



一 通义千问系列
1 Qwen-VL
这个其实就是使用了一个单层交叉注意力的Q-former,但是其还在交叉注意力中显式加入了绝对位置编码。

输入的格式预处理:<img>图像特征</img>,<box>xyxy格式坐标框</box>

训练过程包括三个,两个预训练阶段和一个指令微调阶段

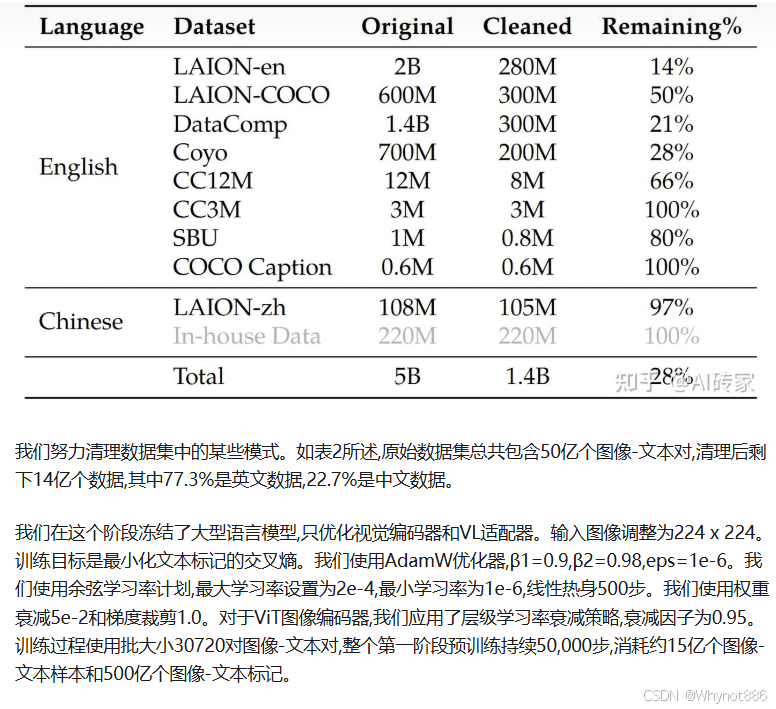

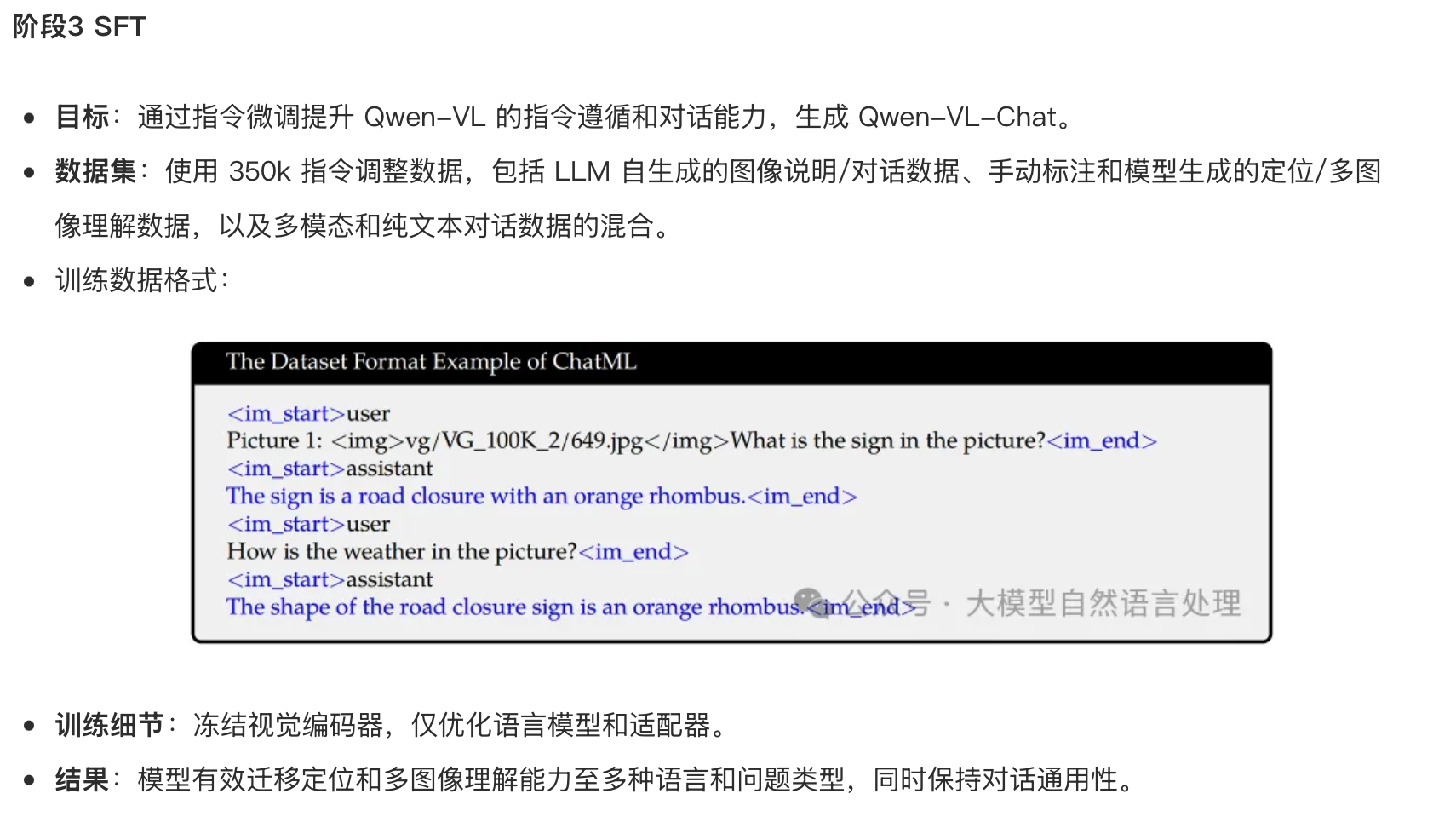
参考:https://www.51cto.com/aigc/4716.html

Qwen2-VL




