




Linux多线程系列1: 线程理解,控制和页表,CPU缓存的介绍
一.线程概念与理解
OS课本上是这样描述的: 线程是进程内部的一个执行分支,线程是CPU调度的基本单位
注意:不同的OS下,线程的具体实现方式是不同的,我们介绍的是Linux操作系统下线程的实现方式,偶尔会粗粒度地提一下Windows下线程的实现方式
下面我们多个层次来理解一下
1.从需求和时空消耗方面理解线程
线程是进程内部的一个执行分支,那么线程的存在不就是为了让进程内部多一些执行流,从而让该进程能够对代码进行分流执行
1.回想多进程进行代码分流
回想我们曾经在父子进程那里也是为了让父子进程能够执行不同的代码以实现分流,从而创建了子进程
子进程会继承父进程的内核数据结构(task_struct(PCB),mm_struct,页表,进程文件描述符表,信号的三张表等等…)
然后父子进程代码共享,数据以写时拷贝的方式共享
其实只要父进程创建多个进程,并成功等待回收所有进程的话,也能实现线程的需求啊,那为何要有线程呢?
画图理解:
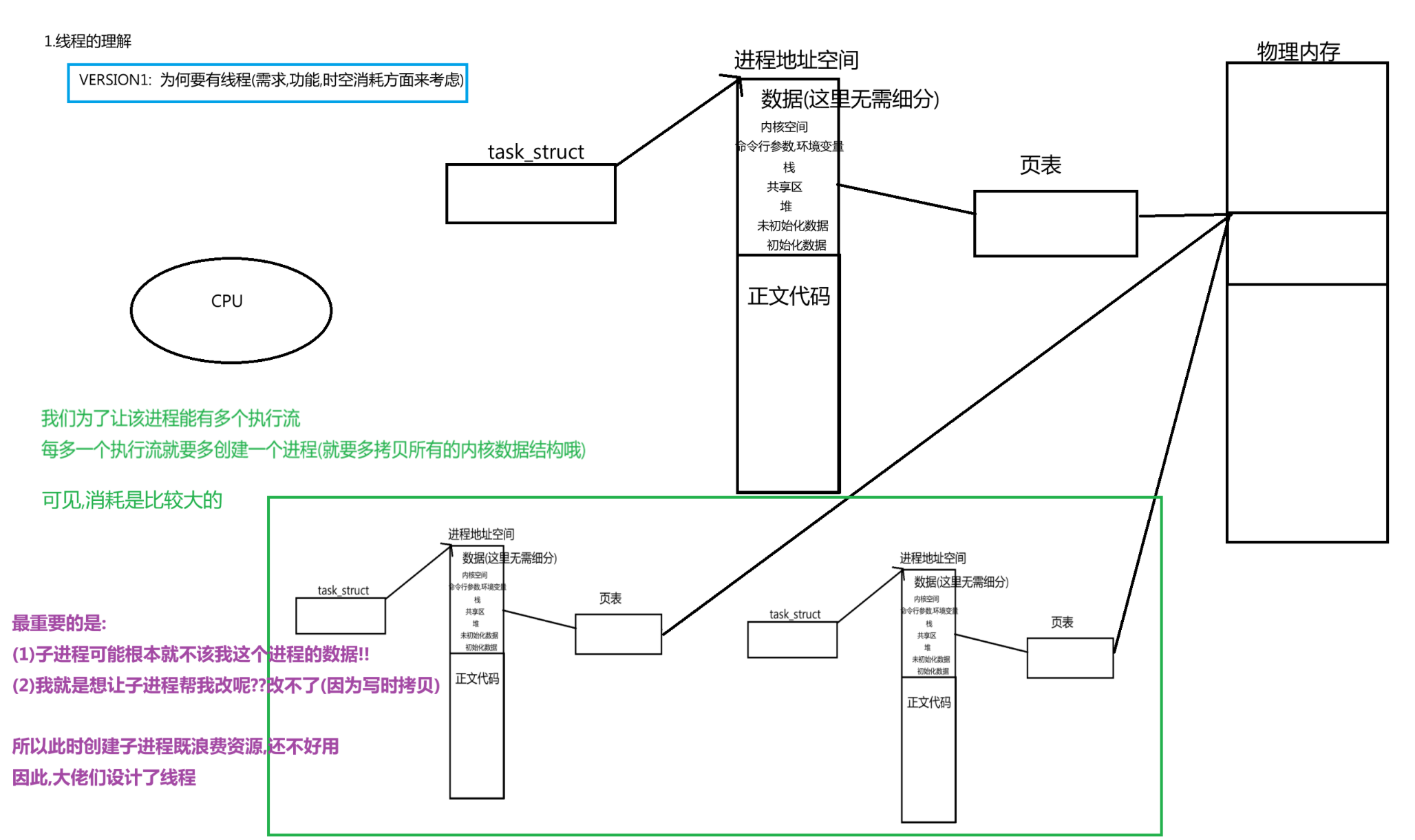
可见多进程进行分流局限性太高,追求效率的OS设计者们势必会解决一下这个问题,因此出现了线程
2.多线程进行代码分流
首先大家要理解的是:
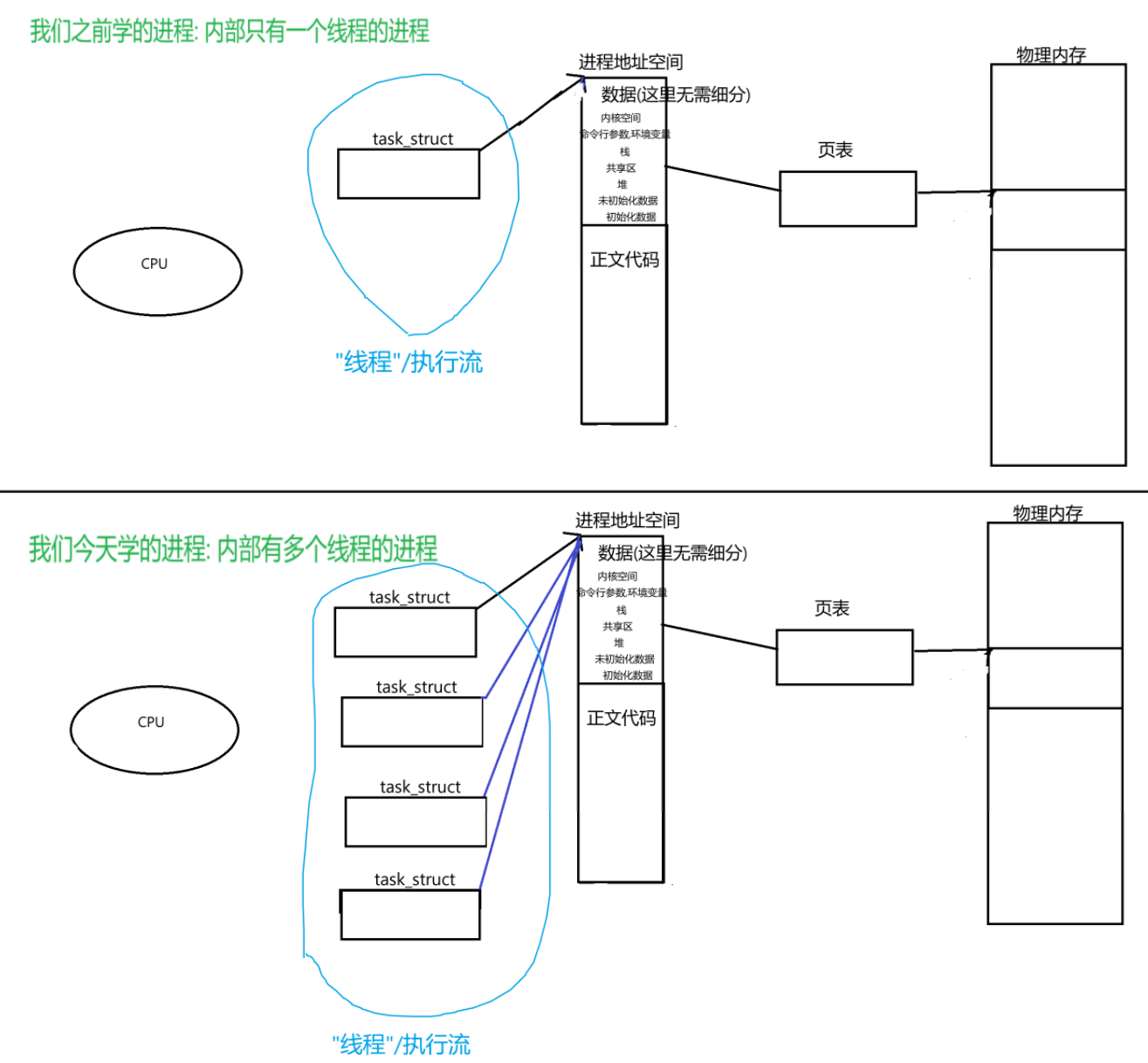
- CPU是按task_struct进行调度的(因为在进程调度的优先级队列当中排队的是task_struct,[回想一下我们曾经介绍的O(1)进程调度算法])
- task_struct访问该进程的代码和数据是通过进程地址空间来访问的(注意:页表是由mm_struct指向的哦)
因此,创建多进程时,我直接只创建新的task_struct,供CPU进行调度,从而实现多执行流
而其他的内核数据结构,代码和数据由我这些多线程所共享不就行了吗?
