




一、什么是RAG
RAG(Retrieval-Augmented Generation)
-
检索增强生成,是一种结合信息检索(Retrieval)和文本生成(Genertaion)的技术。
-
RAG技术通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,提高生成结果的时效性和准确性。
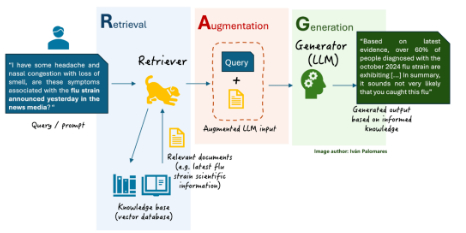
二、RAG的优势
-
减少模型幻觉:通过引入外部的知识,RAG可以减少模型的生成的内容的不可性(一本正经的胡说八道)
-
提高专业领域回答的质量:结合专业知识库,生成更专业的回答
-
解决知识时效性问题:基座模型的数据基本都是静态数据,无法涵盖最新信息,通过RAG工具可以通过外挂知识库实时更新信息
三、RAG的核心流程
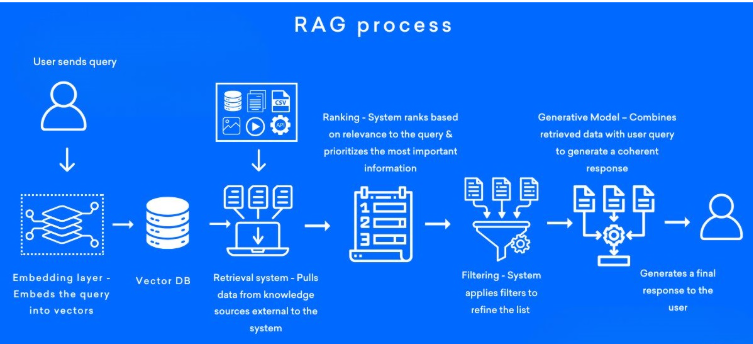
1. 数据预处理
构建知识库:收集本整理文档、PDF、网页等数据源,构建知识库
文档分块:知识库中的文档,将文档分为合适大小的片段
文本量化:使用嵌入模型将文本转化为向量,并存储到向量数据库中
2. 检索阶段
查询处理:
将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段
重排序:
对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入
3. 生成阶段
构建上下文:将从知识库中检索到的相关文档片段与用户问题结合,形成增强的上下文输入
生成回答:基座大模型基于构建的上下文生成最终回答
四、Langchain快速搭建本地知识库检索
1、本地环境准备
本地安装好conda环境
配置好api key (如使用阿里百炼平台)
2、搭建检索流程
加载本地文档,并将文档分割为片段
将分割后的文档,使用嵌入模型量化,并灌入向量数据库
加载本地向量数据库,封装检索方法
构建查询流程:Query ->检索 -> Prompt -> LLM -> 回答
3、导入依赖包
from typing import Tuple, List
from PyPDF2 import PdfReader # 引入PDF阅读器
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI # 引入openai的嵌入模型(可以不需要写)
from langchain_community.embeddings import DashScopeEmbeddings # 引入阿里百练平台提供的嵌入模型
from langchain.text_splitter import RecursiveCharacterTextSplitter # 引入解析器
from langchain_community.vectorstores import FAISS # 引入向量数据库
from dotenv import load_dotenv
from langchain.prompts import PromptTemplate
#加载环境变量
load_dotenv()
API_KEY = os.getenv("DASHSCOPE_API_KEY")
4、读取PDF文件内容
def from_pdf_extract_text_page_number(pdf_name) -> Tuple[str, List[int]]:
"""
从传入的PDF文件中获取文本和对应的页码数,并返回
"""
__text = ""
page_numbers = []
for __page_number,page in enumerate(pdf_name.pages, start=1): # 用于在遍历可迭代对象时同时获取元素的索引和值
extract_text = page.extract_text()
if extract_text:
__text += extract_text
page_numbers.extend([__page_number] * len(extract_text.split("\n")))
else:
logging.warning(f"No text extract on page {__page_number}")
return __text, page_numbers
5、分割文本,并量化存储到本地
def splitter_and_embedding(text_info:str,text_page_number:List[int],save_path:str = None) -> FAISS :
"""
将文本分割,调用嵌入模型,量化
:return:
"""
# 创建文本分割器,将文本内容分割
text_splitter = RecursiveCharacterTextSplitter(
separators= ["\n\n","\n",".","。"," "],
chunk_size= 512,
chunk_overlap= 128,
length_function= len # 也可以使用tokenizer方式
)
# 分割文本
text_chunks = text_splitter.split_text(text_info)
logging.debug(f"text_chunks: {text_chunks}, len(text_chunks): {len(text_chunks)}")
print(f"文本被分为 {len(text_chunks)} 个chunk")
# 使用阿里百炼平台提供的embedding模型
embeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=API_KEY)
# 加载已有的FAISS索引
if save_path and os.path.exists(os.path.join(save_path, "index.faiss")):
# 加载已有的FAISS索引
local_knowledge = FAISS.load_local(folder_path=save_path,embeddings=embeddings,allow_dangerous_deserialization=True)
logging.debug(f"加载本地已经存在的FAISS数据库,从{save_path}路径")
else:
# 如果没有则创建一个新的索引
local_knowledge = FAISS.from_texts(text_chunks,embeddings)
logging.debug(f"已经创建一个新的索引,该索引的长度为{len(text_chunks)}")
# 添加新的文本块到FAISS索引
local_knowledge.add_texts(text_chunks)
# 合并页码信息
page_info_path = os.path.join(save_path, "page_info.pkl")
existing_page_info = {}
if os.path.exists(page_info_path) and os.path.getsize(page_info_path) > 0:
try:
with open(page_info_path, "rb") as f:
existing_page_info = pickle.load(f)
except (EOFError, pickle.UnpicklingError) as e:
print(f"警告: page_info.pkl 文件损坏或为空,将重新初始化。错误: {e}")
existing_page_info = {}
# 生成新页码信息
new_page_info = {chunk: text_page_number[i] for i, chunk in enumerate(text_chunks)}
