




The worst《Spring AI》in history
Spring AI 框架简介、核心特性、所支持大模型;RAG 检索增强生成、架构图、流程详述、核心组件类图、核心组件概述;Tool Calling 工具调用、架构图、流程详述、核心组件类图、核心组件概述;MCP 模型上下文协议、架构图、架构橡树、核心组件类图、核心组件概述等。
版本
- jdk:17
- spring:6.2.6
- spring boot:3.4.5
- spring ai:1.0.0-M6
注:有关 AI 相关概念与技术概述请查看 AI 相关概念与技术概述。有关 Spring AI 其它详细信息或最新信息请查看 Spring AI 官网。
注:因 Spring AI 版本迭代较快,故文章内容可能与实际官方文档或源码不符,请以实际文档或源码为准,文章仅作参考。
目录
1 概述
1.1 简介
Spring AI 是由 Spring 开源并维护的 AI 应用开发框架。其致力于企业数据与 API 同 AI 模型的无缝集成,简化生成式 AI 应用的开发。其宗旨是 在整合 AI 大模型时,让应用程序开发变得更简单高效,同时避免不必要的复杂性。
Spring AI 从 LangChain 和 LlamaIndex 等知名 Python 项目中汲取了灵感,但 Spring AI 并非这些项目的移植版本。其始终秉持一个信念:下一代生成式 AI 不应仅局限于 Python 开发者。而应普及到多种编程语言中。
Spring AI 提供了一系列抽象接口,为开发 AI 应用程序提供了基础。并为这些抽象接口提供了多种实现,只需极少的代码改动便可替换相关组件。
注:以上文字摘自 Spring AI 官网。
1.2 核心特性
Spring AI 提供以下核心功能特性:
- 跨 AI 供应商的便携式 API 支持,用于聊天、文生图和嵌入模型,同时支持同步和流式 API 调用,并可访问各模型的专属特性。
- 支持所有主流的 AI 模型供应商,如 Anthropic, OpenAI, Microsoft, Amazon, Google, and Ollama。支持的模型类型包括:聊天补全、嵌入向量、文生图、语音转写、文本转语音、内容审查等。
- 结构化输出,将 AI 模型输出映射到 POJO。
- 支持所有主流的向量存储供应商,如 Apache Cassandra, Azure Cosmos DB, Azure Vector Search, Chroma, Elasticsearch, GemFire, MariaDB, Milvus, MongoDB Atlas, Neo4j, OpenSearch, Oracle, PostgreSQL/PGVector, PineCone, Qdrant, Redis, SAP Hana, Typesense and Weaviate.。
- 跨向量存储的便携式 API 支持,创新性 SQL 风格元数据过滤 API。
- 工具/函数调用:允许模型请求执行客户端工具和功能,从而根据需要访问必要的实时信息并采取行动。
- 可观测性:提供 AI 操作的全链路监控。
- 文档 ETL 框架:专为数据工程设计的文档抽取、转换、加载管道。
- AI 模型评估:提供模型生成内容评估工具,防范模型幻觉。
- Spring Boot 自动配置:为 AI 模型和向量存储提供自动配置。
- ChatClient API:采用类似于 WebClient/RestClient 的流式 API 设计,用于与模型交互。
- Advisors API:封装生成式 AI 通用模式,可实现模型输入输出数据转换、跨模型/场景的可移植能力等。
- 支持聊天记忆持久化和检索增强生成(RAG)。
1.3 支持大模型
可在 Spring AI 官网查看其所支持的大模型,Spring AI 官网模型对比。Spring AI 目前版本对国产大模型的支持度并不高,其更多的是支持兼容 OpenAI API 的大模型的集成。
但是,阿里巴巴基于 Spring AI 推出了 Spring AI Alibaba 项目,其在 Spring AI 的基础上进行了扩展,集成了主流国产大模型,如 DeepSeek、Qwen、DashScope 等,所以,我们可以通过 Spring AI Alibaba 来开发 AI 应用程序。关于 Spring AI Alibaba 的详细信息,请查看 Spring AI Alibaba 官网。
2 RAG 检索增强生成
2.1 架构图
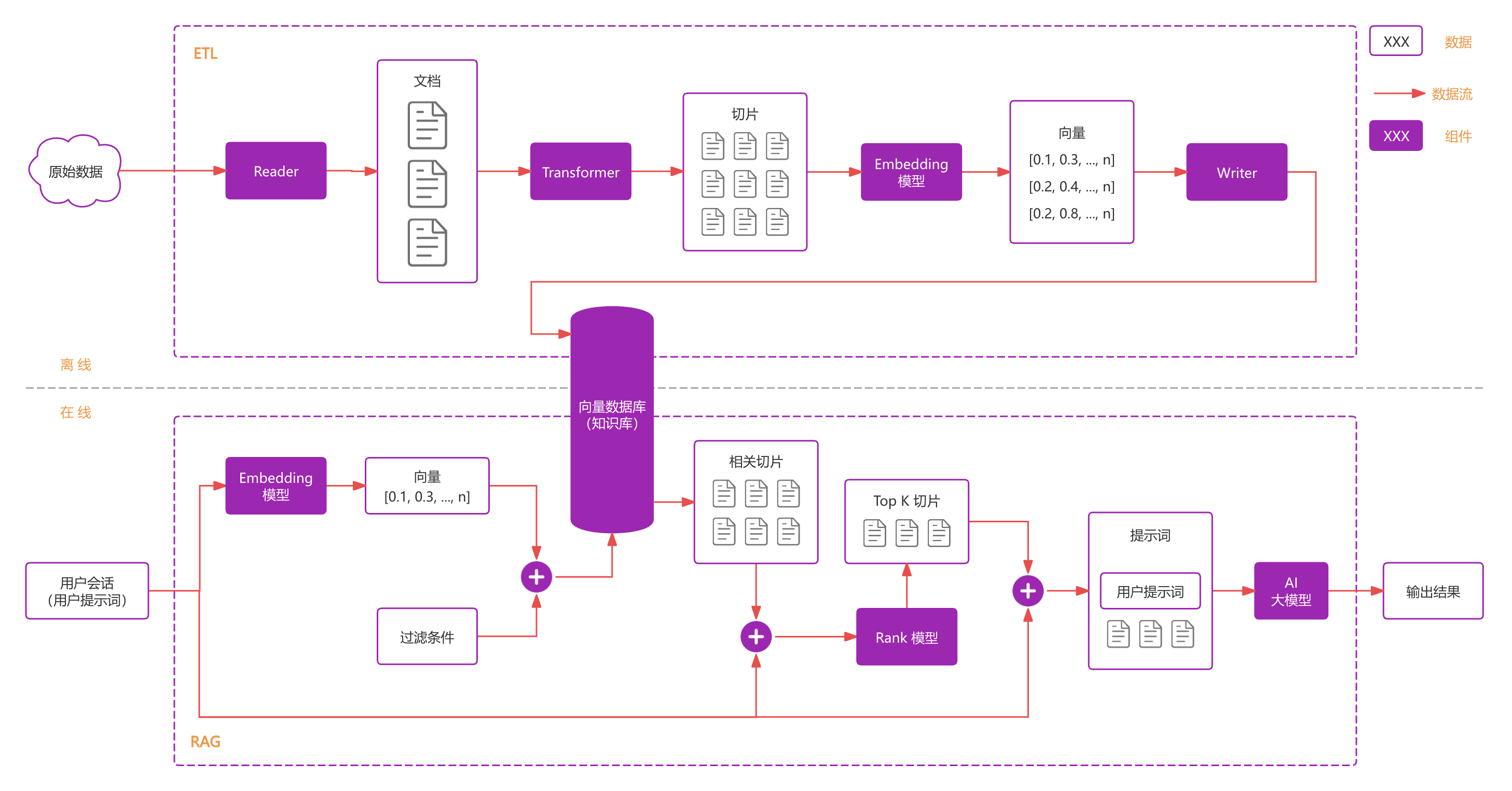
