




 本文探讨了图像分类问题,详细介绍了卷积神经网络(CNN)的挑战与残差学习,包括ResNet中的残差模块。接着,讨论了轻量化CNN的策略,如可分离卷积和分组卷积。最后,引入了VisionTransformers,特别是SwinTransformer,这是一种最新的Transformer架构在计算机视觉领域的应用。
本文探讨了图像分类问题,详细介绍了卷积神经网络(CNN)的挑战与残差学习,包括ResNet中的残差模块。接着,讨论了轻量化CNN的策略,如可分离卷积和分组卷积。最后,引入了VisionTransformers,特别是SwinTransformer,这是一种最新的Transformer架构在计算机视觉领域的应用。
一、图像分类
- 问题的数学表示

- 结果的数学表示
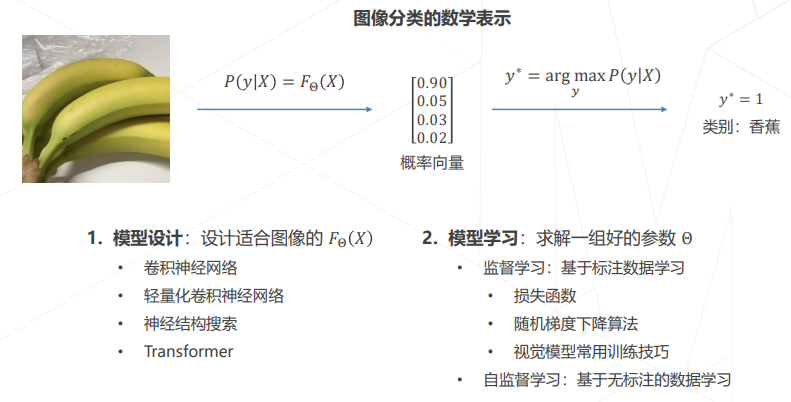
二、卷积神经网络
- 模型层数增加到一定程度后,卷积退化为恒等映射,导致深层网络与浅层网络效果相同
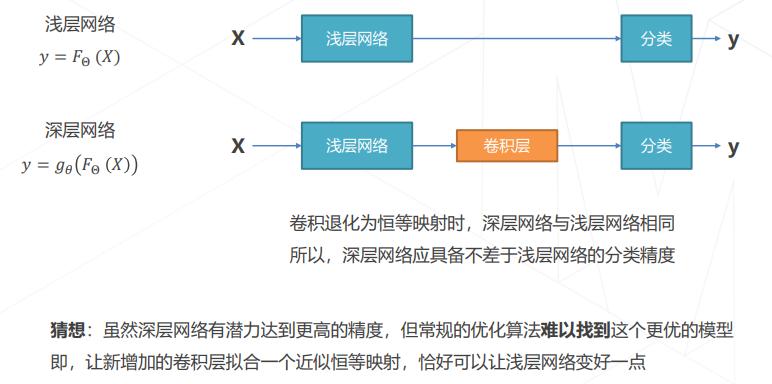
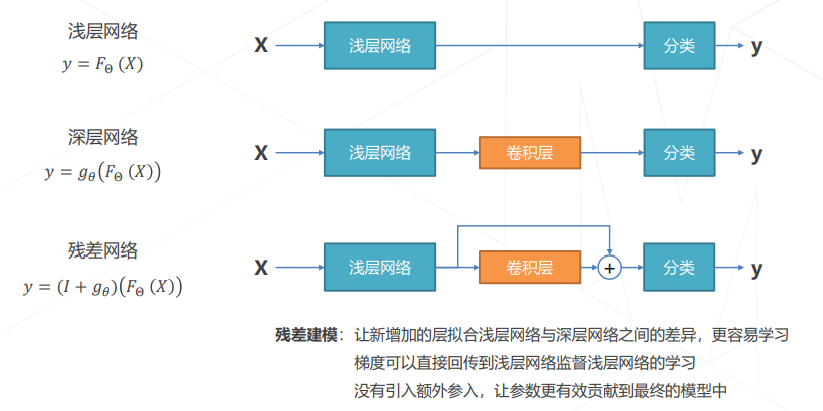
- 残差学习的基本思路
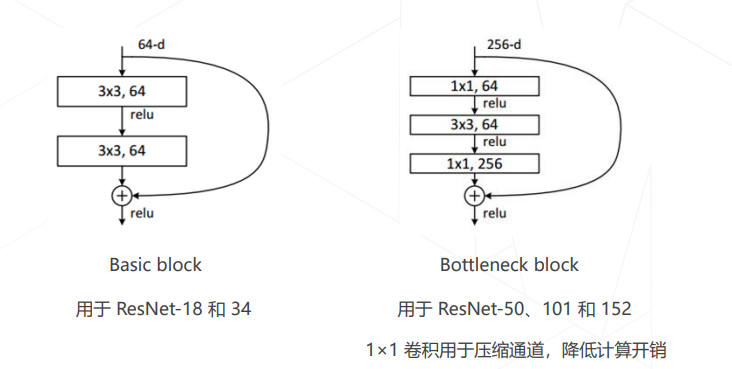
3. ResNet 中的两种残差模块