3 Qwen2.5-VL
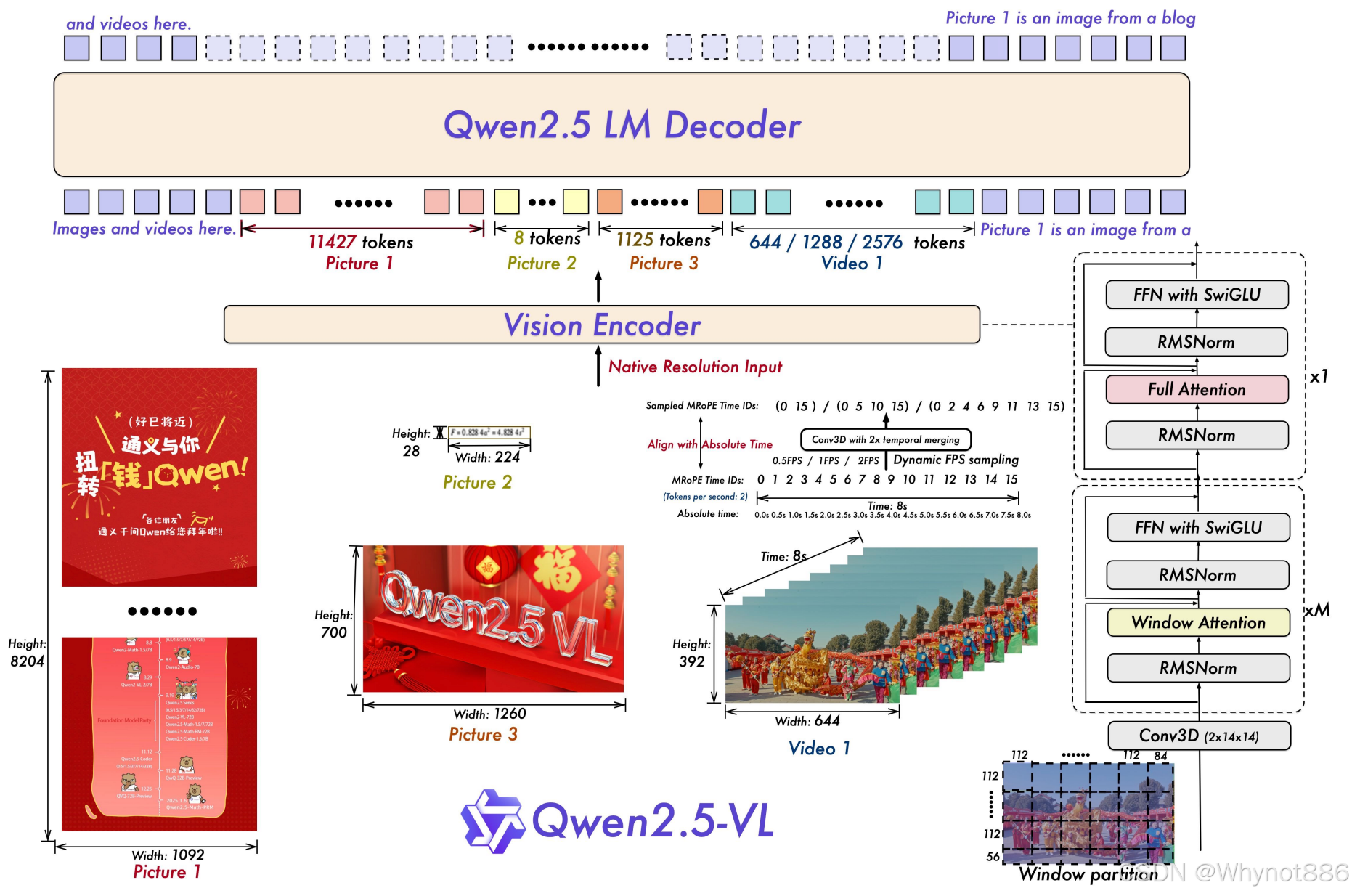

二 ChatGLM系列 (General Language Model)
ChatGLM






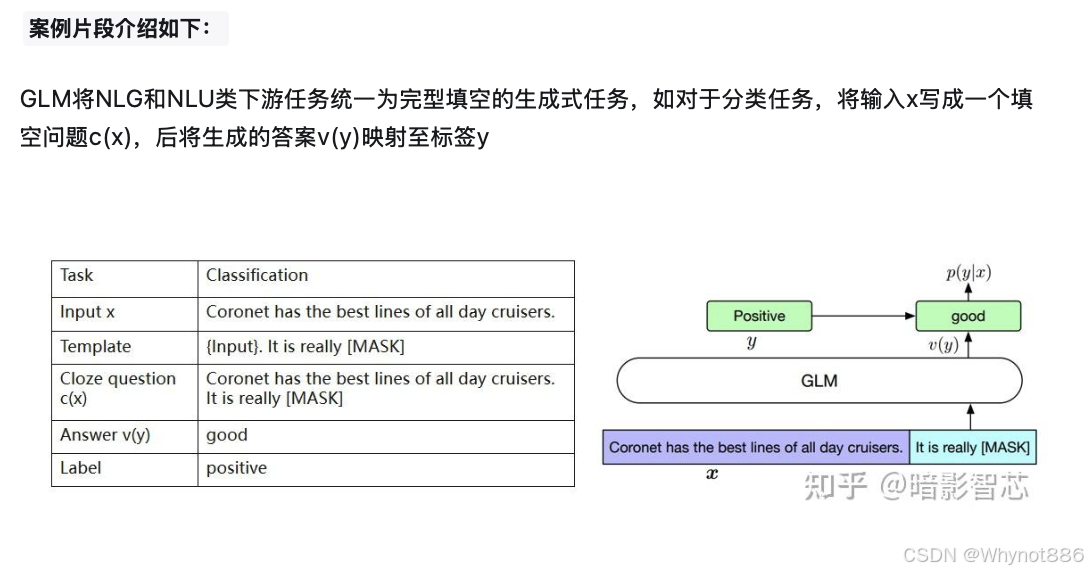