如上图所示,为 Spring AI 中 RAG 相关架构图。RAG 核心工作流程通常包括 数据清洗与切分、向量转换与存储、混合检索与重排、提示增强与引用。其中前两步在 Spring AI 中被称为 ETL,后两步则为 RAG。其中 ETL 的主要任务是将原始数据清洗整理并切分成小而精的知识碎片,同时给知识碎片打上标签/元数据/关键词等,接着通过 Embedding 模型将知识碎片转换成数学向量,最后将知识碎片对应的数学向量与标签存储到向量数据库(ETL 可离线进行);RAG 对应用户与 AI 对话场景,当用户输入问题时,首先通过 Embedding 模型将用户提示词转化成向量,其次使用提示词向量结合相应标签从向量数据库中进行向量相似度检索,然后通过 Rank 模型对检索到的相关切片进行重排序得到最相关的 Top K 切片,再然后将用户提示词与最相关切片结合在一起得到增强后的提示词,最后将增强提示词喂给大模型得到输出结果并引用溯源等操作。简言之,ETL 是对原数据的处理得到知识库,RAG 是对知识库数据的应用。
2.2 流程详述
2.2.1 ETL
- 数据清洗与切分:主要任务是将海量数据转化为小而精的知识碎片。
- 数据清洗:如去除 HTML 标签、无关符号、重复文本,统一数据格式,分类归档数据。
- 数据分块:将清洗后的数据按照一定规则切分成多个知识碎片,并为知识碎片打上标签。切分规则有:按固定长度(如 512 tokens)、按句边界(如换行、章节)、按语义切分、使用 AI 切分等。其要点是要保证知识的完整性和语义的连贯性,若切分结果不尽人意,则可支持人工修改。
- 向量转换与存储:
- 向量转换:通过 Embedding 模型将上一步得到的知识碎片转化为数学向量,使语义相近的内容产生相似的数学特征(如何理解呢?简言之如 “有一说一” 与 “yysy” 这俩长得完全不一样,但其语义一致(即意思一致),所以二者转化后的向量是非常接近的)。
- 向量存储:将向量和标签存入向量数据库并建立快速检索索引(也可使用非向量数据库,当然,成为一名优秀程序员的宗旨是专业的事情交给专业的人做!当然了,最重要的是向量数据库支持高效的相似度检索)。
2.2.2 RAG
- 混合检索与重排:
- 混合检索:包括关键词检索、语义检索、知识图谱检索等。当用户提问时,将用户问题(即用户提示词)也转化成向量,然后结合标签/元数据/关键词等过滤机制与向量的相似度检索(常用相似度算法有余弦相似度、欧氏距离等),从向量数据库(知识库)中得到和用户问题相关的多个切片。这个环节也称 召回。
- 切片重排:通常经过混合检索后会得到与用户问题相关的多个切片,但考虑到数据切分规则与 token 成本问题,此时需要通过 Rank 模型(排序模型)结合用户问题从多个相关切片中得到最相关的 Top K 个切片。
- 提示增强与引用:
- 提示增强:将上一步得到的切片作为知识材料融合到用户提示词中得到增强提示词,并通过压缩工具压缩增强提示词,然后调用 AI 大模型自动生成结果。大模型在生成结果时会自动关联增强提示词中的知识材料。
- 引用与结果处理:得到结果后,可将知识材料作为来源信息添加到结果中,以增强结果的可解释性和可验证性等(即论文中的参考资料);同时也可对结果进行格式化处理等。
2.3 核心组件类图
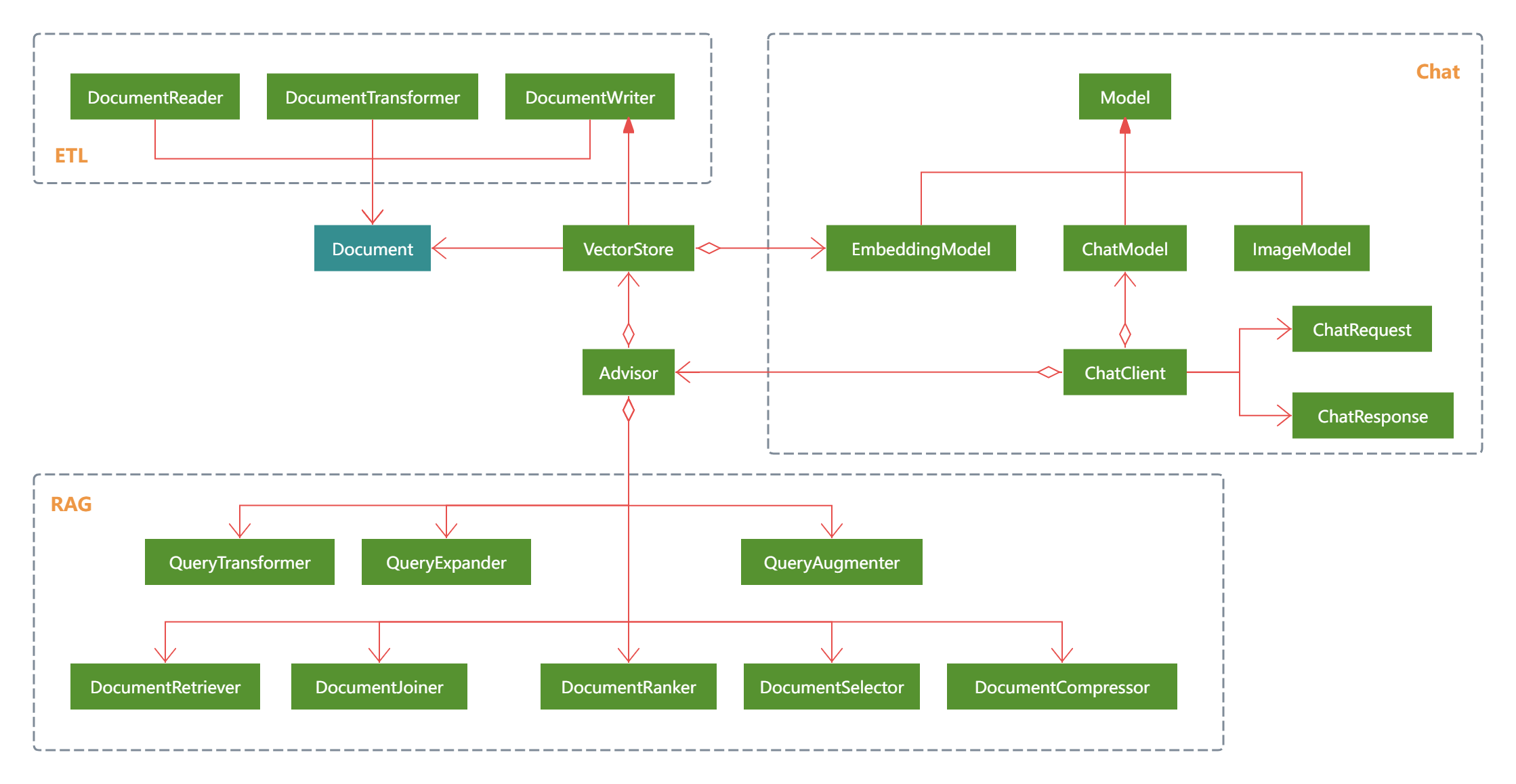
2.4 核心组件概述
2.4.1 Document
文档,是内容与元数据的封装容器,包含文档唯一标识符。单份文档仅可承载文本内容或媒体内容(二者不可共存),专用于在 Spring AI 的 ETL 流水线中对接外部数据源。
2.4.2 ETL
ETL 是 Spring AI 中设计的用来处理原始数据的框架。其通过抽取、转换、加载的流程将原始数据处理为向量存储,以供 RAG 使用。
- DocumentReader:文档读取器(即 E),从多源读取异构文档。部分实现类如下:
- JsonReader:读取 json 数据。
- TextReader:读取 txt 数据。
- MarkdownDocumentReader:读取 markdown 数据。
- JsoupDocumentReader:读取 html 数据。
- DocumentTransformer:文档转换器(即 T),对读取到的文档进行数据清洗、文档转换等处理。部分实现类如下:
- TextSplitter:文本分割器抽象基类,其作用是划分文档内容,使其适配 AI 模型的上下文窗口限制。
- TokenTextSplitter:是文本分割器的一个实现,其使用 CL100K_BASE 编码,基于 token 数将文本分割成块。
- ContentFormatTransformer:统一文档内容格式。
- KeywordMetadataEnricher:关键字元数据增强器, 其使用生成式 AI 模型从文档中抽取关键字添加到文档的元数据中。
- SummaryMetadataEnricher:摘要元数据增强器,其使用生成式 AI 模型为当前文档生成摘要,并添加到文档的元数据中,同时也可以结合当前文档的前后文档生成关联性更强的摘要。
- DocumentWriter:文档写入器(即 L),将转换后的文档以特定格式保存到存储介质中。部分实现类如下:
- FileDocumentWriter:将文档写入文件。
