




Linux:线程概念 | 线程控制
一、线程概念
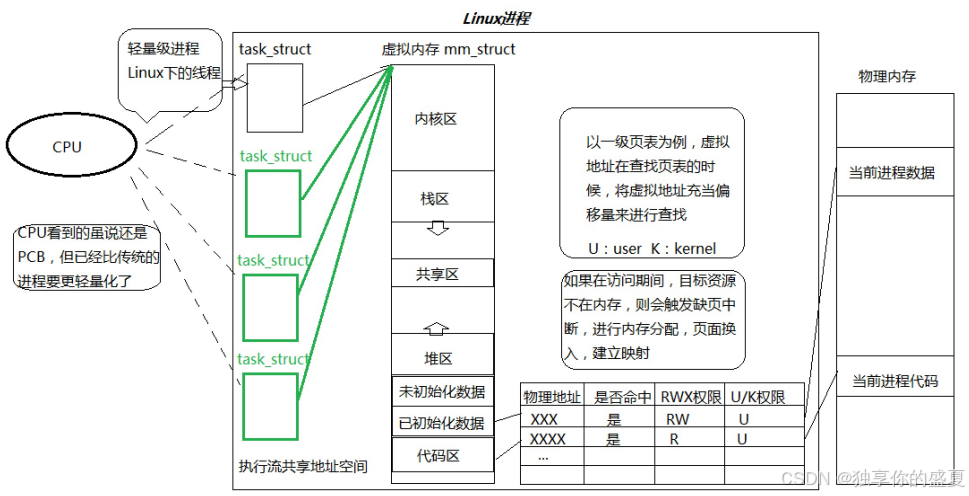
一个进程需要访的大部分资源,诸如自身的代码、数据、new\malloc的空间数据、命令行参数和环境变量、动态库、甚至是系统调用访问内核代码…都是通过虚拟地址空间来访问的。换而言之,进程地址空间是进程的资源窗口!!
进程创建费时费力。在创建时,我们需要为进程创建PCB、地址空间、页表、将进程自身的代码和数据换入内存并建立映射、将进程PCB状态改为R状态、添加带运行队列中… 但如果现在已经存在一个线程了,我仅仅将进程PCB复制多份,然后让所有“进程”PCB全部指向同一个虚拟地址空间。然后通过技术手段,将虚拟地址空间合理分配给每一个“进程”。当CPU调度执行该“”进程“时,只会执行原本进程中的一部分代码和数据,执行我们要执行任务的一部分任务,我们将这种比传统“进程”更加轻量化的进程就称为线程!!
线程是在进程内部执行,比进程更加轻量化的一种执行流!!
二、pthread原生线程库
在Linux中,如果操作系统真的支持线程,此时在计算机中必然存在大量的线程,所以OS需要对线程进行管理。先描述,在组织!!操作系统需要创建struct TCB结构体来描述线程,然后通过链表将所有线程进行链接,组织起来。 并且线程是进程内部的一种执行流,还要将进程和线程进行接藕。更重要的是,线程也需要被调度,也就意味着我们需要为线程调度重新设计一套调度算法。
但其实我们发现线程TCB和进程PCB所需要的属性字段是差不多的,都需要pid、状态、调度优先级…并且两者都是需要被调度被运行的!如果Linux既要支持线程,也需要满足对线程使用的需求。其实是可以用PCB充当TCB,这样我们就可以把系统中所有线程调度和切换的代码在线程层面上全部复用起来。并且对线程的管理工作,也可以直接复用进程管理代码!我们将这种直接创建PCB,然后让所有PCB指向同一个地址空间,在对资源进行分配的线程实现方式称为Linux中线程的实现方案!!我们也将这种线程称为轻量级进程!!
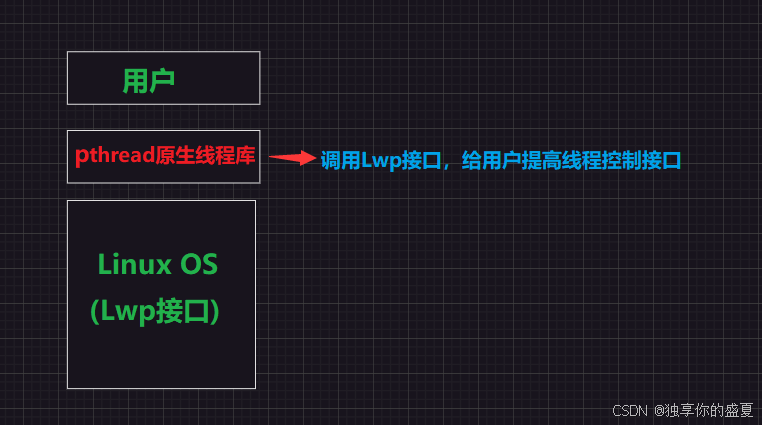
在Linux中没有真正意义上的线程,而是用轻量级进程来充当线程。但这是Linux OS自身的独特设计,对于用户来说只认识进程和线程。所以我们在Linux操作系统和用户之间封装了一层软件层。该软件层向下调用轻量级进程相关接口,向上给用户提供线程的控制接口,而该软件层被称为pthread原生线程库!这也是为啥我们编写线程代码时,在编译阶段需要主动链接pthread库原因!
