






Fluent Python
1. 数据结构
1.1. 内置序列类型概览
Python 标准库用 C 实现了丰富的序列类型,列举如下。
- 容器序列:
list、tuple和collections.deque这些序列能存放不同类型的数据 - 扁平序列:
str、bytes、bytearray、memoryview和array.array,这类序列只能容纳一种类型。
容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用
序列类型还能按照能否被修改来分类:
- 可变序列:
list、bytearray、array.array、collections.deque 、 memoryview - 不可变序列:
tuple、str 、 bytes
1.2. 列表推导和生成器表达式
列表推导是构建列表(list)的快捷方式,而生成器表达式则可以用来创建其他任何类型 的序列。
列表推导:listcomps,生成器表达式:genexps
Python 会忽略代码里 []、{} 和 () 中的换行,因此如果你的代码里有多行的列 表、列表推导、生成器表达式、字典这一类的,可以省略不太好看的续行符 \。
"""
列表推导
"""
symbols = "qwer"
codes = []
for s in symbols:
codes.append(ord(s))
print(codes)
codes1 = [ord(x) for x in symbols]
print(codes1)
# case 2 : use filter and map
symbols = '$¢£¥€¤'
beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
print(beyond_ascii)
beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
print(beyond_ascii)
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
tshirts1 = [(color, size) for color in colors for size in sizes]
tshirts2 = [(color, size) for size in sizes for color in colors ]
print(tshirts1)
print(tshirts2)
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
"""
生成器表达式
"""
import array
symbols = '$¢£¥€¤'
tp1 = tuple(ord(symbol) for symbol in symbols)
print(tp1)
arr = array.array('I', (ord(symbol) for symbol in symbols))
print(arr)
# 计算笛卡尔积
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
for tshirt in ("%s %s" % (c, s) for c in colors for s in sizes):
"""
TODO: %s 和 %r的区别是?
生成器表达式 比 列表推导 的好处:
一个一个的产生 元素,而不是一下产生6个元素
"""
print(tshirt)
1.3. Tuple
1.3.1. 元祖是”不可变的列表“,还用于没有字段名的记录。
元组中的每个元素都存放了记录中一个字段的数据,外加这个 字段的位置。正是这个位置信息给数据赋予了意义。
for 循环可以分别提取元组里的元素,也叫作拆包(unpacking):
拆包举例:
- 把元组 (‘Tokyo’, 2003, 32450, 0.66, 8014) 里的元素分别赋值给变量 city、year、pop、chg 和 area
- 一个 % 运算符就把 passport 元组里的元素对应到了 print 函数的格式字符串空 档中
import os
city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014)
print(city)
lax_coordinates = (33.945, -158.76)
latitude, longitude = lax_coordinates
print(latitude)
print(longitude)
print(divmod(20, 8))
t = (20, 8)
# *运算符把一个可迭代对象拆开作为函数的参数
print(divmod(*t))
# _ 为占位符
_, filename = os.path.split('/home/luciano/.ssh/idrsa.pub')
print(filename)
# 函数用 *args 来获取不确定数量的参数算是一种经典写法了。
# * 可以用来表示多个不确定的变量
a, b, *c = range(5)
print(a, b, c)
a, *b, c = range(5)
print(a, b, c)
*a, b, c = range(5)
print(a, b, c)
元组拆包可以应用到任何可迭代对象上,唯一的硬性要求是,被可迭代对象中的元素数量必须要跟接受这些元素的元组的空档数一致。除非我们用 * 来 表示忽略多余的元素。
在进行拆包的时候,我们不总是对元组里所有的数据都感兴趣,_ 占位符能帮助处理这种 情况,上面这段代码也展示了它的用法。
1.3.2. 具名Tuple
collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有 名字的类。用 namedtuple 构建的类的实例所消耗的内存跟元组是一样的,因为字段名都 被存在对应的类里面。