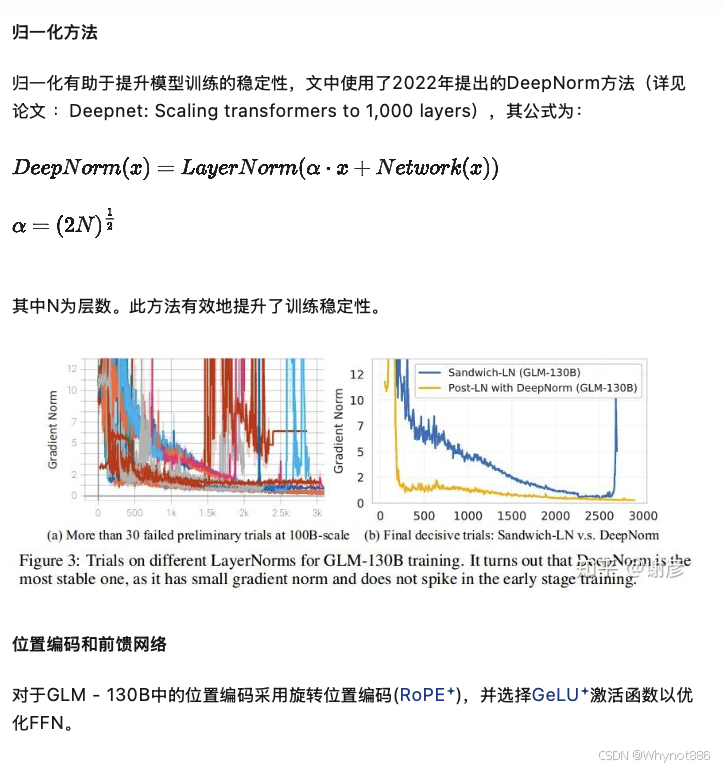

ChatGLM2
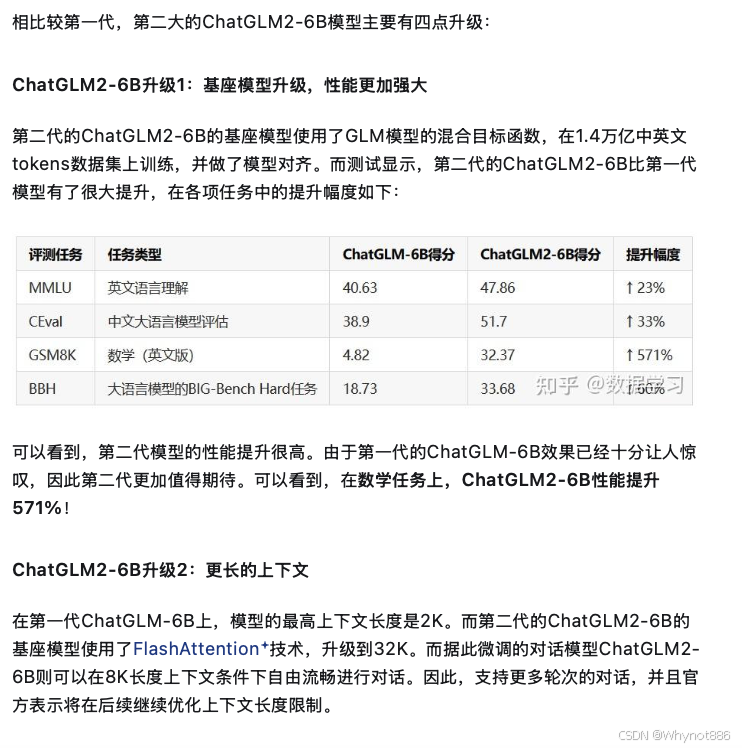


ChatGLM3


VisualGLM