可以通过ps -aL查看系统线程!
三、线程 VS 进程
- 线程进程内部中一种执行流,线程比进程更加轻量化。(创建、调度切换、删除更加轻量化)
- 线程时CPU调度的基本单位;而进程是资源分配的基本单位。
- 进程拥有独立的地址空间和页表;而线程是共享进程的地址空间和其他资源!
- 进程的栈是由进程地址空间维护;而线程的栈空间是由pthread维护,映射到共享区中的!
3.1 线程切换轻量化原理
CPU在调度执行某行代码时,由于局部性原理,计算机会将该行周围的代码全部加载到CPU cache缓存中。而cache缓存是基于进程,进程切换,chche数据立即失效,需要重新对数据进行热加载,将数据加载到cache缓存中;但对于线程切换来说,下一个线程极有可能还是访问这些代码和数据,大概率是不需要进程切换掉cache缓存中的数据!!(局部性原理也给磁盘加载到内存的预加载提供了理论基础)
除此之外,在CPU中还存在很多寄存器来存储进程/线程的上下文,存在一些寄存器保存的内容执行地址空间和页表。对于线程来说,地址空间和页表是相同的,这也意味着线程切换时我们不需要将所有线程的寄存器全部切换走;只需将少部分保存临时数据的寄存器切换即可!
- 需要切换的寄存器少!
- 不需要重新跟新cache!
3.2 线程私有数据
线程和进程共享大部分数据,诸如代码段、数据段、全局数据等都是共享的。除此外,还包含如下进程资源:
- 共享当前进程文件描述符表
- 每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
- 当前工作目录
- 用户id和组id
除此在外,线程中还存在一些数据是线程私有的,具体如下:
- 线程拥有独立的寄存器硬件上下文!线程是独立被调度的,线程必然拥有独立的上下文,比如运行过程中产生的临时数据。
- 线程都有独立栈结构!‘一般地址空间中的栈属于主线程,然后通过在堆上申请空间,从当其他新线程的栈空间!
- 线程ID、信号屏蔽字、调度优先级、errno等
3.3 线程优缺点
1)、线程优点
- 线程的创建、删除、切换比进程更加简单轻量;线程占用的系统资源比进程更少!
- 对于计算密集型应用,线程可以利用多处理器并行特点,将计算分解到多个线程并行处理,提高效率!
- 对于I/O密集型应用,可以将I/O操作进行重叠,以线程同时等待不同的I/O操作,提高性能!
2)、线程缺点
- 如果线程的数量比处理器多,增加了额外的同步和调度开销,而可用的资源不变,导致性能损失!
- 线程会导致整体程序的健壮性降低。如果存在一些错误导致线程异常,会导致进程整体异常退出!
- 线程缺乏访问控制!进程是访问控制的基本粒度。对于线程,OS中并没有提供相关的方法进行线程访问控制!
- 编写难度高!线程出现问题,通常是很难进行排查的。
四、线程相关函数及功能
4.2 线程创建
【函数接口】:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
Compile and link with -pthread//编译时,需要链接pthread原生线程库
返回值:成功返回0;失败返回错误码
thread:输出型参数,返回线程id。attr:设置线程属性,为NULL表示使用默认属性。start_routine:新线程执行方法的函数地址。arg:传给start_routine函数的参数。- 错误检查:传统的一些函数是,成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。pthreads函数出错时不会设置全局变量errno(而大部分其他POSIX函数会这样做)。而是将错误代码通过返回值返回。pthreads同样也提供了线程内的errno变量,以支持其它使用errno的代码。对于pthreads函数的错误,建议通过返回值判定,因为读取返回值要比读取线程内的errno变量的开销更小
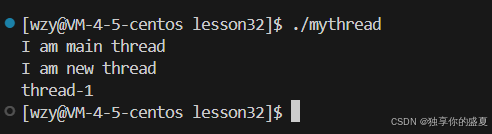
【实例】:
void* ThreadRoution(void* arg)
{
std::cout << "I am new thread" << std::endl;
const char* threadname = (const char*)arg;
std::cout << threadname << std::endl;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, ThreadRoution, (void*)"thread-1");
std::cout << "I am main thread" << std::endl;
sleep(1);
return 0;
}
4.3 获取自身线程id
pthread_t pthread_self(void) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4964
4964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