(1)创建一个具名元组需要两个参数:
-
一个是类名
-
另一个是类的各个字段的名字。
后者可以是由数个字符串组成的可迭代对象,或者 是由空格分隔开的字段名组成的字符串。
(2)存放在对应字段里的数据要以一串参数的形式传入到构造函数中
(3)通过字段名或者位置来获取一个字段的信息
# 具名元祖 namedtuple
from collections import namedtuple
City = namedtuple('City', 'name country population coordinates')
tokyo = City('Tokyo', 'JP', 36.966, (11.22, 44.55))
print(tokyo)
print(tokyo.population)
print(tokyo[1])
print(City._fields)
具名元祖还有一些特殊属性:_fields 类属性、类方法 _make(iterable) 和实例方法 _asdict()。
_fields属性是一个包含这个类所有字段名称的元组- 用
_make()通过接受一个可迭代对象来生成这个类的一个实例,它的作用跟City(*delhi_data)是一样的 _asdict()把具名元组以collections.OrderedDict的形式返回
from collections import namedtuple
City = namedtuple('City', 'name country population coordinates')
tokyo = City('Tokyo', 'JP', 36.966, (11.22, 44.55))
print(City._fields)
LatLong = namedtuple('LatLong', 'Lat Long')
delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
delhi = City._make(delhi_data)
print(delhi)
# output
('name', 'country', 'population', 'coordinates')
City(name='Delhi NCR', country='IN', population=21.935, coordinates=LatLong(Lat=28.613889, Long=77.208889))
1.3.3. tuple vs list
- 除了跟增减元素相关的方法之外,元组支持列表的其他所有方法
- 元组没有 reversed 方法,但是这个方法只是个优化而已,reversed(my_tuple) 这 个用法在没有 reversed 的情况下也是合法的
1.4. 切片 Split
1.4.1. 对对象进行切片
列表(list)、元组(tuple)和字符串(str)这类序列类型都支持切片 操作。
var[start:end]表示的是:取var中[ start, end )的数,index从0开始。var[start : end : step]:表示的是:对var中在[start, end )中以step为间隔取值。
# split
var1 = 'bicycle'
print(var1[::3])
print(var1[::-1])
print(var1[::-2])
# output
bye
elcycib
eccb
a:b:c 这种用法只能作为索引或者下标用在 [] 中来返回一个切片对象:slice(a, b, c)。
对seq[start:stop:step] 进行求值的时候,Python 会调用seq.__getitem__(slice(start, stop, step))
1.4.2. 多维切片和省略
1.4.3. 给切片复制
-
如果把切片放在赋值语句的左边,或把它作为 del 操作的对象,我们就可以对序列进行嫁接、切除或就地修改操作。
-
如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。即便只有单独 一个值,也要把它转换成可迭代的序列。
# ops split
l = list(range(10))
print(l) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(l[2:5]) # [2, 3, 4]
l[2:5] = [20, 30]
print(l) # [0, 1, 20, 30, 5, 6, 7, 8, 9]
print(l[5:7]) # [6, 7]
del l[5:7]
print(l) # [0, 1, 20, 30, 5, 8, 9]
print(l[3::2]) # [30, 8]
l[3::2] = [11, 12]
print(l) # [0, 1, 20, 11, 5, 12, 9]
# l[2:5] = 100 # error
l[2:5] = [100]
print(l) # [0, 1, 100, 12, 9]
1.5. 对序列进行+ 和 *
- 通常 + 号两侧的序列由相同类型的数据所 构成,在拼接的过程中,两个被操作的序列都不会被修改,Python 会新建一个包含同样类 型数据的序列来作为拼接的结果
- 如果想要把一个序列复制几份然后再拼接起来,更快捷的做法是把这个序列乘以一个整数。产生一个新的序列
# ops + *
l = [1,2,3]
print(l * 3) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
a,b = [1,2,3],[4,5,6]
print(a+b) # [1, 2, 3, 4, 5, 6]
print('abc'*5) # abcabcabcabcabc
注意:如果在 a * n 这个语句中,序列 a 里的元素是对其他可变对象的引用的话,可能导致bug。