- VectorStore:子类接口,定义了在向量存储介质中管理和查询文档的操作(如添加、删除、相似度检索等)。详见下文。
2.4.3 VectorStore
向量存储接口,继承自 DocumentWriter 接口,定义了在向量存储介质中管理和查询文档的操作(如添加、删除、相似度检索等)。其聚合了 EmbeddingModel(嵌入模型)用来将文档转换为数学向量。部分实现类如下:
- SimpleVectorStore:简单向量存储实现,基于内存实现。
- PgVectorStore:针对 PostgreSQL 数据库实现的向量存储。
2.4.4 Advisor
开箱即用的 API 接口,用来支持 RAG 的通用流程。其本身为定义任何功能方法,全由其子类接口定义。
- CallAroundAdvisor:阻塞式同步环绕顾问,用于增强 ChatModel#call(Prompt) 方法的执行逻辑。
- StreamAroundAdvisor:流式异步环绕顾问,实时拦截数据流片段。
- QuestionAnswerAdvisor:简单问答顾问,即从向量存储中检索问题相关的上下文,并添加到用户提示词的文本中。
- RetrieverAugmentationAdvisor:检索增强顾问,即针对 RAG 流程的开箱即用的实现。
2.4.5 RAG
针对 RAG 流程提供的各种功能接口,其大多都被聚合在 Advisor(实为 RetrieverAugmentationAdvisor 实现类)类中,以便为 RAG 流程的实现提供支持。这些功能的应用时机被设定为三类,即检索前、检索时、检索后。
- 检索前:检索前置处理模块,在检索前预处理用户查询,以获得最佳查询结果。共设计了两个接口,即 QueryTransformer 与 QueryExpander。
- QueryTransformer:查询转换器,用于转换输入查询,使其可以更有效地检索到相关文档。如解决格式不佳的查询、模糊的术语、复杂的词汇或不支持的语言等。
- CompressionQueryTransformer:压缩查询转换器,使用大语言模型将历史会话与当前问题压缩成一个独立的查询,适用于会话历时较长且当前查询与会话上下文相关的场景。
- RewriteQueryTransformer:重写查询转换器,使用大语言模型重写用户问题,以提高查询的质量。适用于用户问题冗余、模糊或包含可能影响检索结果的信息的场景。
- TranslationQueryTransformer:翻译查询转换器,使用大语言模型将用户问题翻译为嵌入模型支持的语言。适用于嵌入模型是用特定语言训练的,而用户查询是不同语言的场景。
- QueryExpander:用于将复杂查询扩展成更简单的查询列表,通过精细化查询来提高查询质量。
- MultiQueryExpander:多查询扩展器,使用大语言模型将一个查询扩展为多个语义上不同的变体,以通过不同的视角来检索到其它上下文信息和提高检索结果的相关性。
- QueryTransformer:查询转换器,用于转换输入查询,使其可以更有效地检索到相关文档。如解决格式不佳的查询、模糊的术语、复杂的词汇或不支持的语言等。
- 检索时:检索处理模块,在检索时通过查询向量存储等系统,来检索与问题最相关的文档。设计的接口包括 DocumentRetriever 和 DocumentJoiner。
- DocumentRetriever:文档检索器,负责从底层数据源(如搜索引擎、向量存储、数据库或知识图谱)检索文档。
- VectorStoreDocumentRetriever:向量存储文档检索器,从向量存储中检索语义上与输入查询相似的文档,同时支持基于元数据、相似性阈值和 top-k 结果的过滤。
- DocumentJoiner:文档聚合器,负责将从多个数据源基于多个查询问题得到的多个文档汇聚成一个文档,同时支持处理重复文档和基于文档分数的重排序。
- ConcatenationDocumentJoiner:相关文档聚合器,负责将从多个数据源基于多个查询问题得到的多个文档汇聚成一个文档,当出现重复文档时将保留第一个出现的文档,且保持文档分数不变。
- DocumentRetriever:文档检索器,负责从底层数据源(如搜索引擎、向量存储、数据库或知识图谱)检索文档。
- 检索后:检索后置处理模块,负责处理检索到的文档,解决诸如 “丢失在中间” 或 “模型上下文长度限制” 等问题,以实现最佳的生成结果。设计的接口包括 DocumentRanker、DocumentSelector、DocumentCompressor。
- DocumentRanker:文档排序器,用于根据文档与查询问题的相关性重排序文档,以将最相关的文档放置在列表顶部,从而解决诸如 “丢失在中间” 之类的问题。与 DocumentSelector 不同的是,该组件不会从列表中删除文档,而是改变文档的顺序/分数。同时,该组件可基于大模型来实现。
