import sys
import cv2
import numpy as np
import pytesseract
from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout,
QHBoxLayout, QPushButton, QLabel, QTextEdit,
QGroupBox, QFileDialog, QMessageBox, QProgressBar,
QComboBox, QCheckBox, QTabWidget, QGridLayout)
from PyQt5.QtCore import QTimer, Qt, pyqtSignal, QThread
from PyQt5.QtGui import QImage, QPixmap, QFont
import time
import os
from PIL import ImageFont, ImageDraw, Image
class ImageProcessor:
"""图像处理工具类"""
@staticmethod
def gray_guss(image):
"""图像去噪灰度处理"""
image = cv2.GaussianBlur(image, (3, 3), 0)
gray_image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
return gray_image
@staticmethod
def sobel_edge_detection(gray_image):
"""Sobel边缘检测"""
Sobel_x = cv2.Sobel(gray_image, cv2.CV_16S, 1, 0)
absX = cv2.convertScaleAbs(Sobel_x)
return absX
@staticmethod
def morphology_operations(image):
"""形态学操作"""
# 闭操作
kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 10))
image = cv2.morphologyEx(image, cv2.MORPH_CLOSE, kernelX, iterations=1)
# 腐蚀和膨胀
kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (50, 1))
kernelY = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 20))
# x方向进行闭操作
image = cv2.dilate(image, kernelX)
image = cv2.erode(image, kernelX)
# y方向的开操作
image = cv2.erode(image, kernelY)
image = cv2.dilate(image, kernelY)
# 中值滤波
image = cv2.medianBlur(image, 21)
return image
@staticmethod
def locate_plate_contours(processed_image, original_image):
"""通过轮廓定位车牌"""
contours, hierarchy = cv2.findContours(processed_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for item in contours:
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
weight = rect[2]
height = rect[3]
# 根据轮廓的形状特点确定车牌位置
if (weight > (height * 2.5)) and (weight < (height * 5)):
plate_region = original_image[y:y + height, x:x + weight]
return plate_region, (x, y, weight, height)
return None, None
@staticmethod
def segment_characters(plate_image):
"""车牌字符分割"""
if plate_image is None:
return []
# 图像去噪灰度处理
gray_image = ImageProcessor.gray_guss(plate_image)
# 图像阈值化
ret, binary_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_OTSU)
# 膨胀操作
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (4, 4))
dilated_image = cv2.dilate(binary_image, kernel)
# 查找轮廓
contours, hierarchy = cv2.findContours(dilated_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
words = []
word_images = []
# 对所有轮廓逐一操作
for item in contours:
word = []
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
weight = rect[2]
height = rect[3]
word.append(x)
word.append(y)
word.append(weight)
word.append(height)
words.append(word)
# 排序
words = sorted(words, key=lambda s: s[0], reverse=False)
# 筛选字符轮廓
for word in words:
if (word[3] > (word[2] * 1.2)) and (word[3] < (word[2] * 6)) and (word[2] > 8):
if word[2] < 15:
splite_image = dilated_image[
word[1]:word[1] + word[3], max(0, word[0] - word[2]):word[0] + word[2] * 2]
else:
splite_image = dilated_image[word[1]:word[1] + word[3], word[0]:word[0] + word[2]]
# 确保图像有效
if splite_image.size > 0:
word_images.append(splite_image)
return word_images
class TemplateMatcher:
"""模板匹配器"""
def __init__(self, template_path="templates"):
self.template_path = template_path