board = [['_'] * 3 for i in range(3)]
print(board) # [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
board[1][2] = 'X'
print(board) # [['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
# * has bug
board = [['_'] * 3] * 3
print(board) # [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
board[1][2] = 'X'
print(board) # [['_', '_', 'X'], ['_', '_', 'X'], ['_', '_', 'X']]
理解:
[['_'] * 3] * 3其实包含 3 个指向同一个列表的引用
board = [['_'] * 3 for i in range(3)]
# 等效于
board = []
for i in range(3):
board.append(['_'] * 3)
board = [['_'] * 3] * 3
# 等效于
board = []
row = ['_'] * 3
for i in range(3):
board.append(row)
*=和+=同理
1.6. 序列的增量赋值
-
+=背后的特殊方法是__iadd__(用于“就地加法”)。但是如果一个类没有实现这个方法的 话,Python 会退一步调用__add__。变量名会不 会被关联到新的对象,完全取决于这个类型有没有实现__iadd__这个方法。 -
同理
*=对应的特殊方法是:__imul__
- 不要把可变对象放在元组里面
- 增量赋值不是一个原子操作
t = (1, 2, [3, 4])
print(t)
t[2] += [5, 6] # error
print(t) # 打印不出来,但是值变成了 (1, 2, [3, 4, 5, 6])
1.7. list.sort方法和内置函数sorted
都是排序的函数,list.sort会改变原来的数据,但是内置函数sorted会改变原来的数据。
都有两个相同的参数:
- reverse:如果被设定为 True,被排序的序列里的元素会以降序输出。这个参数的默认值是 False。
- key:定义排序规则。比如说,在对一些字符串排序时,可以用 key=str. lower 来实现忽略大小写的排序,或者是用 key=len 进行基于字符串长度的排序。这
1.8. bisect的使用
1.8.1. 使用 bisect(haystack, needle) 搜索
两个参数:
- 有序列表
- 要查找的值
其他参数,用来指定查找范围:
- lo :默认0
- hi:默认size
返回索引。不管有没有查到,索引左边的元素均小于needle
import sys, bisect
HAYSTACK = [1, 4, 5, 6, 8, 12, 15, 20, 21, 23, 23, 26, 29, 30]
NEEDLES = [0, 1, 2, 5, 8, 10, 22, 23, 29, 30, 31]
ROW_FMT = '{0:2d} @ {1:2d} {2}{0:<2d}'
def demo(bisect_fn):
for needle in reversed(NEEDLES):
pos = bisect_fn(HAYSTACK, needle)
offset = pos * ' |'
print(ROW_FMT.format(needle, pos, offset))
if __name__ == '__main__':
if sys.argv[-1] == 'left':
bisect_fn = bisect.bisect_left
else:
bisect_fn = bisect.bisect
print('Demo:', bisect_fn.__name__)
print('haystack -> ', ' '.join('%2d' % n for n in HAYSTACK))
demo(bisect_fn)
输出结果:
E:\ProgramData\anaconda3\python.exe E:\workspace\python-projects\python_fluent\part1\chapter02\bisect_demo.py left
Demo: bisect_left
haystack -> 1 4 5 6 8 12 15 20 21 23 23 26 29 30
31 @ 14 | | | | | | | | | | | | | |31
30 @ 13 | | | | | | | | | | | | |30
29 @ 12 | | | | | | | | | | | |29
23 @ 9 | | | | | | | | |23
22 @ 9 | | | | | | | | |22
10 @ 5 | | | | |10
8 @ 4 | | | |8
5 @ 2 | |5
2 @ 1 |2
1 @ 0 1
0 @ 0 0
Process finished with exit code 0
bisect_left 返回的插入位置是原序列中跟被插入元素相等的元素的位置, 也就是新元素会被放置于它相等的元素之前,而 bisect_right 返回的则是跟它相等的元素 之后的位置
1.8.2. 使用insort插入
insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序。参数列表跟bisect一样。
import bisect, random
SIZE = 7
random.seed(56564)
my_list = []
for i in range(SIZE):
