










YOLO(You Only Look Once)是一个非常流行的实时目标检测模型,YOLO v1是其第一个版本。YOLO 的设计理念是将目标检测任务视为一个回归问题,通过单次卷积神经网络(CNN)来实现对象的定位和分类。下面将详细介绍 YOLO v1 的原理、架构、优缺点以及训练过程。
1. 概述
YOLO v1 提出了目标检测任务的全新思路,即将整个检测过程整合为一个单一的神经网络模型。与传统的目标检测方法(如 R-CNN 系列)不同,YOLO v1 采用了全图像作为输入,并在一个前向传播中同时返回多个边界框和对应的类概率。
2. YOLO v1 的原理
2.1. 目标检测问题的建模
YOLO v1 将目标检测视为一个回归问题。具体来说,该模型将输入图像划分为一个 的网格。每个网格负责预测其中的对象,包括:
边界框坐标:每个网格会预测固定数量(如 2 个)的边界框,每个边界框描述其相对于网格的偏移量。
置信度:每个边界框都有一个置信度得分,表示该框中存在物体的概率以及该框预测质量的乘积。
类别概率分布:每个网格预测的物体类概率分布(如 \(。
结合以上信息,YOLO v1 的输出层会生成一个 (S, S, B * 5 + C) 的张量,其中 是每个网格预测的边界框数量,C 是类别数。
2.2. 预测机制
每个网格单元输出的内容包含以下信息:
每个边界框的 4 个参数 (x, y, w, h)。
每个边界框的置信度分数。
每个网格对每个可能的类别的概率。
最终的预测结果可通过置信度分数和类别概率计算得到。
3. YOLO v1 的网络架构
YOLO v1 的架构包括:
主干网络:通常为一个改进的 GoogLeNet,使用卷积和池化层提取特征。
全连接层:将提取的特征映射到最终的输出层,其中包含边界框坐标、置信度和类别概率。
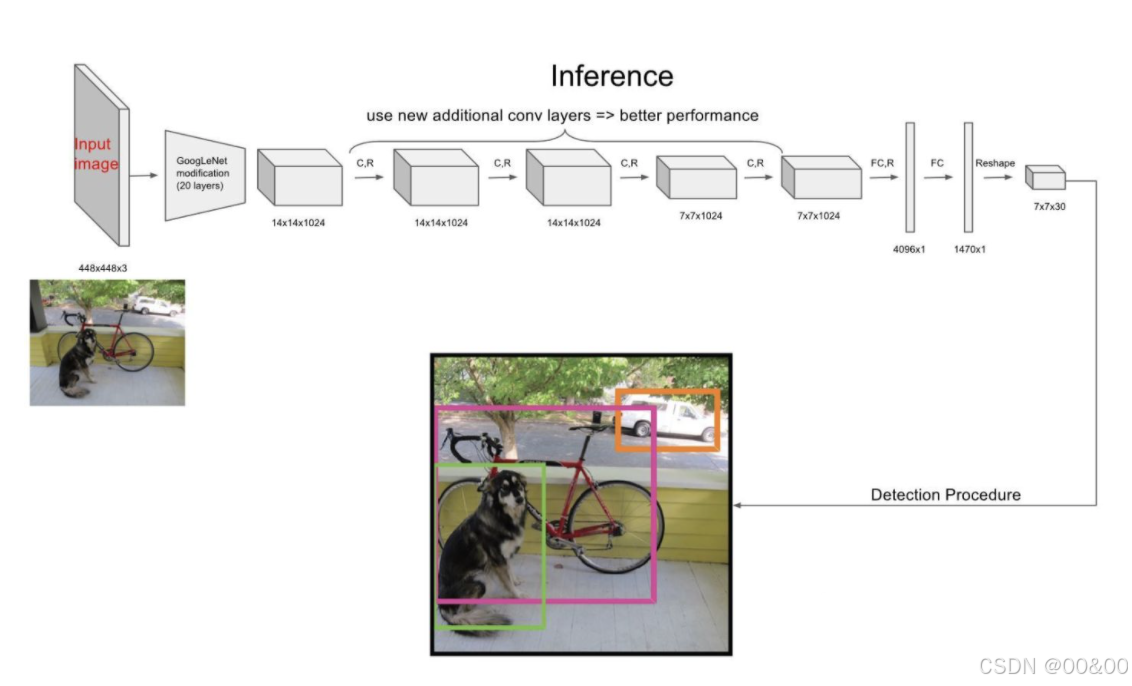
3.1. 网络细节
网络一般包含 24 层卷积层和 2 层全连接层。
使用 Leaky ReLU 作为激活函数。
在输出层部,用 Sigmoid 函数处理边界框置信度和对象类别概率。
4. 损失函数
YOLO v1 使用一个多部分的损失函数来评估模型性能:
位置损失:衡量边界框预测 (x, y, w, h) 与真实框之间的差异。
置信度损失:评估模型预测的边界框是否包含对象。
类别损失:评估模型对类别概率的预测效果。
损失函数的一般形式:
:边界框坐标损失(通常使用均方误差)。
:置信度损失。
:类别概率损失。
5. 优缺点
5.1 优点
速度:YOLO v1 能够以实时速度进行目标检测(通常为 45 FPS),使其适用于实时应用。
端到端训练:通过单一的神经网络架构,使得训练和推理过程简化。
全局上下文信息:由于整个图像被考虑,YOLO 能够有效捕捉物体之间的上下文信息。
5.2 缺点
小物体检测性能较差:由于网格划分的方式,小物体可能被分配到的网格导致其检测精度降低。
一般化能力:对于复杂场景,尤其是密集重叠的物体,检测性能下降。
6. 训练过程
数据准备:使用带有标注的图像集(如 PASCAL VOC、COCO),进行归一化处理。
网络设计:构建 YOLO 网络并确定输入图像的大小(例如 448x448)。
损失函数设置:定义模型的损失函数。
优化:使用 SGD 或 Adam 优化器进行训练,调整学习率。
评估与调优:使用 mAP(mean Average Precision)等评估指标,在验证集上调节网络参数。
7.YOLO v1 示例
YOLO v1 将目标检测视为一个回归问题,以下是一个简单的示例来展示 YOLO v1 的工作原理:
假设我们有一张包含多个物体(如汽车、行人等)的图像。YOLO v1 将这张图像划分为的网格(例如 7x7),每个网格负责检测其中的物体。
每个网格预测 2 个边界框和对应的置信度得分。
同时,网格还预测每个物体的类别概率。
假设某个网格预测到以下内容:
边界框 1:,置信度
边界框 2:,置信度
类别概率:
最终,YOLO v1 会输出这些边界框及其对应的类别概率,用户可以根据置信度进行筛选,决定哪些边界框是有效的检测结果。
YOLO v1 的实现代码
以下是一个简单的 YOLO v1 的实现示例,使用 PyTorch 框架。这个例子仅为展示 YOLO v1 的基本结构,实际应用中需要进行更复杂的处理和优化。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义 YOLO v1 模型
class YOLOv1(nn.Module):
def __init__(self, num_classes, num_boxes):
super(YOLOv1, self).__init__()
self.num_classes = num_classes
self.num_boxes = num_boxes
self.S = 7 # 网格大小
self.B = num_boxes # 每个网格预测的边界框数量
# 定义卷积层
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(64, 192, kernel_size=3, stride=1, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = nn.Conv2d(192, 128, kernel_size=1, stride=1, padding=0)
self.conv4 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5 = nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0)
