



 本文介绍了如何在Spark中修改默认的日志级别,包括全局配置(修改log4j.properties),以及在JavaSparkContext和Maven项目中设置特定日志打印级别。重点在于如何使日志输出更专注于错误级别。
本文介绍了如何在Spark中修改默认的日志级别,包括全局配置(修改log4j.properties),以及在JavaSparkContext和Maven项目中设置特定日志打印级别。重点在于如何使日志输出更专注于错误级别。
一、修改Spark-core包默认的日志级别
spark中提供了log4j的方式记录日志。可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 log4j.properties 来启用log4j配置。但这个配置为全局配置,不能单独配置某个job的运行日志。Spark-core包设置默认的日志级别为info。将文件中的log4j.rootCategory=INFO, console修改为log4j.rootCategory=ERROR, console即可,如下图所示:
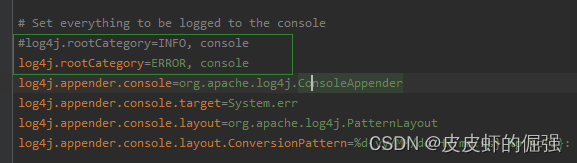
此时,在控制台调试spark程序就没有了INFO信息。

二、在Spark程序中设置日志打印级别:
JavaSparkContext sc = new JavaSparkContext(conf);
//设置日志输出级别
sc.setLogLevel("ERROR");
JavaRDD<String> lines = sc.textFile("input.txt");
三、 在maven项目中设置Spark程序的日志打印级别:
- 引入logger4j和slf4j的依赖
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
- 在代码中加入
Logger.getLogger("org").setLevel(Level.ERROR);





















 到【灌水乐园】发言
到【灌水乐园】发言