new_item = random.randrange(SIZE * 2)
bisect.insort(my_list, new_item)
print('%2d -> ' % new_item, my_list)
输出结果:
10 -> [10]
8 -> [8, 10]
10 -> [8, 10, 10]
7 -> [7, 8, 10, 10]
2 -> [2, 7, 8, 10, 10]
7 -> [2, 7, 7, 8, 10, 10]
13 -> [2, 7, 7, 8, 10, 10, 13]
1.9. 其他内置数据结构
1.9.1. array.array()
数组处理数据的速度比list tuple更快。array.array(p1, p2)
- p1:
'b':有符号字符(signed char)'B':无符号字符(unsigned char)'i':有符号整数(signed int)'I':无符号整数(unsigned int)'f':单精度浮点数(float)'d':双精度浮点数(double)
- p2:一个可迭代的对象
from array import array
from random import random
from time import time
floats = array('d', (random() for i in range(10 ** 7)))
print(floats[-1])
start_time = time()
fp = open('floats.bin', 'wb')
floats.tofile(fp)
fp.close()
print(f"write cost {time() - start_time} ms")
start_time = time()
floats2 = array('d')
fp = open('floats.bin', 'rb')
floats2.fromfile(fp, 10 ** 7)
fp.close()
print(floats2[-1])
print(f"read cost {time() - start_time} ms")
输出结果:
0.33779582248885887
write cost 0.025516748428344727 ms
0.33779582248885887
read cost 0.051999568939208984 ms
Process finished with exit code 0
1.9.2.内存试图 memoryview
内存视图其实是泛化和去数学化的 NumPy 数组。它让你在不需要复制内容的前提下, 在数据结构之间共享内存。其中数据结构可以是任何形式,比如 PIL 图片、SQLite 数据库和 NumPy 的数组,等等。这个功能在处理大型数据集合的时候非常重要。
memoryview.cast 的概念跟数组模块类似,能用不同的方式读写同一块内存数据,而且内容 字节不会随意移动
1.9.3. numpy 和 scipy
1.9.4. 队列
(一)双向队列 deque
collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的 数据类型。
构造方法参数:
iterable(可迭代对象):可选参数,用于初始化双端队列的元素。如果提供了可迭代对象,双端队列将包含该可迭代对象中的元素。maxlen(最大长度):可选参数,用于指定双端队列的最大长度。如果指定了最大长度,则双端队列将限制其长度,超出部分的元素将自动被移除。
常用方法:
append(x):向队列的右侧添加元素x。appendleft(x):向队列的左侧添加元素x。pop():移除并返回队列右侧的元素。popleft():移除并返回队列左侧的元素。extend(iterable):向队列的右侧扩展添加可迭代对象中的元素。extendleft(iterable):向队列的左侧扩展添加可迭代对象中的元素(元素的顺序与可迭代对象相反)。clear():移除队列中的所有元素。count(x):返回队列中等于x的元素数量。remove(value):移除队列中第一个值等于value的元素。reverse():反转队列中的元素。rotate(n):向右循环移动队列中的元素n步(如果n为负数,则向左循环移动)。
(二)队列queue
提供了同步(线程安全)类 Queue、LifoQueue 和 PriorityQueue,不同的线程可以利用 这些数据类型来交换信息。这三个类的构造方法都有一个可选参数 maxsize,它接收正 整数作为输入值,用来限定队列的大小。但是在满员的时候,这些类不会扔掉旧的元素 来腾出位置。相反,如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而 腾出了位置。这一特性让这些类很适合用来控制活跃线程的数量。
(三)multiprocessing
这个包实现了自己的 Queue,它跟 queue.Queue 类似,是设计给进程间通信用的。同时 还有一个专门的 multiprocessing.JoinableQueue 类型,可以让任务管理变得更方便。
(四)asyncio
Python 3.4 新提供的包,里面有Queue、LifoQueue、PriorityQueue 和 JoinableQueue, 这些类受到 queue 和 multiprocessing 模块的影响,但是为异步编程里的任务管理提供 了专门的便利
(五)heapq
跟上面三个模块不同的是,heapq 没有队列类,而是提供了 heappush 和 heappop 方法, 让用户可以把可变序列当作堆队列或者优先队列来使用
2. 字典和集合
字典就是map,映射。
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': '3'}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'two': 2, 'one': 1})