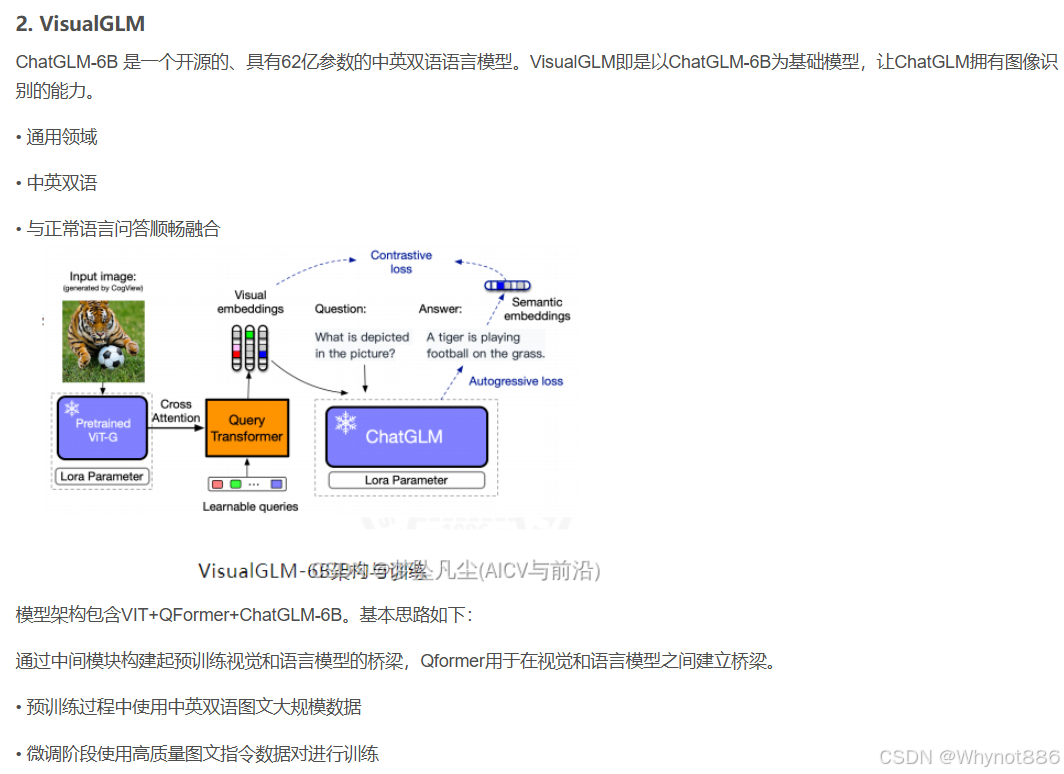

三 Hunyuan 混元大模型系列
优快云 Hunyuan大模型


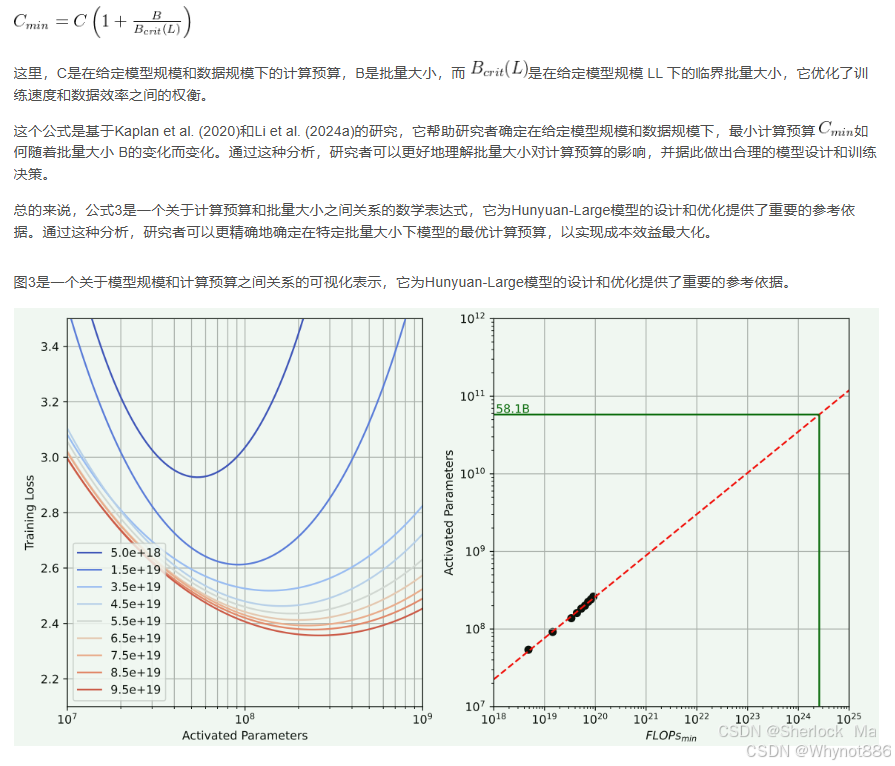
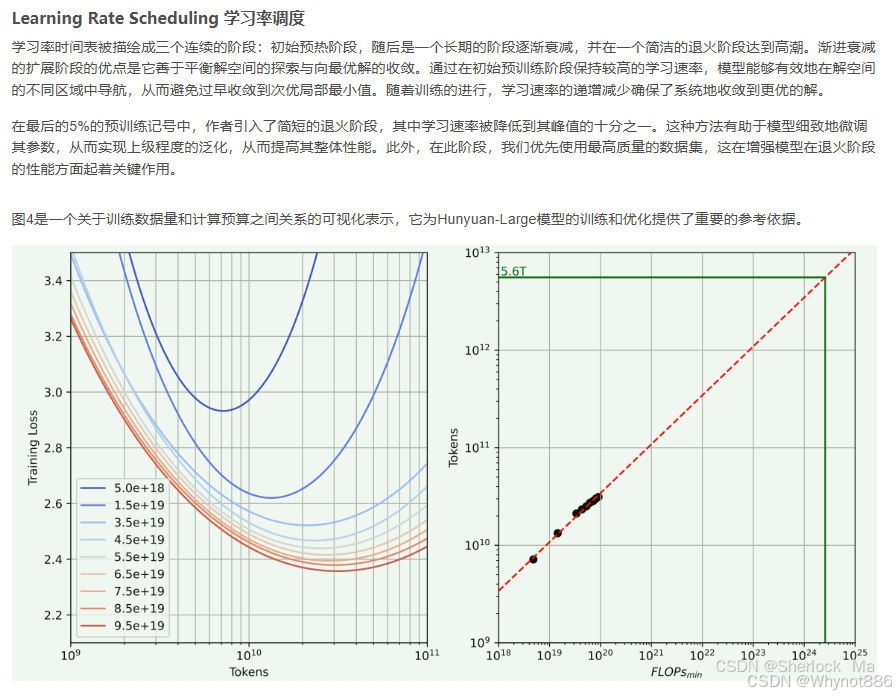



