




 博客围绕手写体数字图像展开,包含手写体数据读取与分割代码样例。使用支持向量机(分类)对其进行识别,给出了支持向量机的参数设置,并对识别能力进行评估,得出准确率为 0.9533333333333334。
博客围绕手写体数字图像展开,包含手写体数据读取与分割代码样例。使用支持向量机(分类)对其进行识别,给出了支持向量机的参数设置,并对识别能力进行评估,得出准确率为 0.9533333333333334。
手写体数据读取
from sklearn.datasets import load_digits
#从通过数据加载器获得手写体数字的数码图像数据并储存在digits变量中
digits = load_digits()
#检视数据规模和特征维度
digits.data.shape
(1797, 64)
手写体数据分割代码样例
from sklearn.model_selection import train_test_split
#随机选取75%的数据作为训练样本;其余25%的数据作为测试样本
x_train,x_test,y_train,y_test = train_test_split(digits.data, digits.target, test_size = 0.25, random_state = 33)
#检视训练数据规模
y_train.shape
(1347,)
#检视测试数据规模
y_test.shape
(450,)
使用支持向量机(分类)对手写体数字图像进行识别
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
#仍然需要对训练和测试的特征数据进行标准化
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)
#初始化线性假设的支持向量机分类器LinearSVC
lsvc = LinearSVC()
#进行模型训练
lsvc.fit(x_train,y_train)
LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss=‘squared_hinge’, max_iter=1000,
multi_class=‘ovr’, penalty=‘l2’, random_state=None, tol=0.0001,
verbose=0)
#利用训练好的模型对测试样本的数字类别进行预测,预测结果储存在变量y_predict中
y_predict = lsvc.predict(x_test)
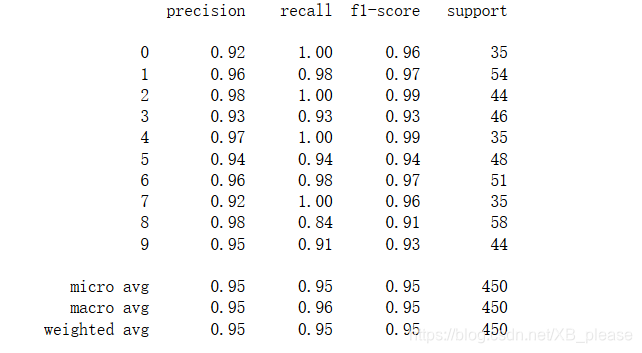
使用支持向量机(分类)对手写体数字图像识别能力的评估
#使用模型自带的评估函数进行准确性测评
print('The Accuracy of Linear SVC is', lsvc.score(x_test, y_test))
The Accuracy of Linear SVC is 0.9533333333333334
from sklearn.metrics import classification_report
#依然使用sklearn.metrics里面的classification_report模块对预测结果做更详细的分析
print(classification_report(y_test, y_predict, target_names = digits.target_names.astype(str)))

















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