print(a == b == c == d == e) # True
2.0. 可散列的数据类型
- 如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变 的,而且这个对象需要实现
__hash__()方法。另外可散列对象还要有__eq__()方法,这样才可以跟其他键做比较。 - 原子不可变数据类型(
str、bytes和数值类型)都是可散列类型,frozenset也是可散 列的,因为根据其定义,frozenset里只能容纳可散列类型。元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。 list是不可散列的- 一般来讲用户自定义的类型的对象都是可散列的,散列值就是它们的
id()函数的返 回值,所以所有这些对象在比较的时候都是不相等的。 - 如果一个对象实现了
__eq__方 法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都 是不可变的情况下,这个对象才是可散列的。
2.1. 字典推导
DIAL_CODES = [(86, 'China'), (91, 'India'), (62, 'Indonesia'), (1, 'United States'), (7, 'Russia'), ]
country_code = {country: code for code, country in DIAL_CODES}
print(country_code) # {'China': 86, 'India': 91, 'Indonesia': 62, 'United States': 1, 'Russia': 7}
2.2. dict, defaultDict 和 OrderedDict
dict 是 Python 内置的映射类型,它是一种哈希表实现,提供了一种高效的方法来存储和检索数据。主要特点包括:
- 键必须是唯一的且不可变的(通常为字符串、整数或元组等不可变类型)。
- 支持通过键来快速检索值,具有很高的查找性能。
- 不保证元素的顺序,即插入顺序不会被保留。
- 字典的实现是无序的,因此迭代顺序可能会随着版本和数据结构的改变而改变。
collections.defaultdict 是 collections 模块提供的一种字典的子类,它允许指定默认值的字典。主要特点包括:
- 默认值类型可以是任意类型,例如整数、列表、集合等。
- 当使用一个不存在的键进行索引时,会自动创建默认值并返回,而不会抛出
KeyError异常。 - 对于不存在的键,
defaultdict会自动为其赋予默认值,这样可以简化代码并提高可读性。
collections.OrderedDict 是 collections 模块提供的有序字典类型。主要特点包括:
- 保留了元素插入的顺序,即字典会记住键值对的插入顺序。
- 在迭代时,会按照元素插入的顺序返回键值对,因此它是一个有序的字典类型。
- 从 Python 3.7 开始,
dict类型也开始保留元素插入的顺序,但在之前的 Python 版本中不是这样。
3.文本和字节
3.1. 字符
3.2. 字节
bytes 或 bytearray 对象的各个元素是介于0~255(含)之间的整数
- bytes 对象的切片还是 bytes 对象,即使是只有一个字节的切片。
- bytearray 对象的切片还是 bytearray 对象。
cafe = bytes('café', encoding='utf_8')
print(cafe) # b'caf\xc3\xa9'
print(cafe[0]) # 99
print(cafe[:1]) # b'c'
cafe_arr = bytearray(cafe)
print(cafe_arr) # bytearray(b'caf\xc3\xa9')
print(cafe_arr[-1:]) # bytearray(b'\xa9')
4.一等函数
一等函数定义:
• 在运行时创建
• 能赋值给变量或数据结构中的元素
• 能作为参数传给函数
• 能作为函数的返回结果
4.1.把函数作为对象
def factorial(n):
"""returns n!"""
return 1 if n < 2 else n * factorial(n - 1)
print(factorial(42)) # 1405006117752879898543142606244511569936384000000000
print(factorial.__doc__) # returns n!
print(type(factorial)) # <class 'function'>
fact = factorial
print(fact) # <function factorial at 0x000001D3195891C0>
print(fact(5)) # 120
print(list(map(fact, range(10)))) # [1, 1, 2, 6, 24, 120, 720, 5040, 40320, 362880]
4.2. 高阶函数
接受函数为参数,或者把函数作为结果返回的函数是高阶函数(higher-order function)。 例如 map ,filter,reduce
map(function, iterable)
作用: map() 函数将给定的函数应用于可迭代对象(如列表、元组或字符串)的每个项目,并返回结果的迭代器。
参数:
function: 要应用于可迭代对象每个项目的函数。iterable: 包含要传递给函数的项目的可迭代对象。
返回值: 一个迭代器,产生将函数应用于可迭代对象每个项目后的结果。
def factorial(n):
"""returns n!"""
