






一、简介
Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产。
二、功能比较
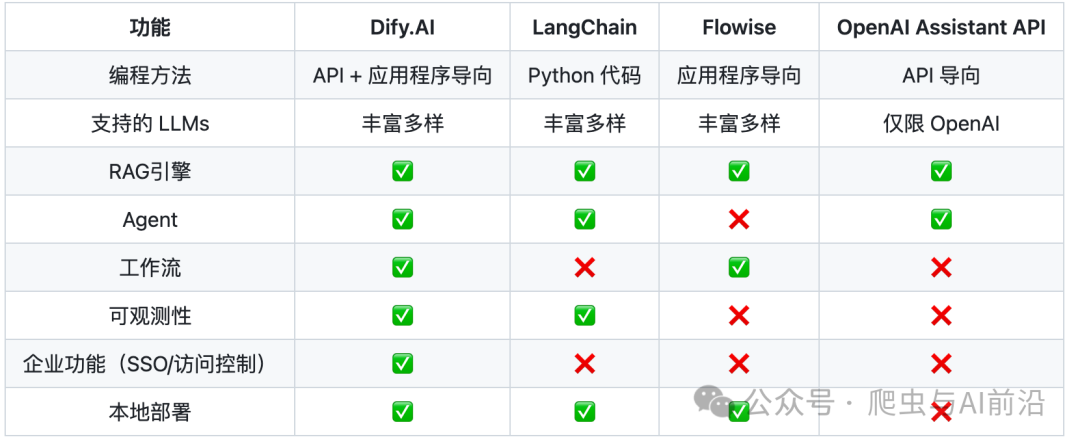
三、使用 Dify
1、Dify 云服务版:任何人都可以零设置尝试。它提供了自部署版本的所有功能,并在沙盒计划中包含 200 次免费的 GPT-4 调用。
2、Dify Premium:是一款 AWS AMI 产品,允许自定义品牌,并可作为 EC2 一键部署到你的 AWS VPC 上。前往 AWS Marketplace 进行订阅并使用,它适合以下场景:
- 在中小型企业内,需在服务器上创建一个或多应用程序,并且关心数据私有化。
- 你对 Dify Cloud 订阅计划感兴趣,但所需的用例资源超出了计划内所提供的资源。
- 你希望在组织内采用 Dify Enterprise 之前进行 POC 验证。
3、Dify 社区版:即开源版本,你可以通过以下两种方式之一部署 Dify 社区版。
- Docker Compose 部署
- 本地源码启动
四、基本信息
1、在线体验:https://dify.ai/
2、开源地址:https://github.com/langgenius/dify
3、官方文档:https://docs.dify.ai/v/zh-hans
五、核心功能列表
1、工作流:在画布上构建和测试功能强大的 AI 工作流程。
2、全面的模型支持:与数百种专有/开源 LLMs 以及数十种推理提供商和自托管解决方案无缝集成,涵盖 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型。 完整的支持模型提供商列表可在此处找到。