self.templates = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U',
'V', 'W', 'X', 'Y', 'Z',
'藏', '川', '鄂', '甘', '赣', '贵', '桂', '黑', '沪', '吉', '冀', '津', '晋', '京', '辽',
'鲁', '蒙', '闽', '宁',
'青', '琼', '陕', '苏', '皖', '湘', '新', '渝', '豫', '粤', '云', '浙']
# 确保模板目录存在
if not os.path.exists(template_path):
os.makedirs(template_path)
print(f"请将模板图片放入 {template_path} 目录中")
def read_directory(self, directory_name):
"""读取目录下的所有图片"""
referImg_list = []
if os.path.exists(directory_name):
for filename in os.listdir(directory_name):
referImg_list.append(os.path.join(directory_name, filename))
return referImg_list
def get_chinese_words_list(self):
"""获得中文模板列表"""
chinese_words_list = []
for i in range(34, 64):
c_word = self.read_directory(os.path.join(self.template_path, self.templates[i]))
chinese_words_list.append(c_word)
return chinese_words_list
def get_eng_words_list(self):
"""获得英文模板列表"""
eng_words_list = []
for i in range(10, 34):
e_word = self.read_directory(os.path.join(self.template_path, self.templates[i]))
eng_words_list.append(e_word)
return eng_words_list
def get_eng_num_words_list(self):
"""获得英文和数字模板列表"""
eng_num_words_list = []
for i in range(0, 34):
word = self.read_directory(os.path.join(self.template_path, self.templates[i]))
eng_num_words_list.append(word)
return eng_num_words_list
def template_score(self, template, image):
"""模板匹配得分"""
try:
template_img = cv2.imdecode(np.fromfile(template, dtype=np.uint8), 1)
template_img = cv2.cvtColor(template_img, cv2.COLOR_RGB2GRAY)
ret, template_img = cv2.threshold(template_img, 0, 255, cv2.THRESH_OTSU)
image_ = image.copy()
height, width = image_.shape
# 调整模板大小
template_img = cv2.resize(template_img, (width, height))
# 模板匹配
result = cv2.matchTemplate(image_, template_img, cv2.TM_CCOEFF)
return result[0][0]
except:
return -999999
def template_matching(self, word_images):
"""对分割得到的字符逐一匹配"""
results = []
# 加载模板
chinese_words_list = self.get_chinese_words_list()
eng_words_list = self.get_eng_words_list()
eng_num_words_list = self.get_eng_num_words_list()
for index, word_image in enumerate(word_images):
if index == 0: # 第一个字符通常是中文
best_score = []
for chinese_words in chinese_words_list:
score = []
for chinese_word in chinese_words:
result = self.template_score(chinese_word, word_image)
score.append(result)
if score:
best_score.append(max(score))
else:
best_score.append(-999999)
if best_score and max(best_score) > -999999:
i = best_score.index(max(best_score))
r = self.templates[34 + i]
results.append(r)
else:
results.append("?")
continue
if index == 1: # 第二个字符通常是英文
best_score = []
for eng_word_list in eng_words_list:
score = []
for eng_word in eng_word_list:
result = self.template_score(eng_word, word_image)
score.append(result)
if score:
best_score.append(max(score))
else:
best_score.append(-999999)
if best_score and max(best_score) > -999999:
i = best_score.index(max(best_score))
r = self.templates[10 + i]
results.append(r)
else:
results.append("?")
continue
else: # 其余字符
best_score = []
for eng_num_word_list in eng_num_words_list:
score = []
for eng_num_word in eng_num_word_list:
result = self.template_score(eng_num_word, word_image)
score.append(result)
if score:
best_score.append(max(score))