self.conv6 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv7 = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0)
self.conv8 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
self.conv9 = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0)
self.conv10 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
self.conv11 = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0)
self.conv12 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv13 = nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0)
self.conv14 = nn.Conv2d(512, 1024, kernel_size=3, stride=1, padding=1)
# 全连接层
self.fc1 = nn.Linear(1024 * 4 * 4, 4096)
self.fc2 = nn.Linear(4096, self.S * self.S * (self.B * 5 + self.num_classes))
def forward(self, x):
x = F.leaky_relu(self.conv1(x))
x = self.pool1(x)
x = F.leaky_relu(self.conv2(x))
x = self.pool2(x)
x = F.leaky_relu(self.conv3(x))
x = F.leaky_relu(self.conv4(x))
x = self.pool3(x)
x = F.leaky_relu(self.conv5(x))
x = F.leaky_relu(self.conv6(x))
x = self.pool4(x)
x = F.leaky_relu(self.conv7(x))
x = F.leaky_relu(self.conv8(x))
x = F.leaky_relu(self.conv9(x))
x = F.leaky_relu(self.conv10(x))
x = F.leaky_relu(self.conv11(x))
x = F.leaky_relu(self.conv12(x))
x = self.pool5(x)
x = F.leaky_relu(self.conv13(x))
x = F.leaky_relu(self.conv14(x))
x = x.view(x.size(0), -1) # 展平
x = F.leaky_relu(self.fc1(x))
x = self.fc2(x) # 输出层
return x
# 数据准备
def get_data_loader(batch_size):
transform = transforms.Compose([
transforms.Resize((448, 448)),
transforms.ToTensor(),
])
dataset = datasets.FakeData(transform=transform) # 使用 FakeData 作为示例数据集
return DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 训练模型
def train(model, data_loader, num_epochs, learning_rate):
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(num_epochs):
for images, _ in data_loader:
optimizer.zero_grad()
outputs = model(images)
# 这里应计算损失,使用适当的损失函数
# loss = compute_loss(outputs, targets) # 需要定义 compute_loss 函数
# loss.backward()
# optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}] completed.")
# 示例用法
if __name__ == "__main__":
num_classes = 20 # 假设有 20 个类别
num_boxes = 2 # 每个网格预测 2 个边界框
model = YOLOv1(num_classes, num_boxes)
# 获取数据加载器
data_loader = get_data_loader(batch_size=16)
# 训练模型
train(model, data_loader, num_epochs=10, learning_rate=0.001)
# 测试模型
model.eval()
with torch.no_grad():
# 这里可以添加测试代码,使用真实数据进行推理
pass8. 总结
YOLO v1 为目标检测在速度和实时性方面做出了重大贡献,尽管面临一些性能上的挑战,但其创新性方法为后续版本(如 YOLO v2, YOLO v3 和 YOLOv4)奠定了基础。后续版本在精度、速度和灵活性上进行了更大优化。

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