3、Prompt IDE: 用于制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)的直观界面。
4、RAG Pipeline: 广泛的 RAG 功能,涵盖从文档摄入到检索的所有内容,支持从 PDF、PPT 和其他常见文档格式中提取文本的开箱即用的支持。
5、Agent 智能体: 可以基于 LLM 函数调用或 ReAct 定义 Agent,并为 Agent 添加预构建或自定义工具。
- Dify 为 AI Agent 提供了50多种内置工具,如谷歌搜索、DALL·E、Stable Diffusion 和 WolframAlpha 等。
6、LLMOps: 随时间监视和分析应用程序日志和性能。您可以根据生产数据和标注持续改进提示、数据集和模型。
7、后端即服务: 所有 Dify 的功能都带有相应的 API,因此您可以轻松地将 Dify 集成到自己的业务逻辑中。
六、Dify 私有化部署
1、系统要求
在安装 Dify 之前,请确保您的机器满足以下最低系统要求:
- CPU >= 2 Core
- RAM >= 4GB
2、快速启动
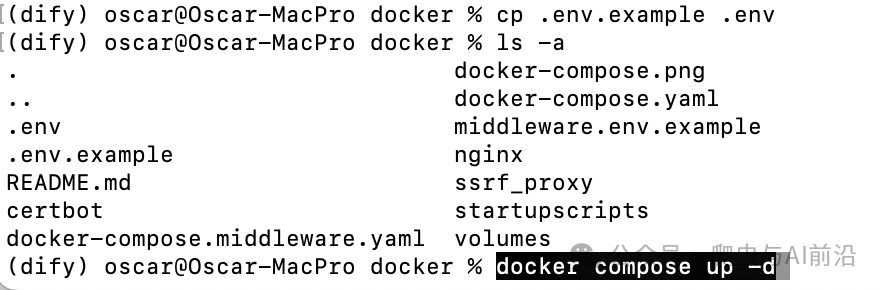
首先,克隆 Dify 源代码至本地,然后进入 docker 目录,复制一份环境变量,采用默认端口,一键启动:
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
如果报错:
“
Error response from daemon: Get “https://registry-1.docker.io/v2/”: EOF
请修改daemon.json文件,设置国内镜像。
"registry-mirrors": [
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com",
"https://cr.console.aliyun.com/"
]
- Linux:vim /etc/docker/daemon.json
- Mac:vim /Users/oscar/.docker/daemon.json
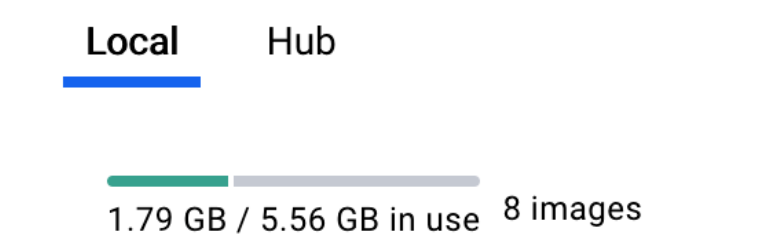
启动成功后,你会发现共有 9 个容器:
- 3 个业务服务:api、worker、web
- 6 个基础组件:weaviate、db、redis、nginx、ssrf_proxy、sandbox

内存占用共计 1790 M,所以至少确保有一台 2G 内存的机器。
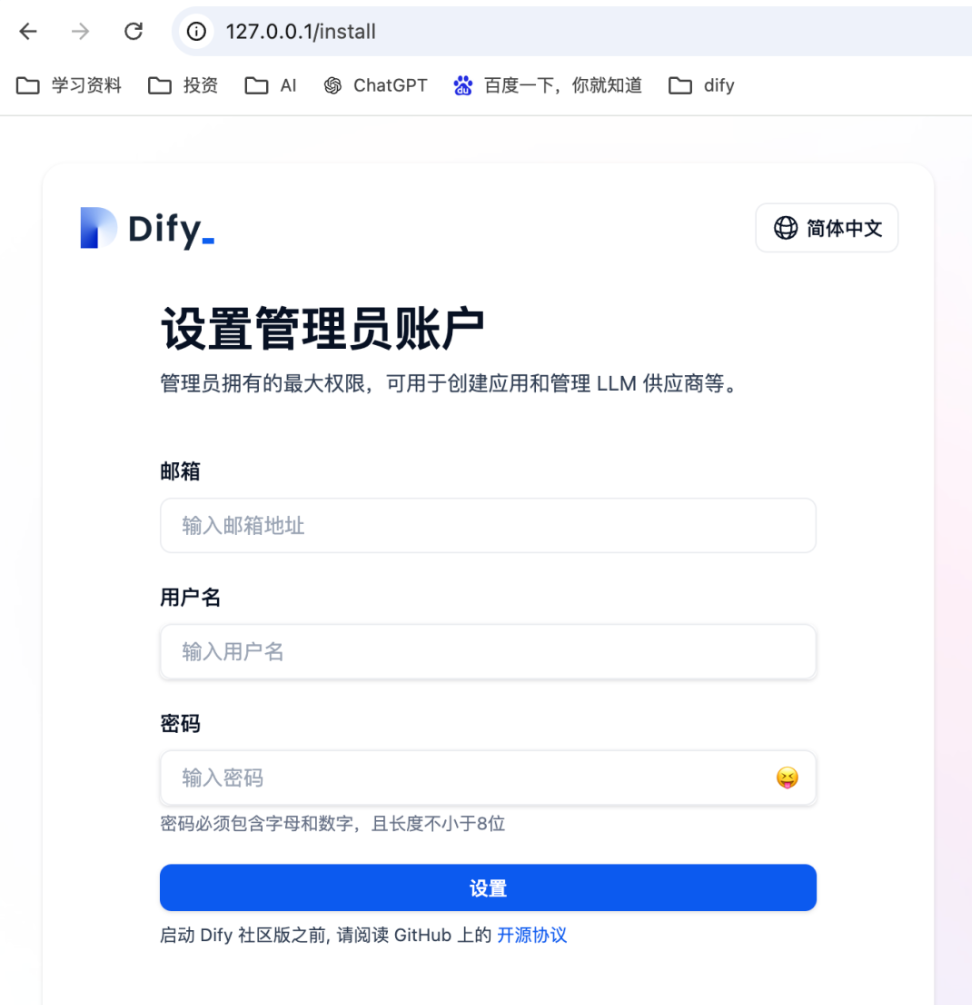
因为项目中启动了一个容器 nginx 将 web 服务转发到 80 端口,所以在浏览器中,直接输入公网 IP 即可,设置一下管理员的账号密码,进入应用主界面。