else:
best_score.append(-999999)
if best_score and max(best_score) > -999999:
i = best_score.index(max(best_score))
r = self.templates[i]
results.append(r)
else:
results.append("?")
continue
return results
class CardPredictor:
"""车牌识别核心类"""
def __init__(self):
self.plate_color_list = ["蓝牌", "黄牌", "绿牌"]
self.template_matcher = TemplateMatcher()
def train_svm(self):
"""训练SVM模型 - 简化实现"""
print("SVM训练完成")
return True
def img_first_pre(self, img_bgr):
"""图像预处理"""
# 调整图像大小
h, w = img_bgr.shape[:2]
if w > 800:
scale = 800.0 / w
new_w = int(w * scale)
new_h = int(h * scale)
img_bgr = cv2.resize(img_bgr, (new_w, new_h))
# 高斯模糊
img_gauss = cv2.GaussianBlur(img_bgr, (5, 5), 0)
return img_gauss, img_bgr
def img_color_contours(self, img_gauss, img_bgr):
"""基于颜色和轮廓的车牌定位"""
try:
# 转换为HSV颜色空间
hsv = cv2.cvtColor(img_gauss, cv2.COLOR_BGR2HSV)
# 定义车牌颜色范围
lower_blue = np.array([100, 50, 50])
upper_blue = np.array([140, 255, 255])
mask_blue = cv2.inRange(hsv, lower_blue, upper_blue)
lower_yellow = np.array([15, 50, 50])
upper_yellow = np.array([40, 255, 255])
mask_yellow = cv2.inRange(hsv, lower_yellow, upper_yellow)
lower_green = np.array([40, 50, 50])
upper_green = np.array([80, 255, 255])
mask_green = cv2.inRange(hsv, lower_green, upper_green)
# 合并颜色掩码
mask = mask_blue + mask_yellow + mask_green
# 形态学操作
kernel = np.ones((5, 5), np.uint8)
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
# 查找轮廓
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 筛选轮廓
candidates = []
for contour in contours:
area = cv2.contourArea(contour)
if area < 1000:
continue
x, y, w, h = cv2.boundingRect(contour)
aspect_ratio = w / float(h)
if 2.0 <= aspect_ratio <= 5.5:
candidates.append((contour, x, y, w, h))
# 选择最佳候选
if candidates:
candidates.sort(key=lambda x: cv2.contourArea(x[0]), reverse=True)
best_contour, x, y, w, h = candidates[0]
# 提取车牌区域
plate_region = img_bgr[y:y + h, x:x + w]
# 识别车牌颜色
color = self.detect_plate_color(plate_region)
# 识别车牌文本
plate_text = self.recognize_plate_text(plate_region)
return plate_text, plate_region, color
except Exception as e:
print(f"颜色轮廓检测错误: {e}")
return "", None, ""
def img_edge_contours(self, img_gauss, img_bgr):
"""基于边缘检测的车牌定位"""
try:
# 转换为灰度图
gray_image = ImageProcessor.gray_guss(img_gauss)
# Sobel边缘检测
edge_image = ImageProcessor.sobel_edge_detection(gray_image)
# 二值化
ret, binary_image = cv2.threshold(edge_image, 0, 255, cv2.THRESH_OTSU)
# 形态学操作
processed_image = ImageProcessor.morphology_operations(binary_image)
# 定位车牌
plate_region, plate_rect = ImageProcessor.locate_plate_contours(processed_image, img_bgr)
if plate_region is not None:
# 识别车牌颜色
color = self.detect_plate_color(plate_region)
# 使用模板匹配识别车牌文本
word_images = ImageProcessor.segment_characters(plate_region)
if word_images:
plate_text = "".join(self.template_matcher.template_matching(word_images))
else:
plate_text = self.recognize_plate_text(plate_region)
return plate_text, plate_region, color
except Exception as e:
print(f"边缘检测错误: {e}")
return "", None, ""
def detect_plate_color(self, plate_region):
"""检测车牌颜色"""
if plate_region is None or plate_region.size == 0:
return ""
try:
hsv = cv2.cvtColor(plate_region, cv2.COLOR_BGR2HSV)
# 蓝色
lower_blue = np.array([100, 50, 50])