多模态
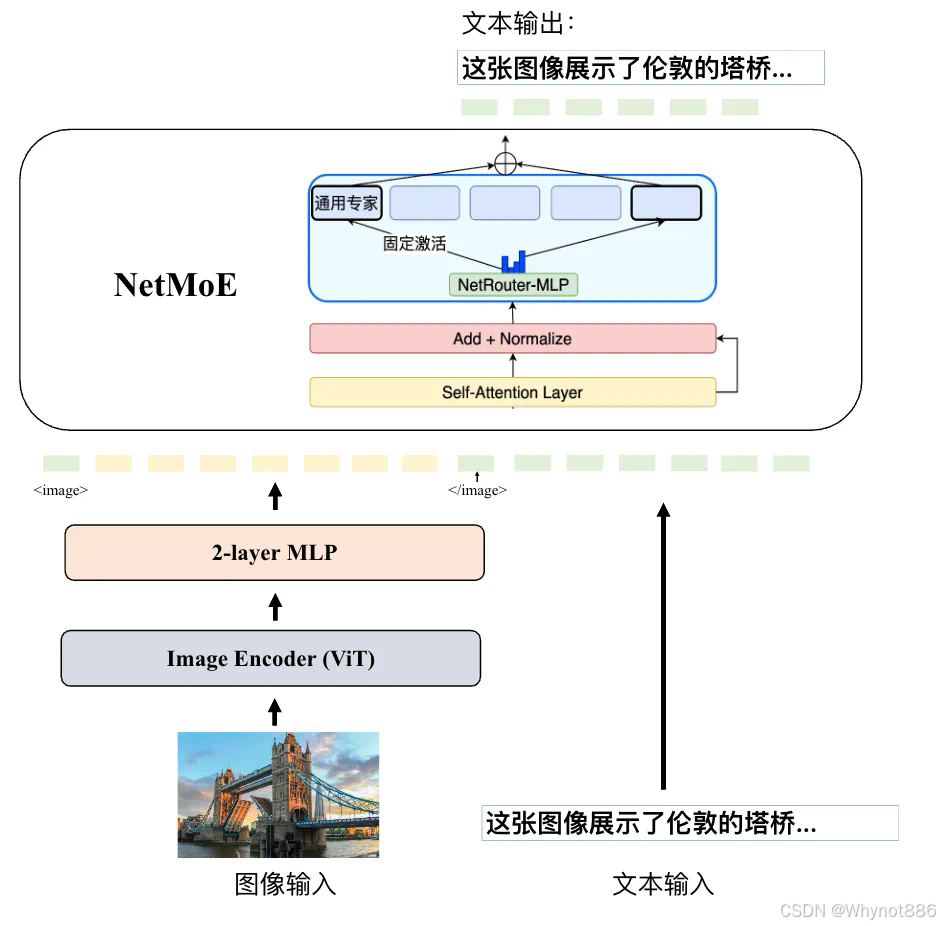
四 Llava系列
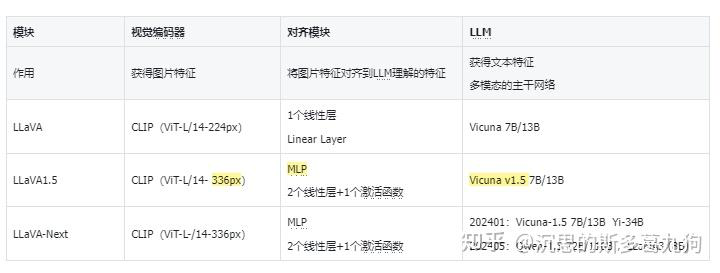
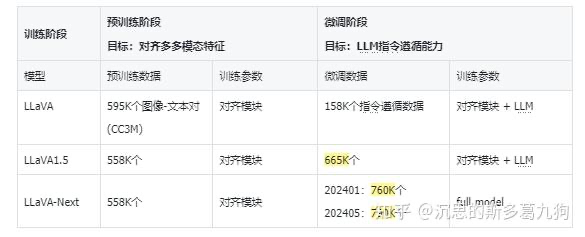
Llava1 (Visual Instruction Tuning)

