + gap] = tmp;2.同样我们用循环控制好end就搞定了蓝色组的直接插入排序:
for (int j = 0; j < n - gap; j += gap) { int end = j; int tmp = a[end + gap]; for (end; end >= 0; end -= gap) { if (tmp < a[end]) { a[end + gap] = a[end]; } else { break; } } a[end + gap] = tmp; } }3.但是我们有gap组需要直接插入排序,那么我们再套一层循环循环gap次让不同组直接插入排序即可搞定预排序:
for (int i = 0; i < gap; i++) { for (int j = i; j < n - gap; j += gap) { int end = j; int tmp = a[end + gap]; for (end; end >= 0; end -= gap) { if (tmp < a[end]) { a[end + gap] = a[end]; } else { break; } } a[end + gap] = tmp; } }这种写法是让同一组直接插入排好再排下一组。
鼠鼠下面再展示一种写法,其实与上面写法本质是一样的:
for (int j = 0; j < n - gap; j ++) { int end = j; int tmp = a[end + gap]; for (end; end >= 0; end -= gap) { if (tmp < a[end]) { a[end + gap] = a[end]; } else { break; } } a[end + gap] = tmp; }这种写法其实是多组并列插入排序 ,老爷们体会一下,鼠鼠很难解释捏!
预排序的代码我们暂且写到这里,我们可以看到:gap越大,大的数据越快往后靠,小的数据越快往前靠;但是需排序数组整体越不接近有序。gap越小,则相反;当gap小到等于1时,就是直接插入排序,能让需排序数组直接变成有序的。
1.2.直接插入排序
我们经过一次预排序是不是直接就让需排序数组来直接插入排序呢?
其实不是的,因为经过一次预排序不能保证需排序数组接近有序,只能保证比没有预排序之前更加有序,经过一次预排序就直接让需排序数组来直接插入排序的话效率没有多大提升!
而且如果只进行一次预排序的话,gap就是一个定值,gap是定值是不合适的。如果gap确定是3,但需排序数组数据个数有10000个的话,每组就有300多个数据要排,不合适!

其实主流玩法已尽解决了这些个问题,只要进行多组预排序就行,我们来看希尔排序的完整代码再分析:
//希尔排序排升序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int j = 0; j < n - gap; j ++)
{
int end = j;
int tmp = a[end + gap];
for (end; end >= 0; end -= gap)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}这样子我们将gap设置成变化的,gap会越来越小,当gap不等于1时是预排序。相当于第一轮预排序大概是3个数据为一组排;第二轮预排序大概是9个数据为一组排;第三轮预排序是27个数据为一组排……而且每一轮预排序过后就越有序。
我们再分析发现,gap一定会变成1,那就是让需排序数组直接来一把直接插入排序,这把直接插入排序过后循环结束并且需排序数组就变成有序的了,而且经过了多次预排序最后来一把直接插入排序时间效率会很高!
当然gap如何变化都没有规定,我们也可以写成gap=gap/2……反正要保证最后一次循环的时候gap要等于1,才能保证最后一把是让需排序数组整体进行直接插入排序。
我们来试试希尔排序得不得行:
#include<stdio.h>
//希尔排序排升序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int j = 0; j < n - gap; j ++)
{
int end = j;
int tmp = a[end + gap];
for (end; end >= 0; end -= gap)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
int main()
{
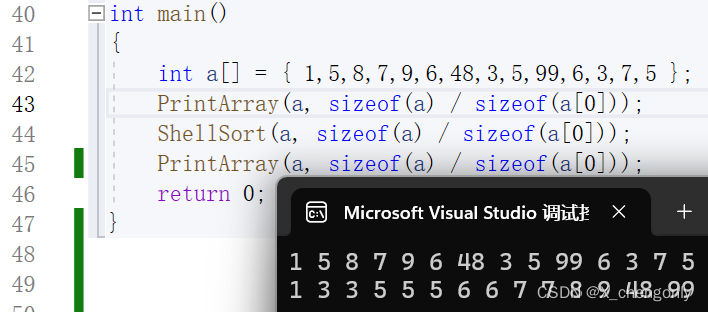
int a[] = { 1,5,8,7,9,6,48,3,5,99,6,3,7,5 };
PrintArray(a, sizeof(a) / sizeof(a[0]));
ShellSort(a, sizeof(a) / sizeof(a[0]));
PrintArray(a, sizeof(a) / sizeof(a[0]));
return 0;
}结果是没问题的!
2.希尔排序的复杂度及稳定性
希尔排序有太多不确定性,所以时间复杂度不好计算,大多数人认为是O(N^1.3)。
希尔排序的空间复杂度明显是O(1)。
希尔排序是不稳定的,因为相同的数据在预排序的时候可能分在不同的组当中,那么就无法保证相对顺序了!
3.希尔排序和直接插入排序的性能比较
也许老爷们会认为希尔排序弄那么多次预排序加一次直接插入排序,时间效率所不定还不如直接插入排序来的好。
其实不然,我们用一个程序比较比较就可以看出结果,这个程序用到一个C语言库里面的函数clock,clock函数的大致作用是获取从系统启动到调用这个clock函数之间的毫秒数。
#include<stdio.h>
#include<time.h>
#include<stdlib.h>
//希尔排序排升序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int j = 0; j < n - gap; j ++)
{
int end = j;
int tmp = a[end + gap];
for (end; end >= 0; end -= gap)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
//直接插入排序排升序
void InsertSort(int* a, int n)
{
for (int j = 0; j < n - 1; j++)
{
int end = j;
int tmp = a[end + 1];
for (end; end >= 0; end--)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
int main()
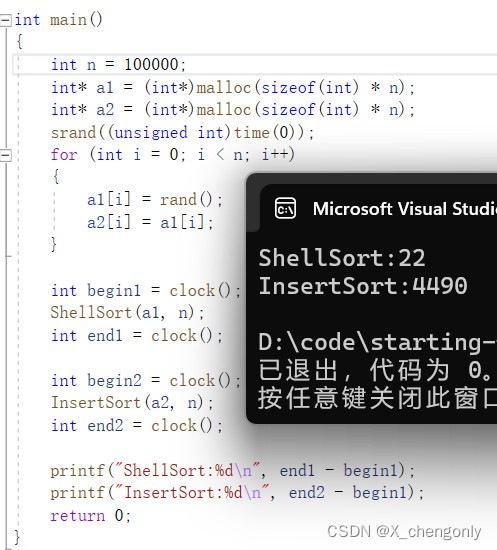
{
int n = 100000;
int* a1 = (int*)malloc(sizeof(int) * n);
int* a2 = (int*)malloc(sizeof(int) * n);
srand((unsigned int)time(0));
for (int i = 0; i < n; i++)
{
a1[i] = rand();
a2[i] = a1[i];
}
int begin1 = clock();
ShellSort(a1, n);
int end1 = clock();
int begin2 = clock();
InsertSort(a2, n);
int end2 = clock();
printf("ShellSort:%d\n", end1 - begin1);
printf("InsertSort:%d\n", end2 - begin1);
return 0;
}我们看到在Debug版本下的结果,排序10万个一模一样的随机数,希尔排序用22毫秒,而直接插入排序用4490毫秒!
感谢阅读!


















 4590
4590




 到【灌水乐园】发言
到【灌水乐园】发言