upper_blue = np.array([140, 255, 255])
blue_pixels = cv2.countNonZero(cv2.inRange(hsv, lower_blue, upper_blue))
# 黄色
lower_yellow = np.array([15, 50, 50])
upper_yellow = np.array([40, 255, 255])
yellow_pixels = cv2.countNonZero(cv2.inRange(hsv, lower_yellow, upper_yellow))
# 绿色
lower_green = np.array([40, 50, 50])
upper_green = np.array([80, 255, 255])
green_pixels = cv2.countNonZero(cv2.inRange(hsv, lower_green, upper_green))
max_pixels = max(blue_pixels, yellow_pixels, green_pixels)
if max_pixels == blue_pixels and blue_pixels > 100:
return "蓝牌"
elif max_pixels == yellow_pixels and yellow_pixels > 100:
return "黄牌"
elif max_pixels == green_pixels and green_pixels > 100:
return "绿牌"
else:
return "未知"
except Exception as e:
print(f"颜色检测错误: {e}")
return "未知"
def recognize_plate_text(self, plate_region):
"""使用OCR识别车牌文本"""
if plate_region is None or plate_region.size == 0:
return ""
try:
# 调整大小
h, w = plate_region.shape[:2]
if h < 20 or w < 60:
scale = max(80.0 / w, 30.0 / h)
new_w = int(w * scale)
new_h = int(h * scale)
plate_region = cv2.resize(plate_region, (new_w, new_h))
# 转换为灰度图
gray_plate = cv2.cvtColor(plate_region, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary_plate = cv2.threshold(gray_plate, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 形态学操作
kernel = np.ones((2, 2), np.uint8)
binary_plate = cv2.morphologyEx(binary_plate, cv2.MORPH_OPEN, kernel)
# 使用Tesseract OCR识别
custom_config = r'--oem 3 --psm 8 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ京沪津渝冀晋蒙辽吉黑苏浙皖闽赣鲁豫鄂湘粤桂琼川贵云藏陕甘青宁新'
text = pytesseract.image_to_string(binary_plate, config=custom_config)
# 清理识别结果
text = ''.join(e for e in text if e.isalnum())
return text
except Exception as e:
print(f"文本识别错误: {e}")
return ""
# 车牌识别线程
class PlateRecognitionThread(QThread):
finished = pyqtSignal(dict)
update_progress = pyqtSignal(int)
def __init__(self, image, method="color_contour"):
super().__init__()
self.image = image.copy()
self.method = method
self.predictor = CardPredictor()
self.predictor.train_svm()
def run(self):
try:
self.update_progress.emit(10)
# 图像预处理
img_gauss, img_bgr = self.predictor.img_first_pre(self.image)
self.update_progress.emit(30)
results = {}
# 根据选择的方法进行识别
if self.method == "color_contour" or self.method == "all":
text1, roi1, color1 = self.predictor.img_color_contours(img_gauss, img_bgr)
results["color_contour"] = {
"text": text1,
"roi": roi1,
"color": color1
}
self.update_progress.emit(50)
if self.method == "edge_contour" or self.method == "all":
text2, roi2, color2 = self.predictor.img_edge_contours(img_gauss, img_bgr)
results["edge_contour"] = {
"text": text2,
"roi": roi2,
"color": color2
}
self.update_progress.emit(80)
self.update_progress.emit(100)
self.finished.emit(results)
except Exception as e:
print(f"识别线程错误: {e}")
self.finished.emit({})
# 主窗口类
class LicensePlateApp(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
self.cap = None
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
self.current_frame = None
self.recognition_thread = None
self.detection_method = "all"
def initUI(self):
"""初始化用户界面"""
self.setWindowTitle("车牌识别系统 - 完整优化版")
self.setGeometry(100, 100, 1400, 900)
# 中央窗口部件
central_widget = QWidget()