return 1 if n < 2 else n * factorial(n - 1)
fact = factorial
print(list(map(fact, range(10)))) # [1, 1, 2, 6, 24, 120, 720, 5040, 40320, 362880]
filter(function, iterable)
作用: filter() 函数从可迭代对象中的元素构建一个迭代器,该元素由函数返回 True 的元素组成。
参数:
function: 对可迭代对象中的每个项目返回True或False的函数。如果为None,则返回True的元素。iterable: 包含要过滤的元素的可迭代对象。
返回值: 一个迭代器,产生函数返回 True 的可迭代对象中的元素。
def is_even(x):
return x % 2 == 0
result = filter(is_even, [1, 2, 3, 4, 5])
print(list(result)) # 2 4
**reduce(function, iterable[, initializer]) **
(在 Python 3 中,reduce() 函数已移至 functools 模块)
作用: reduce() 函数对可迭代对象中的顺序对值应用滚动计算。它用于对列表执行一些计算并返回结果。
参数:
function: 接受两个参数并返回单个值的函数。iterable: 包含要减少的元素的可迭代对象。initializer(可选): 开始计算的初始值。如果提供,则它将放置在计算中的可迭代对象的项目之前,并在可迭代对象为空时作为默认值。
返回值: 滚动计算的结果。是滚动计算,而不是分治计算
from functools import reduce
def add(x, y):
return x + y
result = reduce(add, [1, 2, 3, 4, 5])
print(result) # 输出: 15
4.3. 匿名函数
lambda 函数的定义体中不能赋值,也不能使用 while 和 try 等 Python 语句
4.4.可调用对象
除了用户定义的函数,调用运算符(即 ())还可以应用到其他对象上。如果想判断对象能 否调用,可以使用内置的 callable() 函数。。Python 数据模型文档列出了 7 种可调用对象:
- 用户定义的函数:使用 def 语句或 lambda 表达式创建。
- 内置函数:使用 C 语言(CPython)实现的函数,如
len或time.strftime - 内置方法:使用 C 语言实现的方法,如
dict.get。 - 方法:在类的定义体中定义的函数。
- 类:调用类时会运行类的
__new__方法创建一个实例,然后运行__init__方法,初始化实 例,最后把实例返回给调用方。(通常,调用类会创建那个类的实例,不过覆盖__new__方法的话,也可能出现 其他行为。 - 类的实例:如果类定义了
__call__方法,那么它的实例可以作为函数调用。 - 生成器函数:使用
yield关键字的函数或方法。调用生成器函数返回的是生成器对象。
4.5.用户定义的可调用类型
不仅 Python 函数是真正的对象,任何 Python 对象都可以表现得像函数。为此,只需实现 实例方法 __call__。
import random
class BingoCage:
def __init__(self, items):
self._items = list(items)
random.shuffle(self._items)
def pick(self):
try:
return self._items
except IndexError:
raise LookupError('pick from empty BingoCage')
def __call__(self, *args, **kwargs):
return self.pick()
if __name__ == '__main__':
bingo = BingoCage(range(3))
print(bingo.pick()) # [0, 1, 2]
print(bingo()) # [0, 1, 2]
实现 __call__ 方法的类是创建函数类对象的简便方式,此时必须在内部维护一个状态,让 它在调用之间可用,例如 BingoCage 中的剩余元素。
创建保有内部状态的函数,还有一种截然不同的方式——使用闭包。
4.6. 函数内省
4.6.1.__dict__
函数使用 __dict__ 属性存储赋予它的用户属性。这相当于一种 基本形式的注解。
4.7. 从定位参数到仅限关键字参数
Python 最好的特性之一是提供了极为灵活的参数处理机制,而且 Python 3 进一步提供了仅 限关键字参数(keyword-only argument)。与之密切相关的是,调用函数时使用* 和 **“展 开”可迭代对象,映射到单个参数。
def tag(name, *content, cls=None, **attrs):
"""生成一个或多个HTML标签"""
if cls is not None:
attrs['class'] = cls
if attrs:
attr_str = ''.join(' %s="%s"' % (attr, value) for attr, value in sorted(attrs.items()))
else:
attr_str = ''
if content:
return '\n'.join('<%s%s>%s</%s>' % (name, attr_str, c, name) for c in content)
else:
return '<%s%s />' % (name, attr_str)
print(tag('br')) # <br />
print(tag('p', 'hello')) # <p>hello</p>
print(tag('p', 'hello', 'world')) # <p>hello</p> \n <p>world</p>
print(tag('p', 'hello', id=33, cls='sidebar')) # <p class="sidebar" id="33">hello</p>
print(tag(content='hello', name='img')) # <img content="hello" />