- DocumentSlector:文档选择器,用于删除文档列表中与查询问题不相干或冗余的文档,从而解决诸如 “丢失在中间” 或 “模型上下文长度限制” 等问题。与 DocumentRanker 不同的是,该组件不会更改文档的顺序/分数,而是直接删除文档;与 DocumentCompressor 不同的是,该组件不会修改文档内容,儿是直接删除文档。
- DocumentCompressor:文档压缩器,用于压缩每个文档的内容,以减少检索到的信息中的冗余信息,解决诸如 “丢失在中间” 或 “模型上下文长度限制” 的问题。与 DocumentSelector 不同的是,该组件不同删除文档,而是修改文档内容;与 DocumentRanker 不同的是,该组件不会更改文档顺序/分数,而是修改文档内容。
- 生成:生成模块,负责基于用户查询和检索到的文档生成最终的响应结果。
- QueryAugmenter:查询增强器,负责使用额外的数据(检索到的文档)增强用户问题,为大语言模型提供必要的上下文来回答用户问题。
- ContextualQueryAugmenter:上下文查询增强器,使用检索到的文档中的内容来作为上下文以增强用户查询。
- QueryAugmenter:查询增强器,负责使用额外的数据(检索到的文档)增强用户问题,为大语言模型提供必要的上下文来回答用户问题。
2.4.6 Chat
chat 模块包括聊天大模型(ChatModel)、基于聊天大模型构建的聊天客户端(ChatClient)、提示词、消息、会话记忆等功能。
- Model:为调用 AI 大模型设计的基类接口,其提供了一个通用的 API,通过抽象发送请求与接收响应来处理与各种类型的 AI 模型的交互。
- ChatModel:聊天模型通用接口,继承自 Model 接口。
- EmbeddingModel:嵌入模型通用接口,继承自 Model 接口。
- ChatClient:ChatClient 提供了 fluent API 来与 AI 大模型交互,同时支持同步阻塞和异步流式的编程模型,其内部聚合了 ChatModel 示例。
- ChatRequest:请求体。
- ChatResponse:响应体。
2.4.7 ChatClientAutoConfiguration
如果你使用了任何 Spring AI Spring Boot Starters 组件,则其会使用 ToolCallingAutoConfiguration 自动配置类通过 Spring Boot 自动配置机制帮我们自动配置了 ChatClient 相关组件,如:
- ChatClientBuilderConfigurer:用来配置 ChatClient.Builder。
- ChatClient.Builder:用来构建 ChatClient。
- ChatClientInputContentObservationFilter:提示词观察过滤器。
3 Tool Calling 工具调用
3.1 架构图

如上图所示,为 Spring AI 中关于工具调用的架构图,下节为其详细说明。
3.2 流程详述
- 在开发阶段需要编程人员通过 Spring AI 提供的方式(方法方式和函数式接口方式)定义工具(如工具名称/标识、描述/功能、参数结构等),在 Spring AI 应用程序启动时可以通过 Spring Boot 自动配置机制(假设基于 Spring Boot 框架开发)将工具注册到 ioc 容器中。
- Spring AI 应用程序在接收到客户端的用户提示词后,会将服务端的工具定义信息添加在发送到大模型的请求中。
- 大模型接收到 Spring AI 应用程序的请求后首先根据用户提示词推断是否需要调用工具。若需要,则从这组工具定义信息中根据每个工具的描述找到需要调用的工具定义信息,通过其参数结构生成对应的参数,然后将要调用的工具信息和对应参数发送给 Spring AI 应用程序;若不需要,则生成对应内容后返回。
- Spring AI 应用程序在接收到大模型的工具调用请求后,根据工具调用请求中的工具信息和参数去调用对应工具,并将工具调用结果返回给大模型。
- 大模型在接收到 Spring AI 应用程序的工具调用结果后,以该结果作为上下文生成对应内容,并响应给 Spring AI 应用程序。
- Spring AI 应用程序将大模型最终生成的结果返回给客户端。
通过上述过程所知,AI 大模型的工具调用实际是 Spring AI 应用程序完成的,大模型只负责决定是否调用工具以及调用哪些工具,然后由 Spring AI 应用程序完成具体的工具调用。因为工具调用涉及到外部敏感资源(如数据库、文件系统等),所以出于安全性考虑,将工具调用的最终行使权交给应用程序更合理。
3.3 核心组件类图