self.setCentralWidget(central_widget)
# 主布局
main_layout = QHBoxLayout()
central_widget.setLayout(main_layout)
# 左侧面板 - 视频显示
left_panel = QVBoxLayout()
# 原始视频显示
video_group = QGroupBox("原始图像")
video_layout = QVBoxLayout()
self.video_label = QLabel()
self.video_label.setMinimumSize(640, 480)
self.video_label.setAlignment(Qt.AlignCenter)
self.video_label.setText("摄像头未开启")
self.video_label.setStyleSheet("border: 1px solid gray; background-color: #f0f0f0;")
video_layout.addWidget(self.video_label)
video_group.setLayout(video_layout)
left_panel.addWidget(video_group)
# 右侧面板 - 控制按钮和结果
right_panel = QVBoxLayout()
# 创建标签页
self.tab_widget = QTabWidget()
# 颜色轮廓定位标签页
color_tab = QWidget()
color_layout = QVBoxLayout()
color_result_group = QGroupBox("颜色轮廓定位结果")
color_result_layout = QVBoxLayout()
self.color_roi_label = QLabel()
self.color_roi_label.setMinimumSize(300, 150)
self.color_roi_label.setAlignment(Qt.AlignCenter)
self.color_roi_label.setText("颜色轮廓定位车牌区域")
self.color_roi_label.setStyleSheet("border: 1px solid gray; background-color: #f0f0f0;")
color_result_layout.addWidget(self.color_roi_label)
self.color_text_label = QLabel("识别结果: ")
self.color_text_label.setFont(QFont("Arial", 12))
color_result_layout.addWidget(self.color_text_label)
self.color_color_label = QLabel("车牌颜色: ")
self.color_color_label.setFont(QFont("Arial", 12))
color_result_layout.addWidget(self.color_color_label)
color_result_group.setLayout(color_result_layout)
color_layout.addWidget(color_result_group)
color_tab.setLayout(color_layout)
self.tab_widget.addTab(color_tab, "颜色轮廓定位")
# 边缘检测定位标签页
edge_tab = QWidget()
edge_layout = QVBoxLayout()
edge_result_group = QGroupBox("边缘检测定位结果")
edge_result_layout = QVBoxLayout()
self.edge_roi_label = QLabel()
self.edge_roi_label.setMinimumSize(300, 150)
self.edge_roi_label.setAlignment(Qt.AlignCenter)
self.edge_roi_label.setText("边缘检测定位车牌区域")
self.edge_roi_label.setStyleSheet("border: 1px solid gray; background-color: #f0f0f0;")
edge_result_layout.addWidget(self.edge_roi_label)
self.edge_text_label = QLabel("识别结果: ")
self.edge_text_label.setFont(QFont("Arial", 12))
edge_result_layout.addWidget(self.edge_text_label)
self.edge_color_label = QLabel("车牌颜色: ")
self.edge_color_label.setFont(QFont("Arial", 12))
edge_result_layout.addWidget(self.edge_color_label)
edge_result_group.setLayout(edge_result_layout)
edge_layout.addWidget(edge_result_group)
edge_tab.setLayout(edge_layout)
self.tab_widget.addTab(edge_tab, "边缘检测定位")
right_panel.addWidget(self.tab_widget)
# 控制按钮组
control_group = QGroupBox("控制面板")
control_layout = QVBoxLayout()
# 摄像头控制
camera_layout = QHBoxLayout()
self.camera_btn = QPushButton("开启摄像头")
self.camera_btn.clicked.connect(self.toggle_camera)
camera_layout.addWidget(self.camera_btn)
self.capture_btn = QPushButton("捕获并识别")
self.capture_btn.clicked.connect(self.capture_and_recognize)
self.capture_btn.setEnabled(False)
camera_layout.addWidget(self.capture_btn)
control_layout.addLayout(camera_layout)
# 文件操作
file_layout = QHBoxLayout()
self.open_file_btn = QPushButton("打开图像文件")
self.open_file_btn.clicked.connect(self.open_image_file)
file_layout.addWidget(self.open_file_btn)
self.save_btn = QPushButton("保存结果")