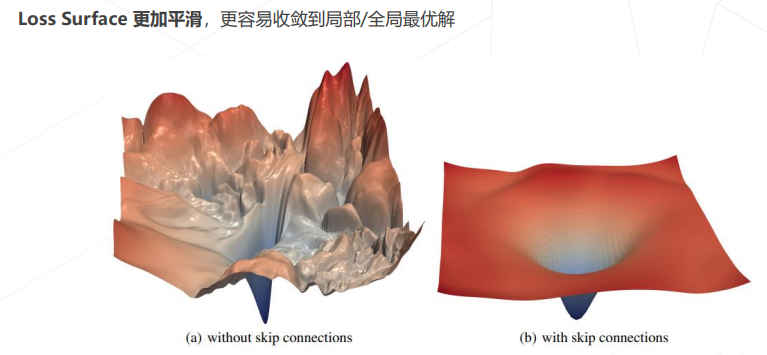
- 残差使收敛到局部/全局最优解更容易
三、轻量化卷积神经网络
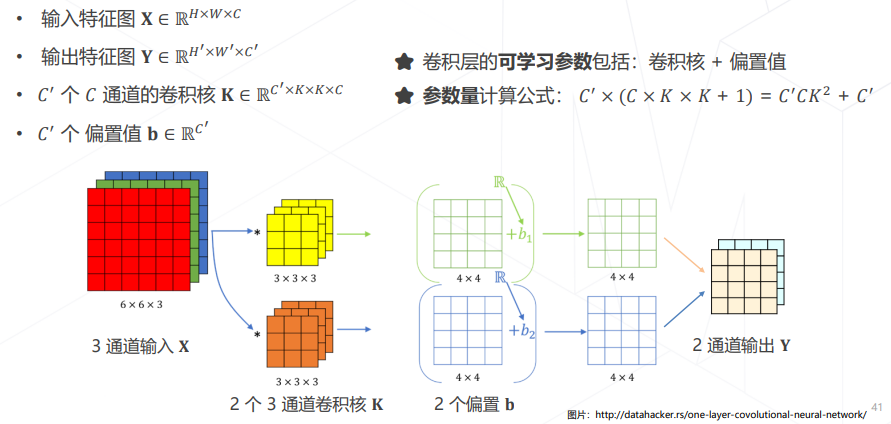
- 卷积的参数量
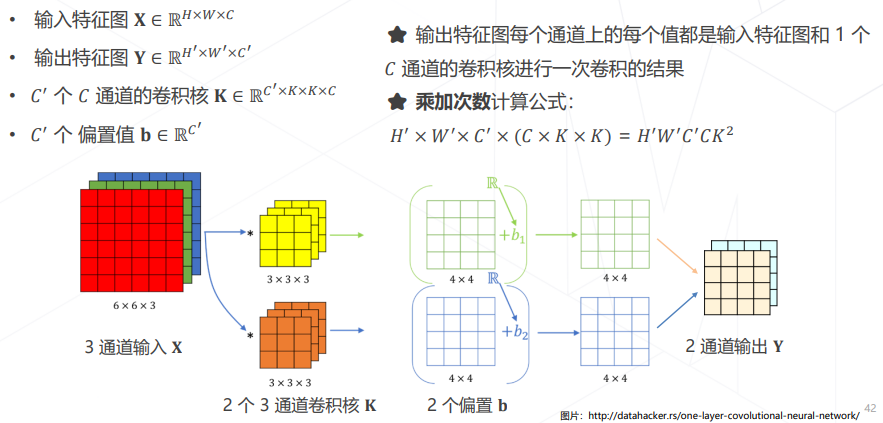
- 卷积的计算量(乘加次数)
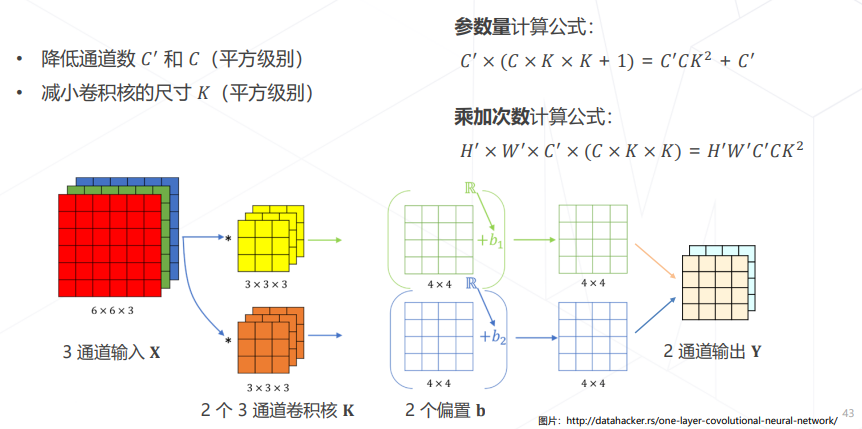
- 降低模型参数量和计算量的方法
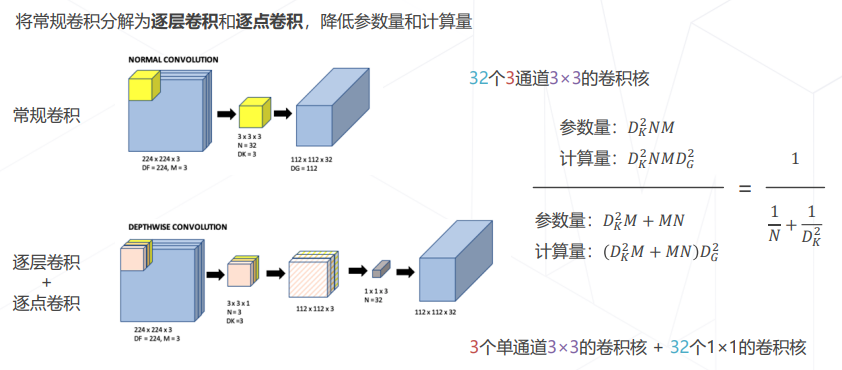
- 可分离卷积