my_tag = {'name': 'img', 'title': 'Sunset Boulevard', 'src': 'sunset.jpg', 'cls': 'framed'}
print(tag(**my_tag)) # <img class="framed" src="sunset.jpg" title="Sunset Boulevard" />
print(tag('p', 'hello', id=33, cls='sidebar'))中,print(tag(**my_tag)), 在my_tag前面加上**,字典中的所有元素作为单个参数传入,同名键会绑定到对应的 具名参数上,余下的则被**attrs捕获
*(星号)用于解包可迭代对象,将可迭代对象中的元素作为位置参数传递给函数。**(双星号)用于解包字典,将字典中的键值对作为关键字参数传递给函数。
4.8. 获取关于参数的信息
4.9. 函数注解
Python 3 提供了一种句法,用于为函数声明中的参数和返回值附加元数据:
函数声明中的各个参数可以在 : 之后增加注解表达式。如果参数有默认值,注解放在参数名和=号之间。
如果想注解返回值,在 ) 和函数声明末尾的 : 之间添加->和一个表达式。 那个表达式可以是任何类型。注解中最常用的类型是类(如 str 或 int)和字符串(如 'int > 0')。
注解不会做任何处理,只是存储在函数的 __annotations__ 属性(一个字典)中
def clip(text: str, max_len: 'int > 0' = 80) -> str:
"""在max_len前面或后面的第一个空格处截断文本"""
end = None
if len(text) > max_len:
space_before = text.rfind(' ', 0, max_len)
if space_before >= 0:
end = space_before
else:
space_after = text.rfind(' ', max_len)
if space_after >= 0:
end = space_after
if end is None: # 没找到空格
end = len(text)
return text[:end].rstrip()
print(clip.__annotations__) # {'text': <class 'str'>, 'max_len': 'int > 0', 'return': <class 'str'>}
提取注解: inspect.signature() 函数。signature 函数返回一个Signature 对 象, 它 有 一 个return_annotation 属性和一个 parameters 属性,后者是一个字典,把参数名映射到 Parameter 对象上。每个 Parameter 对象自己也有 annotation 属性。
from inspect import signature
sig = signature(clip)
print(sig.return_annotation) # {'text': <class 'str'>, 'max_len': 'int > 0', 'return': <class 'str'>}
for param in sig.parameters.values():
note = repr(param.annotation).ljust(13)
print(note, ':', param.name, '=', param.default)
# 循环输出:
# <class 'str'>
# <class 'str'> : text = <class 'inspect._empty'>
# 'int > 0' : max_len = 80
4.10. 支持函数式编程的包
4.10.1. operator模块
operator模块提供了一组对Python内置运算符进行函数形式封装的工具。这些函数可以用于更简洁和直观地执行诸如算术、逻辑和比较等操作。以下是operator模块中一些常用的函数:
- 算术运算符函数:
add(a, b): 返回a和b的和。sub(a, b): 返回a和b的差。mul(a, b): 返回a和b的乘积。truediv(a, b): 返回a除以b的结果(浮点数)。floordiv(a, b): 返回a除以b的结果(整数部分)。mod(a, b): 返回a除以b的余数。pow(a, b): 返回a的b次幂。
- 比较运算符函数:
eq(a, b): 检查a和b是否相等。ne(a, b): 检查a和b是否不相等。lt(a, b): 检查a是否小于b。le(a, b): 检查a是否小于等于b。gt(a, b): 检查a是否大于b。ge(a, b): 检查a是否大于等于b。
- 逻辑运算符函数:
and_(a, b): 返回a和b的逻辑与。or_(a, b): 返回a和b的逻辑或。not_(a): 返回a的逻辑非。
- 位运算符函数:
and_(a, b): 返回a和b的按位与。or_(a, b): 返回a和b的按位或。xor(a, b): 返回a和b的按位异或。invert(a): 返回a的按位取反。lshift(a, b): 返回a左移b位的结果。rshift(a, b): 返回a右移b位的结果。
- 其它:
itemgetter(*items): 创建一个函数,用于获取对象的指定索引或键的值。attrgetter(*attrs): 创建一个函数,用于获取对象的指定属性的值。methodcaller(name, *args, **kwargs): 创建一个函数,用于调用对象的指定方法。
metro_data = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
# itemgetter
from operator import itemgetter
for city in sorted(metro_data, key=itemgetter(1)):
print(city) # 顺序输出根据第2列排序后的结果
cc_name = itemgetter(0, 1)
for city in metro_data:
print(cc_name(city)) # 只输出 ('Tokyo', 'JP') 信息
# attrgetter
from collections import namedtuple
LatLong = namedtuple('LatLong', 'lat long')
Metropolis = namedtuple('Metropolis', 'name cc pop coord')