self.save_btn.clicked.connect(self.save_result)
file_layout.addWidget(self.save_btn)
control_layout.addLayout(file_layout)
# 检测方法选择
method_layout = QHBoxLayout()
method_layout.addWidget(QLabel("检测方法:"))
self.method_combo = QComboBox()
self.method_combo.addItems(["全部方法", "颜色轮廓定位", "边缘检测定位"])
self.method_combo.currentTextChanged.connect(self.on_method_changed)
method_layout.addWidget(self.method_combo)
control_layout.addLayout(method_layout)
control_group.setLayout(control_layout)
right_panel.addWidget(control_group)
# 识别历史
history_group = QGroupBox("识别历史")
history_layout = QVBoxLayout()
self.history_text = QTextEdit()
history_layout.addWidget(self.history_text)
history_group.setLayout(history_layout)
right_panel.addWidget(history_group)
# 进度条
self.progress_bar = QProgressBar()
self.progress_bar.setVisible(False)
right_panel.addWidget(self.progress_bar)
# 添加到主布局
main_layout.addLayout(left_panel, 2)
main_layout.addLayout(right_panel, 1)
def on_method_changed(self, method):
"""检测方法改变"""
method_map = {
"全部方法": "all",
"颜色轮廓定位": "color_contour",
"边缘检测定位": "edge_contour"
}
self.detection_method = method_map.get(method, "all")
def toggle_camera(self):
"""切换摄像头状态"""
if self.cap is None or not self.cap.isOpened():
# 开启摄像头
self.cap = cv2.VideoCapture(0)
if not self.cap.isOpened():
QMessageBox.warning(self, "错误", "无法打开摄像头")
return
self.timer.start(30)
self.camera_btn.setText("关闭摄像头")
self.capture_btn.setEnabled(True)
else:
# 关闭摄像头
self.timer.stop()
self.cap.release()
self.cap = None
self.video_label.setText("摄像头已关闭")
self.camera_btn.setText("开启摄像头")
self.capture_btn.setEnabled(False)
def update_frame(self):
"""更新视频帧"""
if self.cap and self.cap.isOpened():
ret, frame = self.cap.read()
if ret:
self.current_frame = frame
rgb_image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_image.shape
bytes_per_line = ch * w
qt_image = QImage(rgb_image.data, w, h, bytes_per_line, QImage.Format_RGB888)
self.video_label.setPixmap(
QPixmap.fromImage(qt_image).scaled(
self.video_label.width(),
self.video_label.height(),
Qt.KeepAspectRatio,
Qt.SmoothTransformation
)
)
def capture_and_recognize(self):
"""捕获当前帧并进行车牌识别"""
if self.current_frame is not None:
self.progress_bar.setVisible(True)
self.progress_bar.setValue(0)
self.recognition_thread = PlateRecognitionThread(
self.current_frame,
self.detection_method
)
self.recognition_thread.finished.connect(self.on_recognition_finished)
self.recognition_thread.update_progress.connect(self.update_progress)
self.recognition_thread.start()
def update_progress(self, value):
"""更新进度条"""
self.progress_bar.setValue(value)
def on_recognition_finished(self, results):
"""识别完成回调"""
self.progress_bar.setVisible(False)
# 更新颜色轮廓定位结果
if "color_contour" in results:
result = results["color_contour"]
self.update_result_display(
self.color_roi_label,
self.color_text_label,
self.color_color_label,
result["text"],
result["roi"],
result["color"]
)
# 更新边缘检测定位结果
if "edge_contour" in results:
result = results["edge_contour"]
self.update_result_display(
self.edge_roi_label,
self.edge_text_label,
self.edge_color_label,
result["text"],
result["roi"],
result["color"]
)
# 添加到历史记录
timestamp = time.strftime("%Y-%m-%d %H:%M:%S")