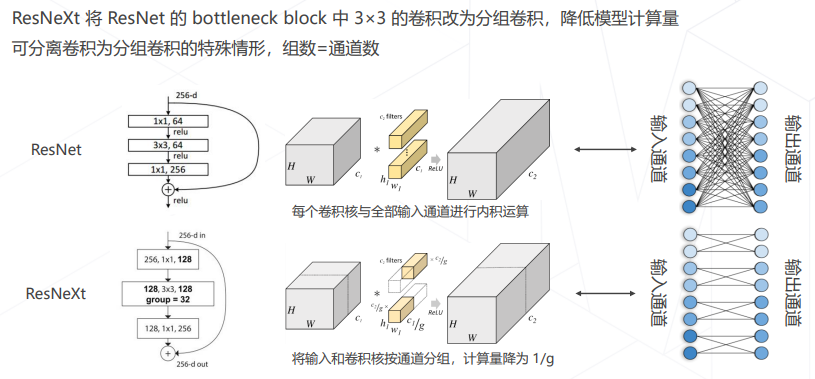
- ResNeXt 中的分组卷积
四、Vision Transformers
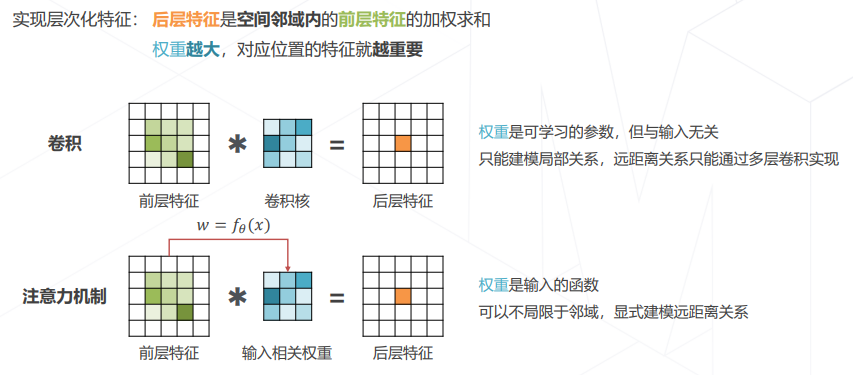
- 注意力机制 Attention Mechanism
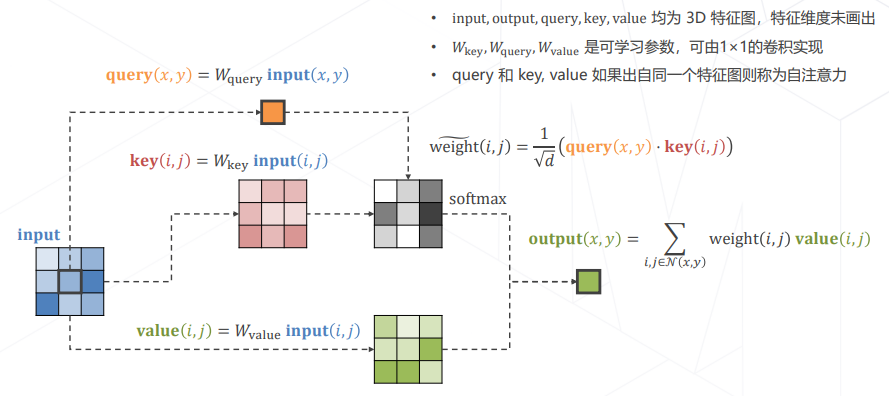
- 实现 Attention
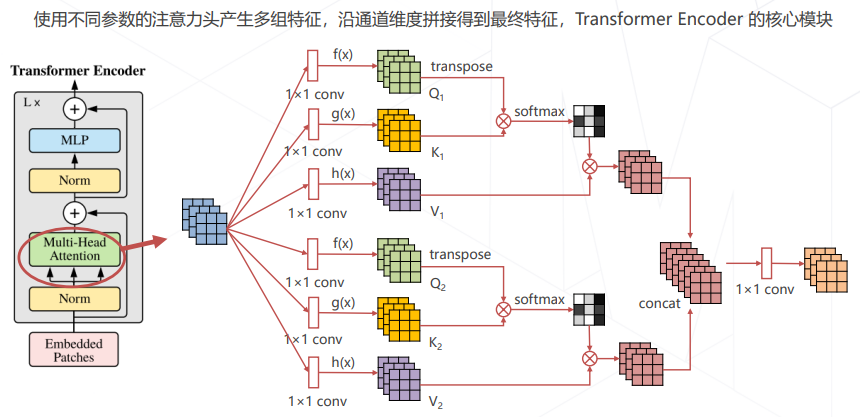
- 多头注意力 Multi-head (Self-)Attention