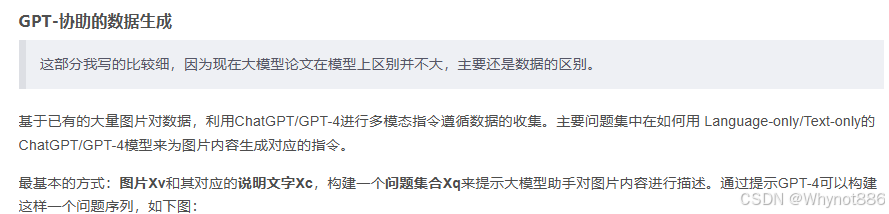





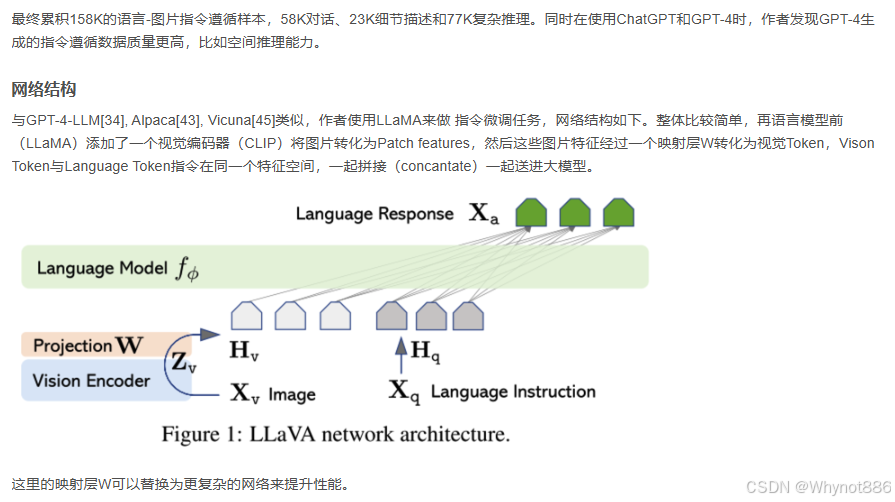


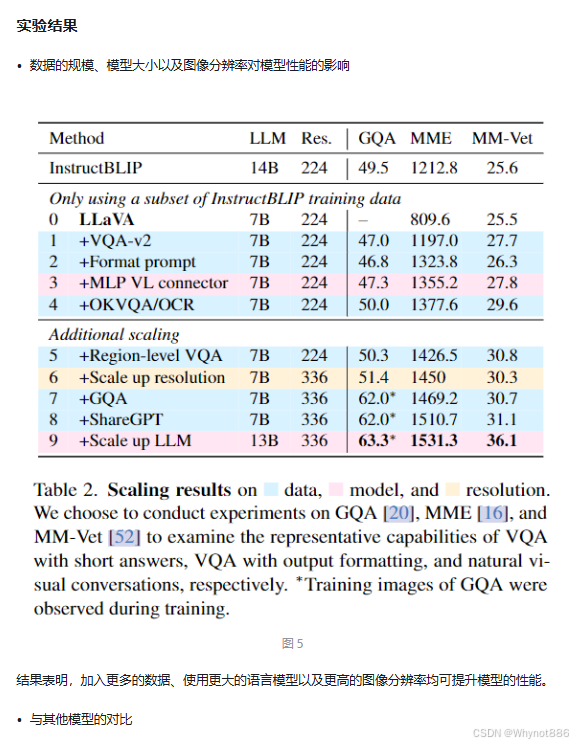
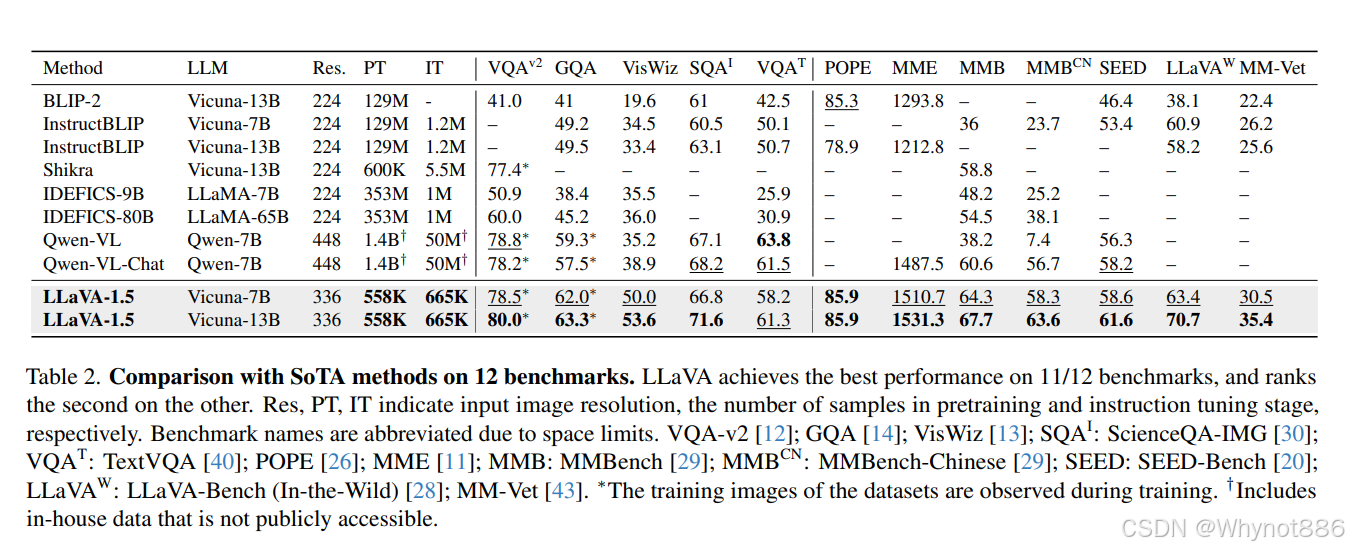