注:下图基于 spring ai 1.0.0-M6 版本,该版本的官网访问中指出工具的管理和调用都由 ToolCallingManager 工具调用管理器实现,但该版本的实际源码中虽然已有 ToolCallingManager 相关组件,但却没有实际使用,而是由 AbstractToolCallSupport 实现工具的调用,不过其已通过 @Deprecated 注解标记为弃用。故我推测该版本的文档更新了,但是实际源码只更新了部分。因此,为保持跟官方文档同步,在此图中我为 ChatClient 与 ToolCallingManager 添加了聚合的关系(虽然该版本的实际源码中此二者并无关系,但我相信即然文档说了应该使用 ToolCallingManager 且 AbstractToolCallSupport 已被标记为启用,那么在后续版本 ChatClient 与 ToolCallingManager 一定会有关系,且大概率是聚合关系)。
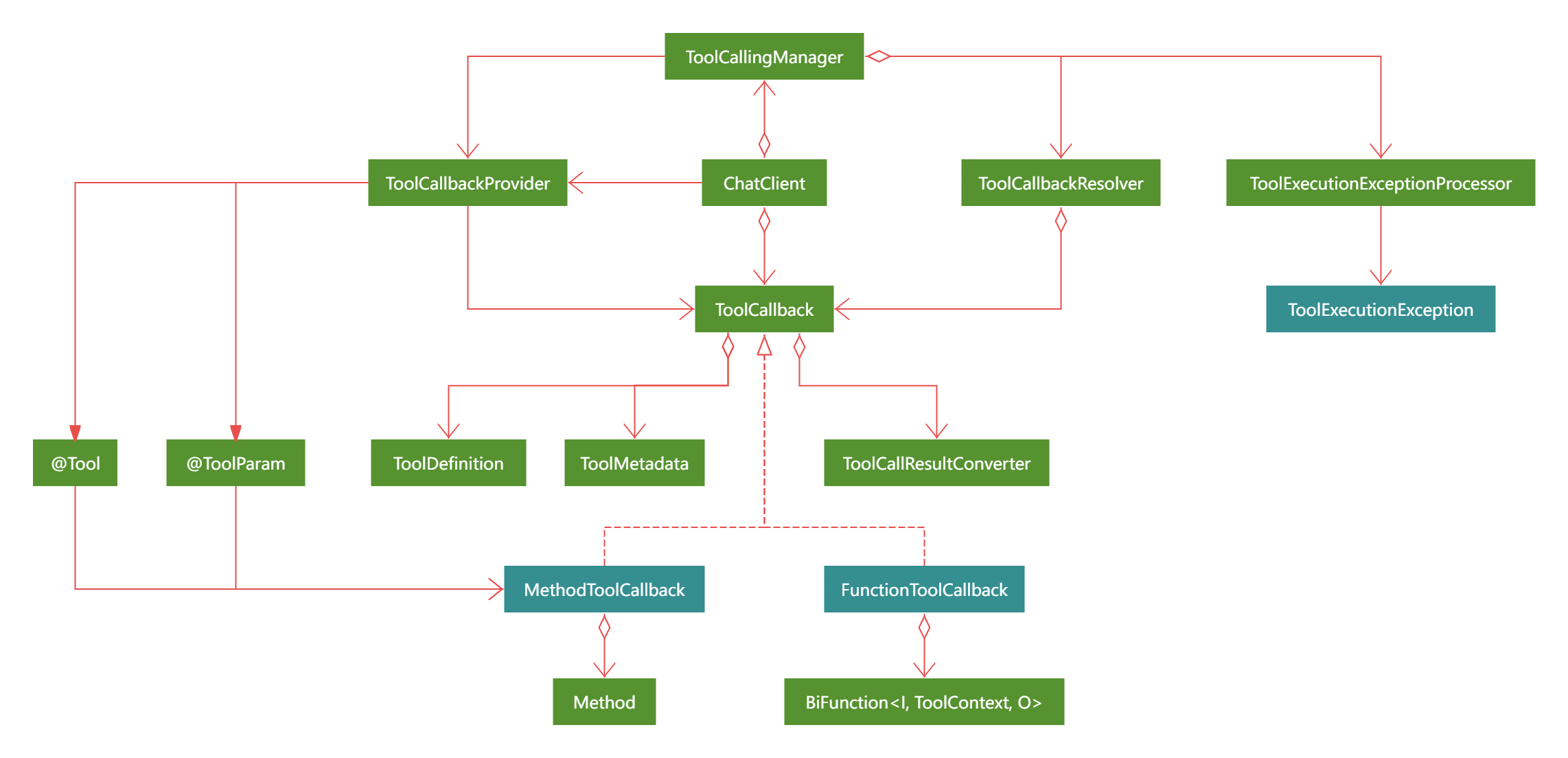
3.4 核心组件概述
3.4.1 ToolCallback
工具模块中用来表示工具,其包含以下属性和行为:
- ToolDefinition:工具定义。
- ToolMetadata:工具元数据。
- ToolCallResultConverter:工具调用结果转换器。
- getName():获取工具名称(实则通过 ToolDefinition#getName() 方法获取)。
- getToolDefinition():获取工具定义信息。
- getToolMetadat():获取工具元数据信息。
- call(String toolInput):调用工具。
Spring AI 为我们提供了两种定义工具的方式,即方法方式和函数式接口方式,分别对应 ToolCallback 接口的两个实现类 MethodToolCallback 和 FunctionToolCallback:
- MethodToolCallback:方法工具的 ToolCallback 实现。其聚合了 Method 实例,即实现工具实际逻辑的方法对应的 Method 对象,最终的工具调用则是通过调用 Method#invoke() 方法实现。对于此种类型的工具定义,Spring AI 提供了声明式和编程式两种工具定义方式:
- 声明式:通过 @Tool 和 @ToolParam 注解标注实际工具方法,通过 MethodToolCallbackProvider 可将被标注方法解析为 MethodToolCallback 对象。
- 编程式:通过反射方式获取实际工具方法的 Method 对象,然后通过 MethodToolCallback.Builder 将其构建为 MethodToolCallback 对象。
- FunctionToolCallback:函数式接口工具的 ToolCallback 实现。其聚合了 BiFunction<I, ToolContext, O> 实例,其支持 Function、Supplier、Consumer、BiFunction 类型的工具定义,这些类型的工具定义最终都会被转换为 BiFunction<I, ToolContext, O> 对象,最终的工具调用则是通过调用 BiFunction#apply() 方法实现。对于此种类型的工具定义,Spring AI 提供了编程式和动态式两种工具定义方式:
- 编程式:即直接实现 Function、Supplier、Consumer、BiFunction 接口,然后通过 FunctionToolCallback.Builder 将其构建为 FunctionToolCallback 对象。
- 动态式:即直接通过 @Bean 注解将函数式内容注册为 Spring Bean,在运行时 SpringBeanToolCallbackResolver 会将该 bean 转换为 FunctionToolCallback 对象。
3.4.2 ToolDefinition
工具模块中用来表示工具定义信息,可通过 ToolDefinition.Builder 进行构建。其默认实现类为 DefaultToolDefinition。其包含以下属性和行为:
- name:工具名称,工具的唯一标识,不可重复,调用工具时用来识别对应工具。不能为空,未指定时默认使用方法名称。
- description:工具描述,描述工具的具体作用,非常重要,大模型将根据此描述来推断工具作用。
- inputSchema:工具入参结构,实为 json 字符串,可通过 JsonSchemaGenerator#generateForMethodInput() 生成。
3.4.3 ToolMetadata
工具模块中关于工具定义或执行的元数据信息,可通过 ToolMetadata.Builder 进行构建。其默认实现类为 DefaultToolMetadata。其只包含 returnRedirect 一个属性,表示是否直接返回,即当工具调用被触发后,是等待工具执行完毕再返回给大模型,还是不等待工具执行完毕直接返回给大模型。因为需要将某些工具的执行结果返回给大模型,大模型将以此为上下文进行生成,而某些工具的执行结果不需要返回给大模型,所以设计了这样一个属性。其默认为 false,即不直接返回,而是等待工具执行结束后再返回。