因此上结论: 进程创建多个线程,只需要为每个线程创建一个新的task_struct,而多个线程间共用其他的内核数据结构,代码和数据
画图理解:

2.从OS管理角度理解线程

Linux复用了进程的内核的数据结构来描述线程,(也就是: 使用进程来模拟线程)
也就是说Linux当中其实根本就没有真正的线程!!(所有的线程都是由进程来进行模拟的)
而Windows就是直接实现了线程的内核数据结构,有TCB等等…[我们学的是Linux,不考虑Windows]
3.对比进程和线程来理解二者
我们从内核角度来理解一下进程:
进程地址空间,页表,进程文件描述符表,信号三张表… 这些都是内核数据结构,都属于系统资源
它们是以进程为单位进行分配的 ->
进程是承担系统分配资源的基本实体
如果对比一下现实世界的话:
我们可以理解为: 一个家庭共享系统资源,这个家庭就是进程
家庭当中如果有多个人: 每个人都是一个线程,都各自执行自己的任务(代码),这个进程就是内部有多个线程的进程
家庭当中如果只有一个人: 这个进程就是内部只有一个线程的进程
4.站在CPU调度的角度理解线程和进程,引出轻量级进程
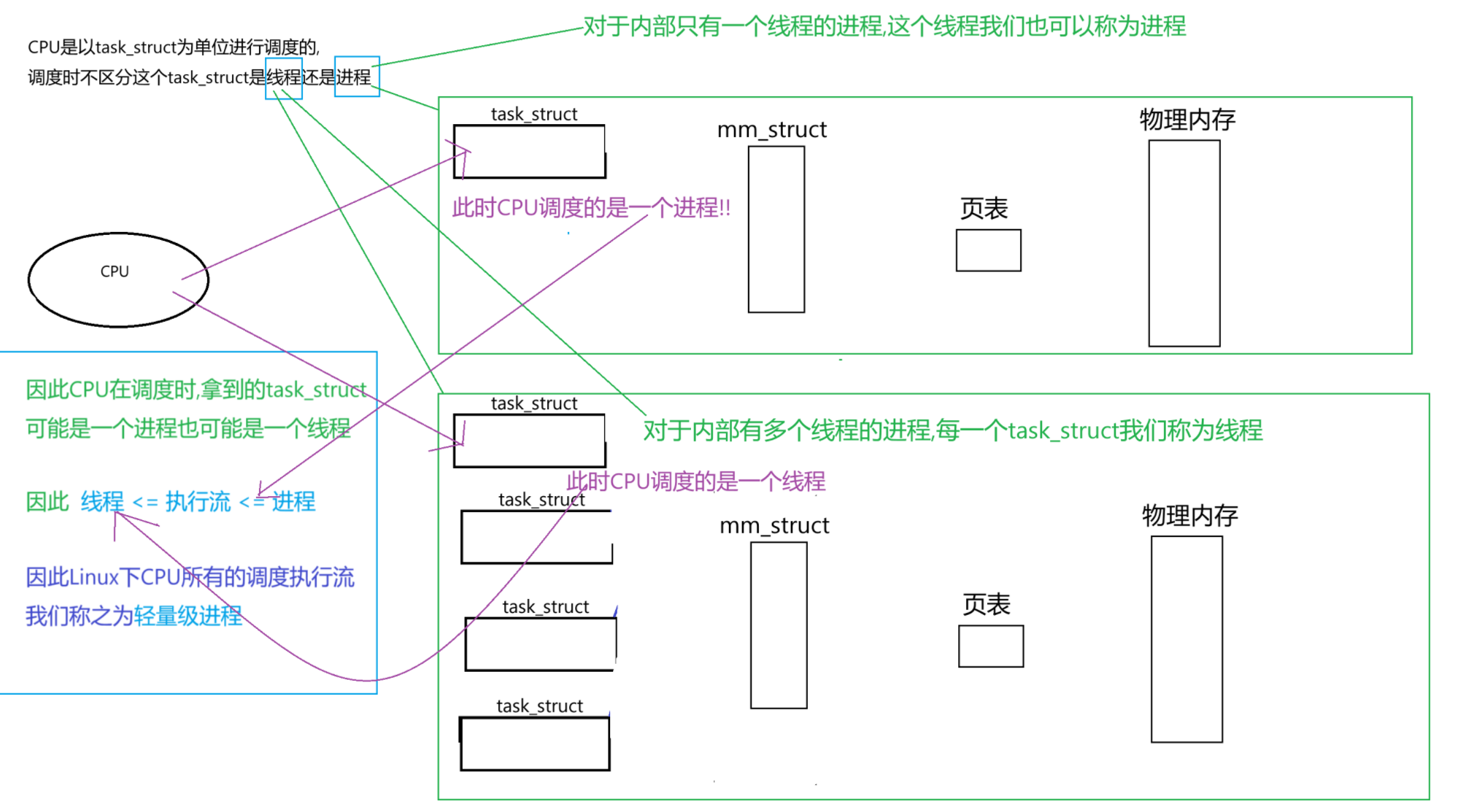
Linux下: CPU所有的调度执行流都是轻量级进程
轻量级进程(LWP : Light Weight Process)是Linux下为了更好地统一进程与线程而设计出的概念
因此,Linux下CPU调度task_struct时,认的不是进程PID,而是LWP !!!
