




 本文介绍了卷积神经网络的基础知识,包括卷积、池化、全连接层及其在模型训练过程中的应用。卷积通过权值共享和局部连接识别图像特征;padding用于保持输出尺寸;池化层用于压缩数据并保留特征;全连接层负责最终的输出计算。模型训练涉及超参数设置、损失函数和梯度下降优化。
本文介绍了卷积神经网络的基础知识,包括卷积、池化、全连接层及其在模型训练过程中的应用。卷积通过权值共享和局部连接识别图像特征;padding用于保持输出尺寸;池化层用于压缩数据并保留特征;全连接层负责最终的输出计算。模型训练涉及超参数设置、损失函数和梯度下降优化。
卷积神经网络CNN入门
参考资料:https://zhuanlan.zhihu.com/p/49184702
卷积
主要作用:识别图片中的指定特征。
运算过程:用卷积核在原图上滑动,进行卷积运算,得到特征图feature map。
权值共享:卷积核扫过整张图片的过程中,卷积核参数不变。
局部连接:feature map上每个值仅对应着原图的一小块区域,原图上的这块局部区域称作感受野(receptive field)。
如下图:绿色表示原图像素值,红色数字表示卷积核中的参数,黄色表示卷积核在原图上滑动。右图表示卷积运算之后生成的feature map。
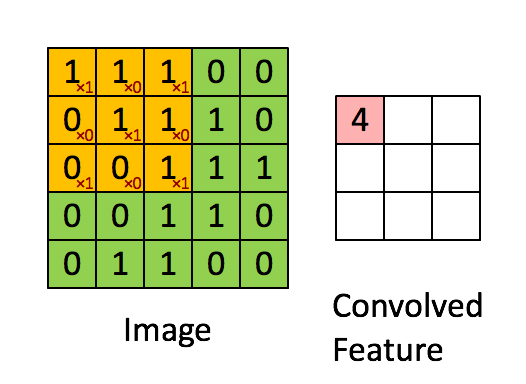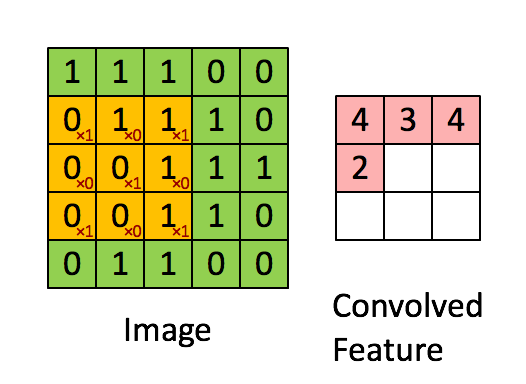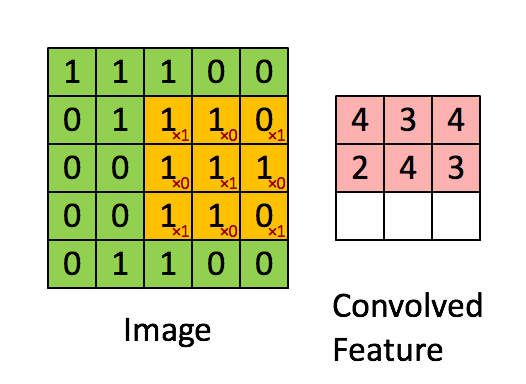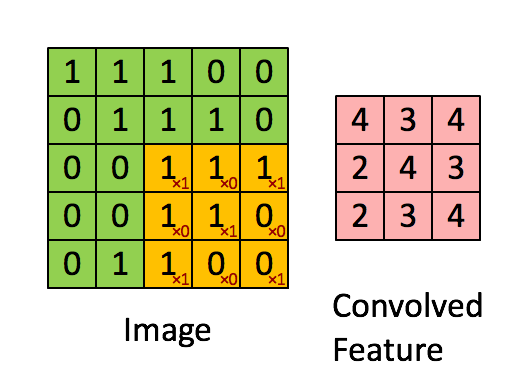
张量(tensor):2D张量即单通道图片。3D张量即多通道图片。
Input Channel:输入张量的通道数。
Output Channel:输出张量的通道数。
每个卷积核的Channel数=Input Channel,每一个卷积层的卷积核数=Output Channel=Feature Map的数量。