3.4.4 ToolCallResultConverter
工具模块中用来将工具调用结果转换为 String 对象的转换器接口,其转换结果会被发送给大模型。DefaultToolCallResultConverter 是其默认实现类,其底层依赖 jackson 库中的 ObjectMapper#writeValueAsString() 方法实现。
3.4.5 @Tool 与 @ToolParam
@Tool 与 @ToolParam 是 Spring AI 中提供用来通过声明式方式定义方法工具(MethodToolCallback)的注解。其详述如下:
- @Tool:将类中的某个方法标记为工具。这个方法可以是静态的也可以是非静态的,访问权限是任意的(如公共的、私有的、保护的等)。方法入参可以实任意数量的,参数类型也支持大多数类型(如基本数据类型、POJOs、枚举、集合、数组、键值对等等)。方法返回值也可以是大多数类型,也可以返回为空,当然如果有返回值则其返回值类型必须可序列化。方法所在类可以是顶级父类也可以是内嵌类,同时,该类的访问权限也是任意的。其属性为:
- name:工具名称,若不提供则使用方法名。
- description:方法描述,若不提供则使用方法名。该注解非常重要,是大模型理解工具目的的重要依据,故 Spring AI 强烈建议为工具提供一个详细的描述。
- returnRediect:是否直接返回,上面已详细说明。默认为 false。
- resultConverter:工具调用结果转换器。默认使用 DefaultToolCallResultConverter。
- @ToolParam:为工具方法标记输入参数。其属性如下:
- required:是否必须。默认是必需的。该参数非常重要,建议合理设置。假设其是必须的,但在有些场景下允许为空,那大模型可能会为其编造一个值(make one up),这就有可能造成大模型幻觉问题。
- description:参数描述。也非常重要,是大模型理解参数并为其准备参数值的重要依据,故 Spring AI 强烈建议为参数提供一个详细的描述。
3.4.6 ToolCallbackProvider
为不同来源的工具定义提供 ToolCallback 实例。换言之,其可以将不同来源的(MethodToolCallback 和 FunctionToolCallback 对应的声明式、编程式、动态式)工具定义转换成 ToolCallback 实例,并提供给需要的组件(如 ToolCallingManager、ChatClient 等)。其提供以下两个内置实现类:
- MethodToolCallbackProvider:方法工具提供器,即提供基于方法(MethodToolCallback)的工具的 ToolCallback 实例。其负责解析通过 @Tool 与 @ToolParam 注解声明的工具方法。
- StaticToolCallbackProvider:静态工具提供器,即直接基于 ToolCallback 实例的工具提供器。其是一个简单的实现且是线程安全的。
3.4.7 ToolCallbackResolver
工具调用解析器接口,其只提供一个功能:根据工具名找到找到工具实例(ToolCalback)。其作用于工具调用时,即当大模型决定需要调用工具时,会将要调用的工具信息返回给 Spring AI 应用程序,然后程序通过其返回的信息(主要是工具名称)从程序缓存或 ioc 容器中找到工具实例。所以与其说是解析器,不如把他理解为工具定位/识别器。其内置实现类如下:
- StaticToolCallbackResolver:静态工具解析器,其维护了一个 Map<String, ToolCallback> 集合,用来存放工具实例。解析是直接 get。
- SpringBeanToolCallbackResolver:从 spring ioc 容器中解析工具实例。其主要针对通过函数式接口(FunctionToolCallback)动态式(@Bean)定义的工具。从 ioc 中找到工具实例 bean 后,并负责根据工具定义信息将 bean 转换为对应的类型(如 Function、Supplier、Consumer、BiFunction 等)。
- DelegatingToolCallbackResolver:委托工具解析器。其维护了一个 List< ToolCallbackResolver> 集合,解析时会从所有解析器里挨个儿找。
3.4.8 ToolExecutionExceptionProcessor
工具执行异常处理器,负责处理调用异常。当工具调用异常时,异常会被包装为 ToolExecutionException,然后该处理器对其进行处理,处理结果存在两种情况:要么将异常处理为一条转换消息并发送给大模型,要么将异常抛给调用者(即 Spring AI 应用程序)。