for method, result in results.items():
if result["text"]:
method_name = "颜色轮廓定位" if method == "color_contour" else "边缘检测定位"
self.history_text.append(
f"[{timestamp}] {method_name}: {result['text']} ({result['color']})"
)
def update_result_display(self, roi_label, text_label, color_label, text, roi, color):
"""更新结果显示"""
if roi is not None and roi.size > 0:
roi_rgb = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)
h, w, ch = roi_rgb.shape
bytes_per_line = ch * w
qt_image = QImage(roi_rgb.data, w, h, bytes_per_line, QImage.Format_RGB888)
roi_label.setPixmap(
QPixmap.fromImage(qt_image).scaled(
roi_label.width(),
roi_label.height(),
Qt.KeepAspectRatio,
Qt.SmoothTransformation
)
)
else:
roi_label.setText("未检测到车牌")
text_label.setText(f"识别结果: {text if text else '未识别'}")
color_label.setText(f"车牌颜色: {color if color else '未知'}")
color_map = {
"蓝牌": "#6666FF",
"黄牌": "#FFFF00",
"绿牌": "#55FF55"
}
bg_color = color_map.get(color, "white")
color_label.setStyleSheet(f"background-color: {bg_color}; padding: 5px;")
def open_image_file(self):
"""打开图像文件进行识别"""
file_path, _ = QFileDialog.getOpenFileName(
self, "打开图像文件", "",
"图像文件 (*.jpg *.jpeg *.png *.bmp *.tiff)"
)
if file_path:
image = cv2.imread(file_path)
if image is not None:
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_image.shape
bytes_per_line = ch * w
qt_image = QImage(rgb_image.data, w, h, bytes_per_line, QImage.Format_RGB888)
self.video_label.setPixmap(
QPixmap.fromImage(qt_image).scaled(
self.video_label.width(),
self.video_label.height(),
Qt.KeepAspectRatio,
Qt.SmoothTransformation
)
)
self.current_frame = image
self.capture_and_recognize()
else:
QMessageBox.warning(self, "错误", "无法读取图像文件")
def save_result(self):
"""保存识别结果"""
if not self.history_text.toPlainText():
QMessageBox.warning(self, "警告", "没有可保存的结果")
return
file_path, _ = QFileDialog.getSaveFileName(
self, "保存结果", f"plate_result_{time.strftime('%Y%m%d_%H%M%S')}.txt",
"文本文件 (*.txt)"
)
if file_path:
try:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(f"车牌识别结果\n")
f.write(f"保存时间: {time.strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"\n识别历史:\n")
f.write(self.history_text.toPlainText())
QMessageBox.information(self, "成功", f"结果已保存到: {file_path}")
except Exception as e:
QMessageBox.critical(self, "错误", f"保存失败: {str(e)}")
def closeEvent(self, event):
"""关闭应用程序事件"""
if self.cap and self.cap.isOpened():
self.cap.release()
if self.timer.isActive():
self.timer.stop()
event.accept()
def main():
app = QApplication(sys.argv)
app.setApplicationName("车牌识别系统 - 完整优化版")
app.setApplicationVersion("3.0")
window = LicensePlateApp()
window.show()
sys.exit(app.exec_())
if __name__ == "__main__":
main()分析并优化上面代码,让车牌识别率提升
最新发布




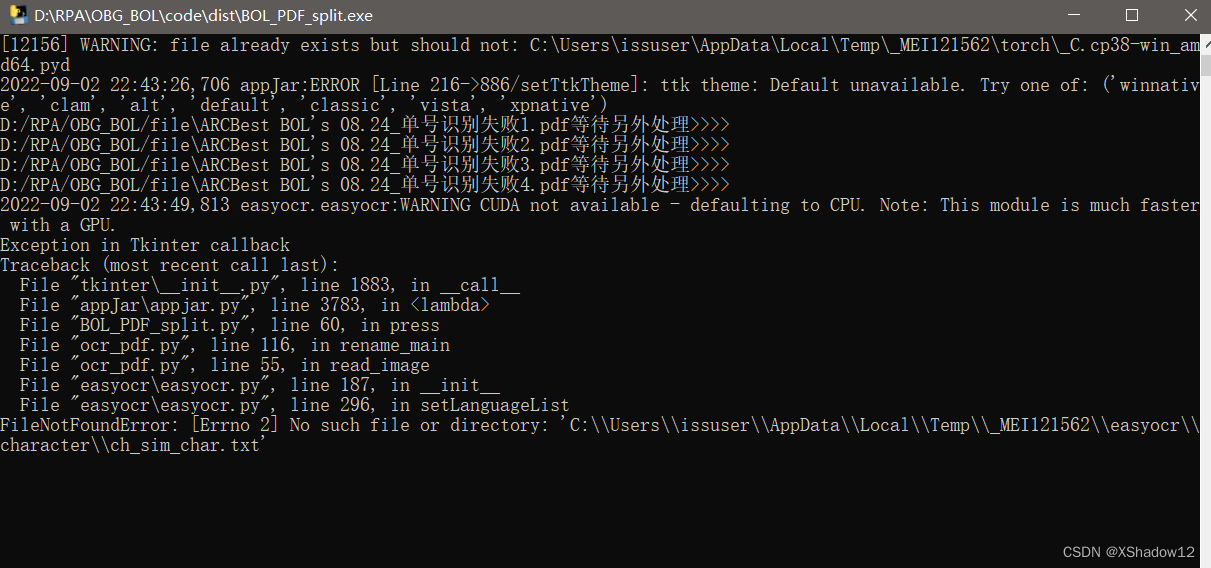
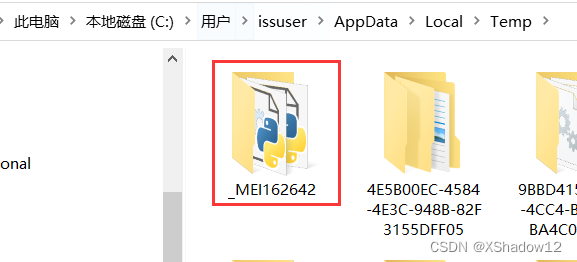
 这篇博客讨论了在使用PyInstaller打包Python应用时遇到的错误,即程序无法找到'ch_sim_char.txt'文件。问题源于可能的旧路径残留和easyocr库的安装路径变更。解决方案包括删除旧文件夹、卸载并重新安装easyocr。对于开发者来说,理解这种路径问题和如何解决它是确保应用程序顺利运行的关键。
这篇博客讨论了在使用PyInstaller打包Python应用时遇到的错误,即程序无法找到'ch_sim_char.txt'文件。问题源于可能的旧路径残留和easyocr库的安装路径变更。解决方案包括删除旧文件夹、卸载并重新安装easyocr。对于开发者来说,理解这种路径问题和如何解决它是确保应用程序顺利运行的关键。

















 9143
9143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