RGB三个通道图片的卷积运算过程,共有两组卷积核,每组卷积核都有三个卷积核filter分别与原图的RGB三个通道进行卷积。每组卷积核各自生成一个feature map。
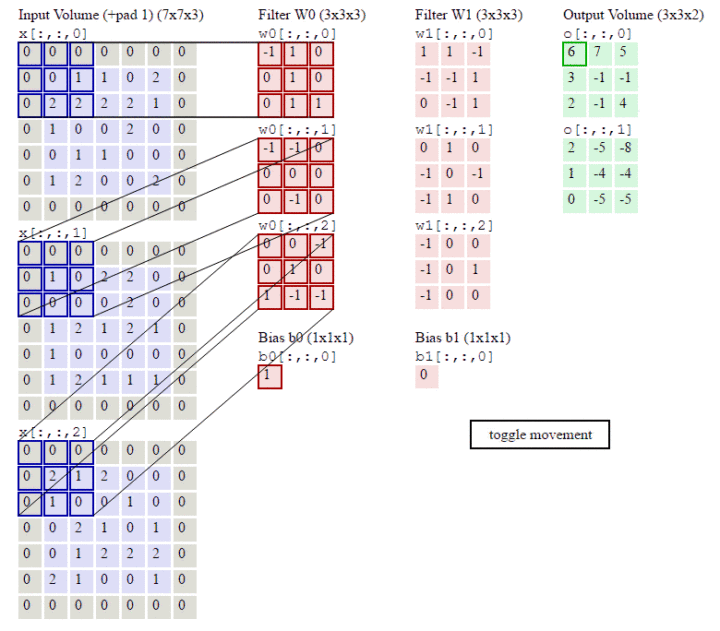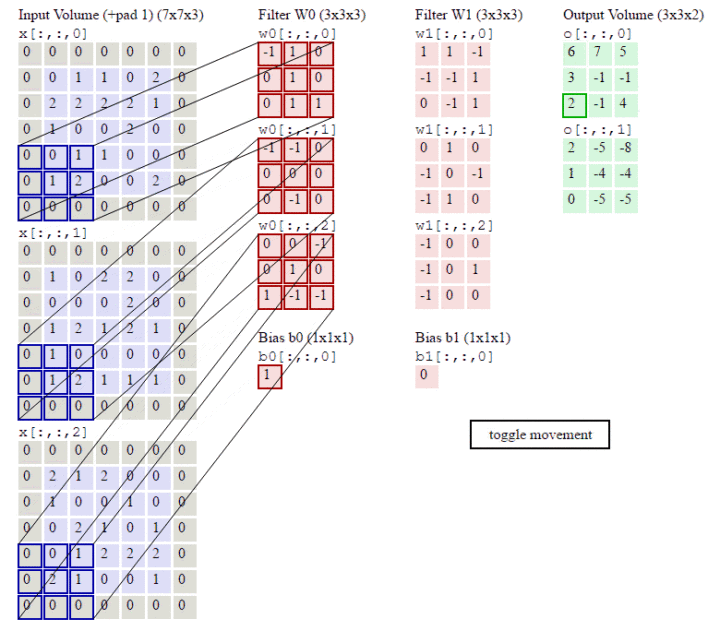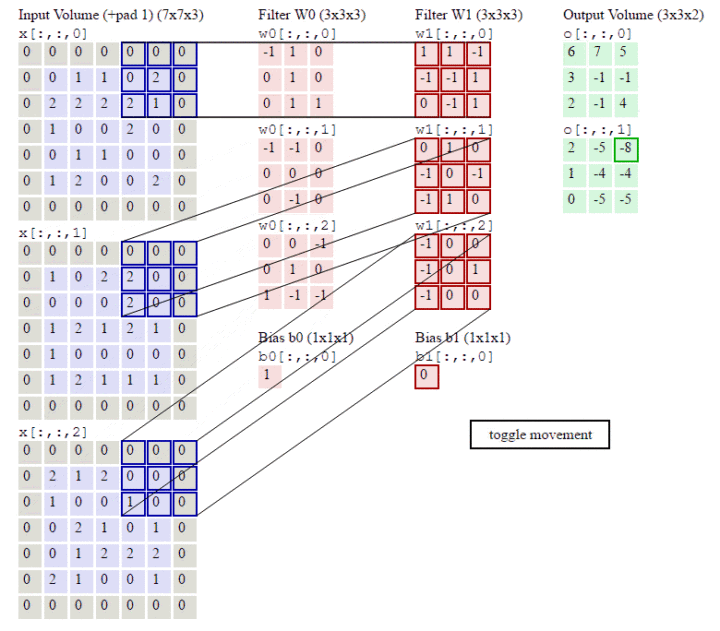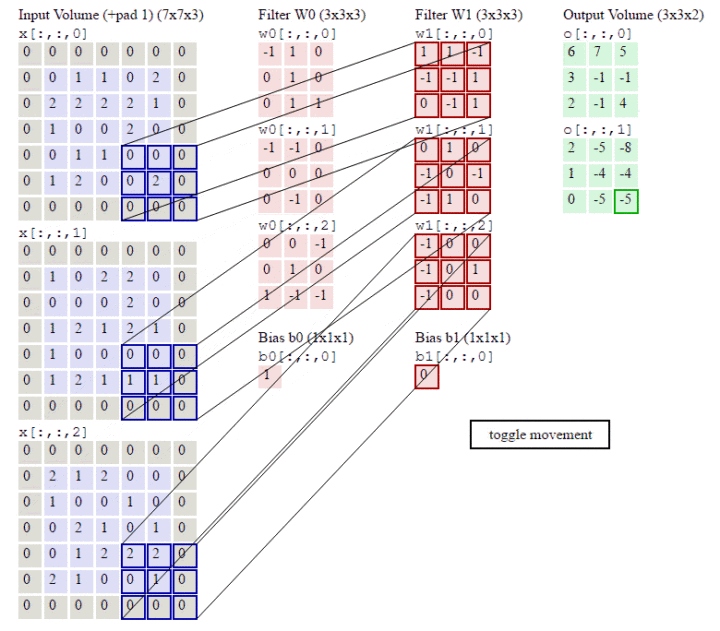
stride:步长
padding
为了让input channel=output channel,在input Tensor外层加若干圈0。加几圈由卷积核的channel以及输入输出通道数决定,加的圈数=kernel size/2(整除)。如下图是3/2=1,加一圈0。

池化/下采样(Pooling/Subsampling)
主要作用:保留特征的同时压缩数据量。用一个像素代替原图上邻近的若干像素,在保留feature map特征的同时压缩其大小。
运算过程:可以用这些像素的最大值作为代表,也可以用平均值作为代表。
全连接
运算过程:通过加权计算得出结果
全连接层:输出的每个神经元都和上一层每一个神经元连接。

模型训练过程
卷积核的数量、大小、移动步长、补0的圈数是事先人为根据经验指定的,全连接层隐藏层的层数、神经元个数也是人为根据经验指定的(这叫做超参数),但其内部的参数是训练出来的。
损失函数:计算卷积神经网络的预测结果与图片真实标签的差距,构造损失函数,训练的目标就是将找到损失函数的最小值。
梯度下降:将损失函数对各种权重、卷积核参数求导,慢慢优化参数,找到损失函数的最小值。
随机梯度下降:在减小损失函数的过程中,采用步步为营的方法,单个样本单个样本输入进行优化,而不是将全部样本计算之后再统一优化。虽然个别样本会出偏差,但随着样本数量增加,仍旧能够逐渐逼近损失函数最小值。

















 2561
2561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