其默认实现类为 DefaultToolExecutionExceptionProcessor,其只有一个布尔类型的属性 alwaysThrow,为 true 表示将异常抛给调用者,为 false 表示将异常处理为消息发送给大模型,默认为 false。
注:如果工具定义是通过编程式实现的,那么为了保证逻辑的健壮性,Spring AI 建议当工具执行逻辑可能会发生错误或异常时,请确保抛出一个 ToolExecutionException 异常。
3.4.9 ToolCallingManager
没错儿,就是她!工具调用管理器,负责根据提供的入参调用工具并返回结果,即管理工具调用的生命周期。其默认实现类为 DefaultToolCallingManager,其包含以下属性和方法:
- ToolCallbackResolver:通过聚合工具解析器实现在工具调用时根据工具名称找到工具实例(也是委托思想)。
- ToolExecutionExceptionProcessor:通过聚合工具执行异常处理器来处理工具调用时的异常。
- resolveToolDefinitions():通过工具调用信息解析工具定义信息。底层也是通过 ToolCallbackResolver 实现。
- executeToolCalls():执行工具调用。
同时,Spring AI 支持自定义工具调用,即自定义实现 ToolCallingManager 接口,并将 ToolCallingChatOptions 类的 DEFAULT_TOOL_EXECUTION_ENABLED 属性设置为 false 即可。
3.4.10 ToolContext
工具上下文信息,用来存储 Spring AI 工具调用相关的上下文信息,这些上下文信息可以配合大模型生成的工具调用参数一起进行工具调用。因为有些时候或有些工具需要访问受保护的数据(如数据库、文件系统等等企业私有数据),然而访问这些数据可能需要相关内部数据(如租户 id、用户 id 等等),出于安全性考虑,这些数据不便暴漏给大模型,所以通过工具上下文实例来持有,并设置给 ChatClient 实例,以便在调用工具的时候使用。
3.4.11 ChatClient
ChatClient 聚合了 ToolCallback 列表、ToolCallbackProvider 实例等。该接口提供了多种方式可通过各种姿势为各种场景提供工具,如直接提供工具方法对象、工具对象、或通过工具提供器提供,如添加默认工具、为某次会话单独添加工具等。同时,这些添加工具的方式也适用于 ChatModel。
虽然目前版本(1.0.0-M6)中 ChatClient 还是通过 AbstractToolCallSupport 类来实现工具调用的,但我相信,不久后的迭代版本中一定会通过聚合 ToolCallingManager 来实现,如若不然,吾便 。。。
3.4.12 ToolCallingAutoConfiguration
如果你使用了任何 Spring AI Spring Boot Starters 组件,则其会使用 ToolCallingAutoConfiguration 自动配置类通过 Spring Boot 自动配置机制帮我们自动配置了工具调用相关组件,如 ToolCallbackResolver、ToolExecutionExceptionProcessor、ToolCallingManager 等组件,当然,你也可以通过注入自定义实现来覆盖默认实现。
4 MCP 模型上下文协议
4.1 架构图

4.2 架构详述
MCP 的核心是 客户端-服务器 架构,一个 MCP 客户端可连接到多个 MCP 服务。
-
MCP 客户端:任何想通过 MCP 访问外部资源的程序、工具等。如 Claude Desktop、IDEs、AI 工具 或应用程序等。
-
MCP 服务端:通过标准化的 MCP 协议向外提供具有特定功能的轻量级应用程序。如地图服务、数据服务、资源搜索服务等等千奇百怪的服务。
MCP 服务可以是本地的,也可以是在线的。公共的 MCP 服务类似于第三方资源,如 maven 库、插件库或第三方 API 等,故可通过 MCP 服务市场发布、获取需要的 MCP 服务。如:MCP.so、GitHub MCP、阿里云百炼 MCP 等。
-
MCP 客户端和服务端之间支持 同步阻塞 和异步非阻塞 两种连接方式。
4.3 核心组件类图
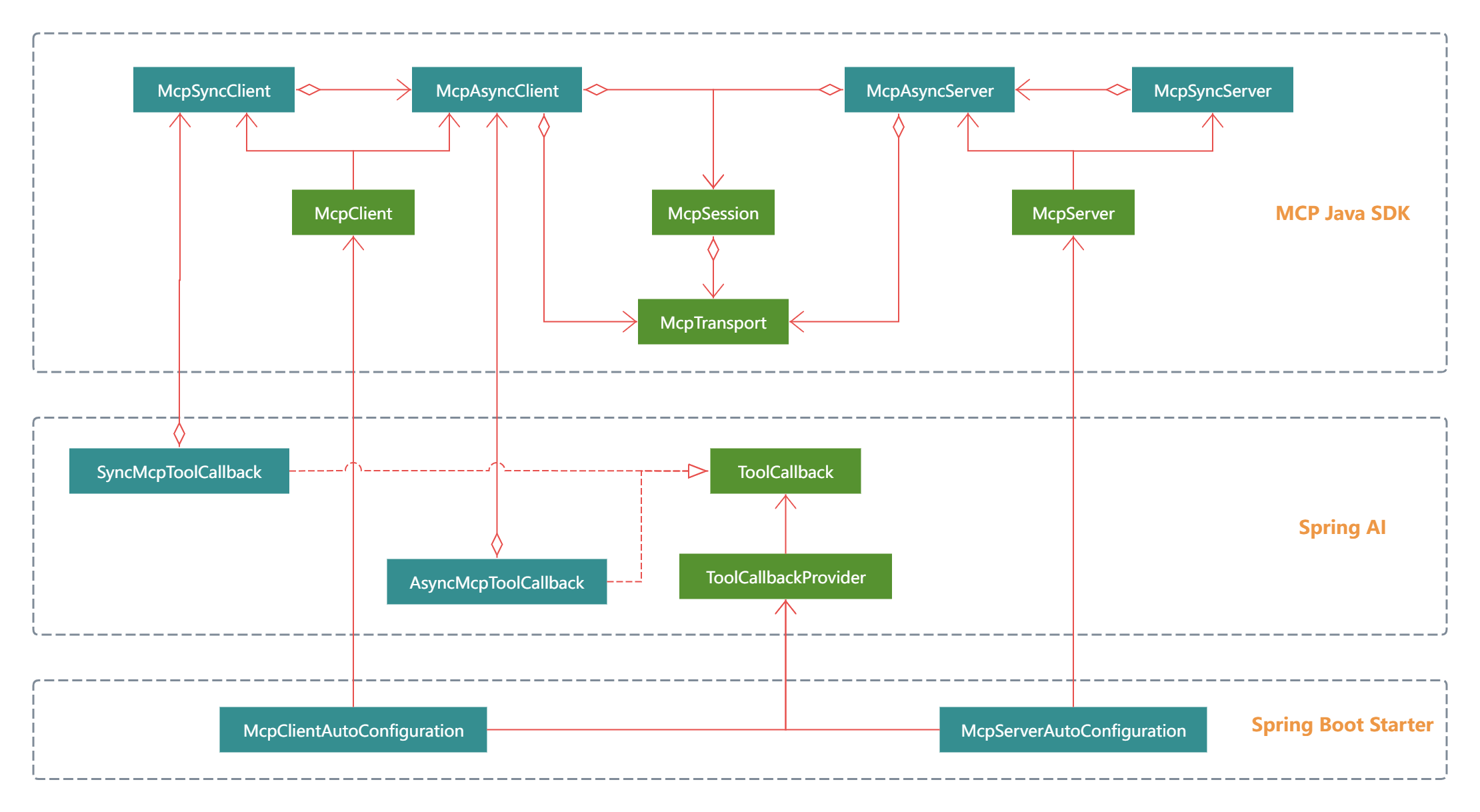
4.4 核心组件概述
4.4.1 McpClient
MCP Java SDK 提供的工厂类,用来创建 mcp 客户端实例。其提供了两种客户端实现,即:
- McpSyncClient:同步阻塞客户端。其通过聚合 McpAsyncClient 实例来实现相应功能。
- McpAsyncClient:异步非阻塞客户端。其通过聚合 McpSession 来实现与服务端的交互,通过聚合 McpTransport 来实现 JSON-RPC 消息的序列化与反序列化。