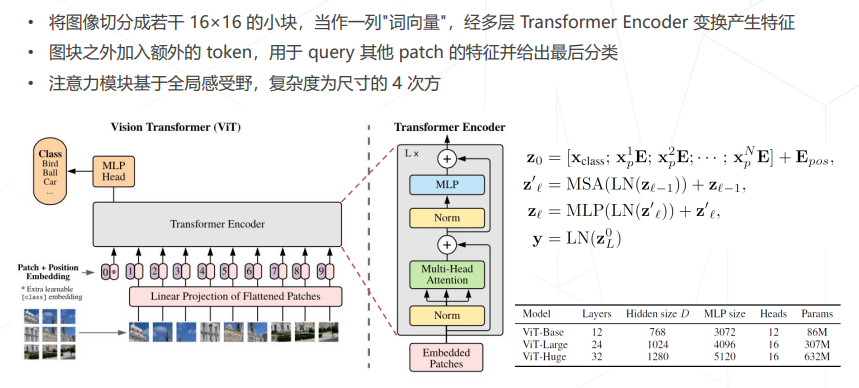
- Vision Transformer (2020)
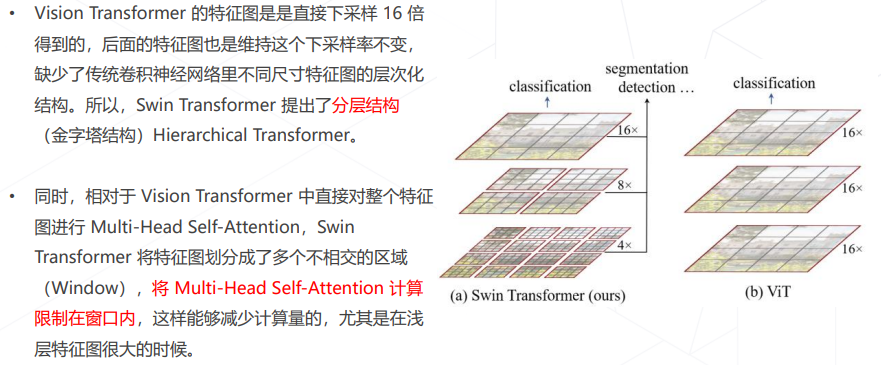
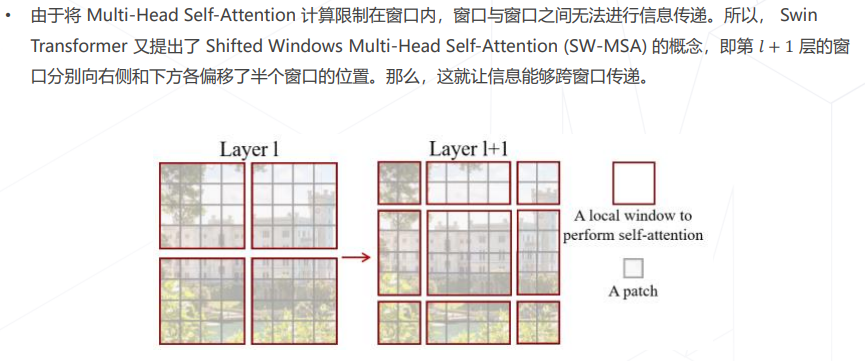
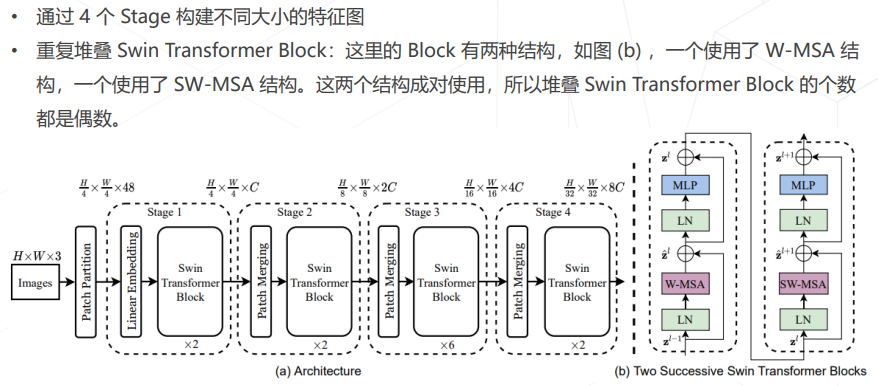
- Swin Transformer (ICCV 2021 best paper)

















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