Llava1.5

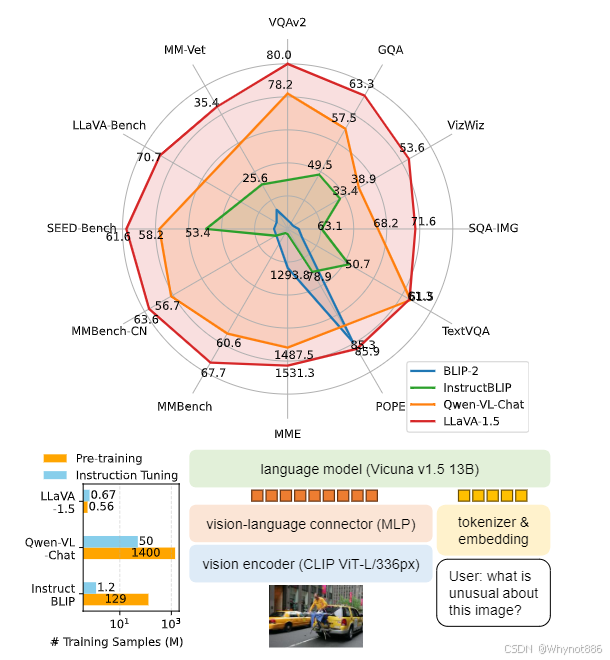





















 2378
2378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