4.4.2 McpServer
MCP Java SDK 提供的工厂类,用来创建 mcp 服务端实例。其提供了两种服务端实现,即:
- McpSyncServer:同步阻塞服务端。其通过聚合 McpAsyncServer 实例来实现相应功能。
- McpAsyncServer:异步非阻塞服务端。其通过聚合 McpSession 来实现与客户端的交互,通过聚合 McpTransport 来实现 JSON-RPC 消息的序列化和反序列化。
4.4.3 McpSession
MCP Java SDK 提供的 mcp 会话层的实现,其主要负责客户端与服务端之间的通信,如连接、发送请求、消息通知等。其默认实现为 DefaultMcpSession,其通过聚合 McpTransport 实例来实现具体的交互操作。
4.4.4 McpTransport
MCP Java SDK 提供的 mcp 传输层的实现,其主要负责管理传输层连接的的生命周期、客户端-服务端的消息交换、入站与出站的消息处理等。MCP Java SDK 为其提供了两种实现,Spring AI 为其提供了两种实现,分别如下:
- StdioClient/ServerTransport:基于本地进程通信的标准 IO 流的传输层实现,适用于 mcp 客户端与服务端在同一机器上的进程间通信。
- HttpClientSseClient/ServerTransport:基于 java.net.http.HttpClient 的 SSE 传输层实现。
- WebMvcSseClient/ServerTransport:基于 Spring MVC 的 SSE 传输层实现。
- WebFluxSseClien/ServerTransport:基于 Spring Flux 的 SSE 传输层实现。
4.4.5 ToolCallback
关于 ToolCallback 的详细信息请看 3.4.1 章节。
Spring AI 为 mcp 提供了两个实现类,分别是 SyncMcpToolCallback 和 AsyncMcpToolCallback,其分别标识同步类型 mcp 工具和异步类型 mcp 工具。
4.4.6 ToolCallbackProvider
关于 ToolCallbackProvider 的详细信息请看 3.4.6 章节。
Spring AI 为 mcp 提供了两个实现类,分别是 SyncMcpToolCallackProvider 和 AsyncMcpToolCallback。二者皆通过聚合 McpSync/AsyncClient 的方式来获取服务端工具列表,即在客户端实际需要使用 mcp 服务端工具时,通过其聚合的客户端实例向服务端发送获取工具列表请求的方式来获得服务端工具列表,然后将其转换成 Sync/AsyncMcpToolCallback 对象,以供 ChatClient 使用。
在服务端,可将定义好的工具通过 ToolCallbackProvider 注册到 ico 容器中,以便客户端使用。
在客户端,McpClientAutoConfiguration 会自动通过其创建的客户端实例来创建 Sync/AsyncMcpToolCallackProvider 实例,故在需要使用可直接通过依赖注入的方式使用。
4.4.7 McpServerAutoConfiguration
Spring Boot Starter(mcp-server)提供的关于自动配置 mcp 服务端的自动配置类。其主要作用是根据约定大配置的原则创建 mcp 服务端相关的 bean 实例。如:
- 创建 McpTransport 实例,默认为 StdioServerTransport 实现。
- 根据用户注入的 List< ToolCallback> 实例或 ToolCallbackProvider 实例收集服务端工具。
- 根据用户注入的工具、资源、提示词模板等通过 McpServer 构建服务端实例,同时根据 spring.ai.mcp.server.type 配置决定要创建的服务端类型(sync 或 async)。
4.4.8 McpClientAutoConfiguration
Spring Boot Starter(mcp-client)提供的关于自动配置 mcp 客户端的自动配置类。其主要作用是根据约定大于配置的原则创建 mcp 客户端相关的 bean 实例。如:
- 根据配置通过 McpClient 构建客户端实例,并对其进行配置和初始化等操作,同时根据 spring.ai.mcp.client.type 配置决定要创建的客户端类型(sync 或 async)。
- 根据创建的客户端实例来创建 ToolCallbackProvider 实例。



















 81
81

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