existing_page_info.update(new_page_info)
local_knowledge.page_info = existing_page_info
# 保存更新后的 FAISS 索引和页码信息
if save_path:
# 确保存在目录
os.makedirs(save_path, exist_ok=True)
# 保存 FAISS 索引
local_knowledge.save_local(folder_path=save_path)
print(f"FAISS 索引已更新并保存到: {save_path}")
# 保存更新后的页码信息
with open(page_info_path, "wb") as f:
pickle.dump(existing_page_info, f) # type ignore
print(f"页码信息已更新并保存到: {page_info_path}")
return local_knowledge
6、加载本地向量数据库信息
def load_local_knowledge(local_path:str,embeddings=None) -> FAISS :
"""
从磁盘加载向量数据库和页码信息
"""
# 判断是否传入embedding,如果没有则填入一个
local_knowledge_load = None
if embeddings is None:
embeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=API_KEY)
# 加载向量数据库
local_knowledge_load = FAISS.load_local(embeddings=embeddings,allow_dangerous_deserialization=True,folder_path=local_path)
logging.debug(f"向量数据已经从{local_path}加载")
# 加载页码信息
page_info_path = os.path.join(local_path,"page_info.pkl")
if os.path.exists(page_info_path):
with open(page_info_path, "rb") as f:
page_info = pickle.load(f)
local_knowledge_load.page_info = page_info
print(f"页码信息已加载:{page_info_path}")
else:
print("未找到页码信息")
return local_knowledge_load
7、定义用户的查询函数,通过知识库进行问题回答
def user_query(query:str, knowledge_bass):
if query is None:
print("请输入需要查询的问题")
return None
else:
# 执行相似度搜索,找到与查询相关的文档
docs = knowledge_bass.similarity_search(query)
# 初始化对话大模型
chat_llm = ChatOpenAI(
api_key=API_KEY,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="deepseek-v3",
streaming=True,
verbose=True
)
#将文档内容合并为上下文
context = "\n".join(doc.page_content for doc in docs)
# 构建提示词模板
template = f"""
以下为与问提相关的上下文信息:{context}
请根据上述信息回答以下问题,如果有额外问题回答不知道即可:
问题:{query}
回答:
"""
# 创建提示词模板
prompt = PromptTemplate.from_template(template)
# 创建llm_chain
llm_chain = (
{"context": lambda x:x["context"],"query": RunnablePassthrough()}
| prompt
| chat_llm
)
# 构建输入数据
input_data = {"context":context,"query":query}
# 回答流式输出
answer_text = ""
for chunk in llm_chain.stream({"query": query, "context": context}):
if hasattr(chunk, "content"):
content = chunk.content
else:
content = str(chunk)
answer_text += content
print(content, end="", flush=True)
# # 记录唯一的页码值
unique_pages = set()
# 显示每个文档块的页码来源
unique_pages = [doc.page_content for doc in docs]
#print("\n\n【来源】")
for page_index,source_info in enumerate(unique_pages,1):
pass
#print(f"<UNK>{page_index}<UNK>,{source_info[:-1]}")
return {
"info": answer_text,
"sources": unique_pages
}
8、函数入口
if __name__ == '__main__':
path = os.path.dirname(__file__)
pdf_path = os.path.join(path,"第2章_RAG技术与应用\\PDF")
print(pdf_path)
save_path = os.path.join(path,"vector_db01")
print(save_path)
directory_name_list = os.listdir(pdf_path)
#遍历目录中所有的pdf文件
for filename in directory_name_list:
if filename.endswith(".pdf"):
file_path = os.path.join(pdf_path,filename)
# 执行pdf读取方法
pdf = PdfReader(file_path)
# 提取PDF的文本和页码信息
text,page_number = from_pdf_extract_text_page_number(pdf)
# 量化文本信息,并同步保存到磁盘
splitter_and_embedding(text,page_number,save_path=save_path) # 不需要其返回的local_knowledge对象
# 加载本地向量数据库
local_knowledge = load_local_knowledge(local_path=save_path)
# 用户提问
query = "客户经理的职责是啥?"
user_query(query, local_knowledge)
query = "flask的框架是啥?"
user_query(query, local_knowledge)
9、本地环境变量
OPENAI_API_KEY="xxxxxxxxxxxxxxxxxxxxx"
OPENAI_BASE_URL="https://api.deepseek.com"
DASHSCOPE_API_KEY="xxxxxxxxxxxxxxxxxxxxxx"

















 2898
2898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