也就是说一个进程内部的所有线程,共有同一个PID,但是LWP不同,从而保证它们都能被CPU所调度
而且直接操作和管理该进程就是对该进程的所有线程进行操作和管理
请注意:多线程被调度时需要瓜分进程的时间片进行调度
为何?
- 时间片也是资源,而这种资源属于进程,因此该资源需要被所有线程所共享,因此需要进行瓜分
- 如果不瓜分的话,一个线程就可以通过无限创建线程的方式来让自己的程序一直被调度,从而使轻量级进程的调度失去公平性
二.页表的介绍与理解线程的代码分流
你刚才说了这些,线程的概念我大概能理解了,一个进程内部的所有线程都共用内核数据结构,代码和数据
我能理解,可是如何实现代码分流呢?
我们父子进程的代码分流是通过fork的返回值进行的?
你线程呢? 也是这样吗?
并不是的,稍后我们介绍线程控制的时候会一起使用线程的接口的
如何实现代码分流呢? 是通过直接让不同的线程执行不同的函数来实现的
我们的顺序: 先回顾磁盘分区的相关知识 -> 介绍OS如何管理内存 -> 回顾可执行程序的编址 -> 介绍页表 -> 理解线程的代码分流
1.回顾磁盘分区的相关知识
磁盘上的每个数据块(Data Block)的大小都是4KB(大多数情况下都是4KB,当然这个不是固定的)
2.介绍OS如何管理内存
我们谈过OS管理进程,内存级文件,磁盘级文件,线程,可是我们还从来没有谈过OS如何管理内存哦
OS要不要管理内存?? 当然要啦 -> 先描述,在组织
磁盘可不可以看作一块超级大的内存? 可以(我们不考虑性能带来的影响…)
也就是说内存可不可以看作一块磁盘? 可以(我们不考虑性能带来的影响…)
因此,我们此时此刻在理解时 可不可以把磁盘的管理借鉴到内存的管理来呢?
可以,直接上结论:
OS进行内存管理的基本单位是页框(page frame)/页帧(page frame),它们的大小也都是4KB(大多数情况下都是4KB,当然这个不是固定的)
先描述:每个页框都是由一个page结构体变量来描述的
struct page
{
int flag;//该页框所处状态
atomic_t count;//原子引用计数值
//其他属性
}
这个flag:
采用位传参的方式进行描述,比如:
#define Kernel 0x1 (该页框属于内核权限,用户态进程无法访问)
#define User 0x2 (该页框属于用户权限,用户态进程可以正确访问)
#define Use 0x4 (该页框已经被使用)
#define NoUse 0x8 (该页框尚未被使用)
#define Lock 0x16 (该页框已经被锁住了[回想一下信号量管理共享内存])
//....其他
这个count:
回想一下管道(内存级文件):当该管道的读写端都把各自的fd关掉了,此时count减为0,该内存的状态从Use改为NoUse,可以被其他进程所使用了
回想一下共享内存: attach时++引用计数,detach时--引用计数
.....
32位平台下,内存大小为4GB,而每个页框都是4KB
那么一个内存共有多少个页框呢?
4GB=4*1024MB=4*1024*1024KB=1024*1024个4KB
而1024*1024=1,048,576个页框,大概是100万
在组织:
一共1,048,576个页框,也就是1MB个大小个page结构体
这里是采用数组的方式进行组织的: struct page memory[1,048,576]; 此时对内存的管理就变成了对数组的管理
其实,就算我们的代码当中只申请了一个char,1个字节,在物理内存就要给我开4KB的空间哦
当父子进程发生写时拷贝时,就算只修改一个char,1个字节,拷贝时就要开4KB的空间把数据全都拷贝过去
(因为OS
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