七、接入大模型
在设置里找到模型供应商,这里已经支持了上百款模型,我这里主要先接入了三款有免费额度的模型。

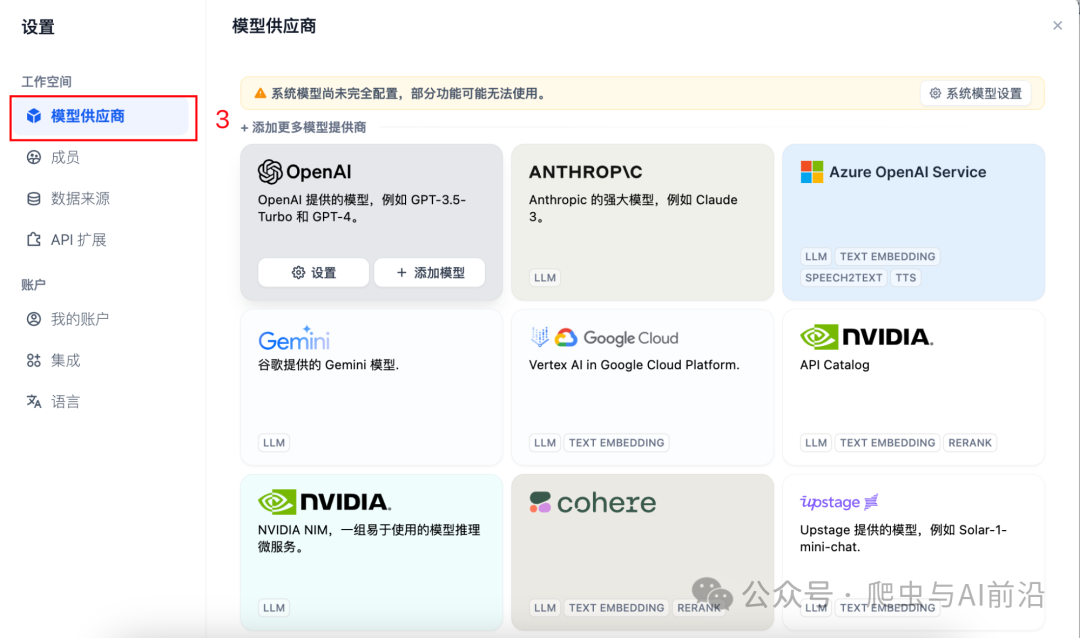 按照提示接入大模型
按照提示接入大模型
八、Dify 接入 Ollama 部署的本地模型
Ollama 是一个本地推理框架客户端,可一键部署如 Llama 2, Mistral, Llava 等大型语言模型。 Dify 支持接入 Ollama 部署的大型语言模型推理和 embedding 能力。
载并启动 Ollama
1、下载 Ollama:访问 https://ollama.ai/download,下载对应系统 Ollama 客户端。
2、运行 Ollama 并与 Llava 聊天
ollama run llava
启动成功后,ollama 在本地 11434 端口启动了一个 API 服务,可通过 http://localhost:11434 访问。
3、在 Dify 中接入 Ollama 在 设置 > 模型供应商 > Ollama 中填入:

-
模型名称:llava
-
基础 URL:http://127.0.0.1:11434,此处需填写可访问到的 Ollama 服务地址。
(1)、若 Dify 为 docker 部署,建议填写局域网 IP 地址,如:http://192.168.1.100:11434 或 docker 宿主机 IP 地址,如:http://172.17.0.1:11434。
(2)、若为本地源码部署,可填写 http://localhost:11434。
-
模型类型:对话
-
模型上下文长度:4096
-
模型的最大上下文长度,若不清楚可填写默认值 4096。
-
最大 token 上限:4096:模型返回内容的最大 token 数量,若模型无特别说明,则可与模型上下文长度保持一致。
-
是否支持 Vision:是(当模型支持图片理解(多模态)勾选此项,如 llava。)
点击 “保存” 校验无误后即可在应用中使用该模型。
Embedding 模型接入方式与 LLM 类似,只需将模型类型改为 Text Embedding 即可。
九、创建工作流
回到主页,点击创建空白应用,这里的聊天助手和文本生成应用,是功能最为单一的 LLM 应用,都不支持工具和知识库的接入。

Agent 和 工作流的区别:
- Agent:智能体,基于大语言模型的推理能力,可以自主选择工具来完成任务,相对简单。
- 工作流:以工作流的形式编排 LLM 应用,提供更多的定制化能力,适合有经验的用户。
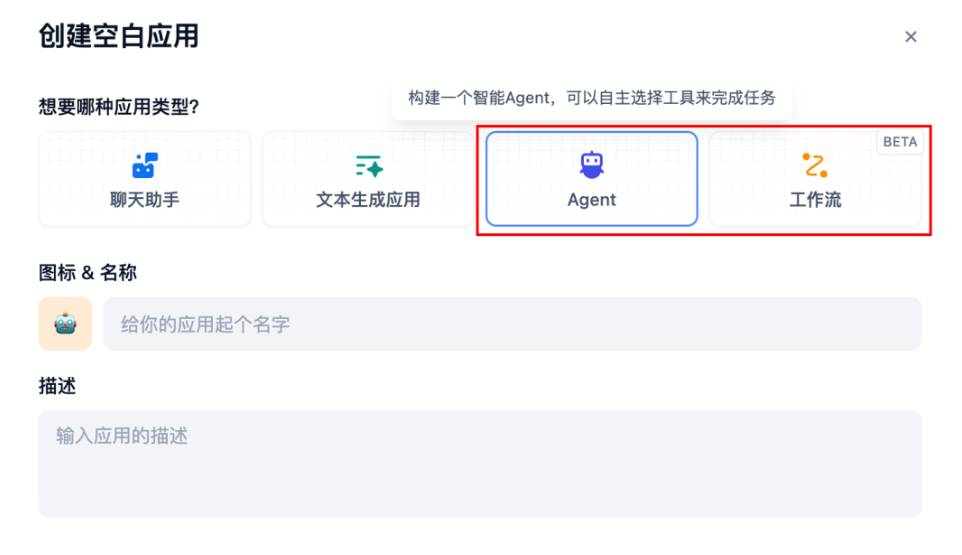
通常,我们需要 Agent 和 工作流配合使用,Agent 负责对话理解,Workflow 处理具体的定制功能。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 7485
7485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