metro_areas = [Metropolis(name, cc, pop, LatLong(lat, long)) for name, cc, pop, (lat, long) in metro_data]
print(metro_areas[0])
from operator import attrgetter
name_lat = attrgetter('name', 'coord.lat')
for city in sorted(metro_areas, key=attrgetter('coord.lat')): # 根据属性coord.lat进行排序
print(name_lat(city)) # 只打印出 具体属性对应的 值
# methodcaller
from operator import methodcaller
ss = 'The time has come'
upper = methodcaller('upper')
print(upper(ss)) # THE TIME HAS COME
hiphenate = methodcaller('replace', ' ', '-')
print(hiphenate(ss)) # The-time-has-come
4.10.2. functools.partia 冻结参数
functools.partial 这个高阶函数用于部分应用一个函数。部分应用是指,基于一个函数创 建一个新的可调用对象,把原函数的某些参数固定。使用这个函数可以把接受一个或多个 参数的函数改编成需要回调的 API,这样参数更少。
from functools import partial
from operator import mul
from unicodedata import normalize
triple = partial(mul, 3) # 把第一个参数约定为3
print(triple(7))
nfc = partial(normalize, 'NFC') # 使用 partial 构建一个便利的 Unicode 规范化函数
from python_fluent.part2.chapter05.func_inner_par import tag
picture = partial(tag, 'img', cls='pic-frame') # 第一个参数约定为 img,,把 cls 关键字参数固定 为 'pic-frame'
print(picture) # functools.partial(<function tag at 0x000001FAD351BE20>, 'img', cls='pic-frame')
print(picture.func) # <function tag at 0x000001FAD351BE20>
print(picture.args) # ('img',)
print(picture.keywords) # {'cls': 'pic-frame'}
print(picture('wumps.jpg')) # <img class="pic-frame">wumps.jpg</img>
functools.partialmethod 函数(Python 3.4 新增)的作用与 partial 一样,不过是用于处理方法的。
python函数的参数:
- 位置参数:位置参数是函数定义中的必需参数,调用函数时需要按照顺序传入对应的参数值。
- 默认参数:默认参数是在函数定义时给参数赋予一个默认值,调用函数时如果没有提供该参数的值,则使用默认值。默认参数必须放在位置参数后面。
- 可变数量参数:可变数量参数允许函数接受任意数量的参数。在函数定义中,可变数量参数使用
*args来表示,它将接收所有位置参数,并将它们作为元组传递给函数体。- 关键字参数:关键字参数允许在函数调用时通过键值对的形式传递参数,这样可以避免参数位置的固定顺序。在函数定义中,关键字参数使用
**kwargs来表示,它将接收所有关键字参数,并将它们作为字典传递给函数体。
- 位置参数搜集和关键字参数搜集:通过
*args和**kwargs分别表示收集位置参数和收集关键字参数,它们在函数定义时用于收集不定数量的参数。 - 在调用函数时,可以使用
*和**来解构序列和字典,并将其传递给函数的参数
5.使用一等函数实现设计模式
6.函数装饰器和闭包
函数装饰器用于在源码中“标记”函数,以某种方式增强函数的行为。
6.1. 装饰器基础知识
装饰器是可调用的对象,其参数是另一个函数(被装饰的函数)。
装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象。
def deco(func):
def inner():
print("inner Target()")
return inner
@deco
def target():
print("running target")
# 调用被装饰的 target 其实会运行 inner
target() # inner Target()
print(target) # <function deco.<locals>.inner at 0x000002213780BD80>
装饰器的一大特性是,能把被装饰的函数替换成其他函数。第二个特性是,装饰器 在加载模块时立即执行。
6.2. Python如何执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行。这通常是在导入时 (即 Python 加载模块时)
registry = []
def register(func):
print('Running register(%s)' % func)
registry.append(func)
return func
@register
def f1():
print("Running f1")
@register
def f2():
print("Running f2")
def f3():
print("Running f3")
if __name__ == '__main__':
print("running main")
print("registry -> ", registry)
f1()
f2()
f3()
程序的输出是:
Running register(<function f1 at 0x000002615C53BE20>)
Running register(<function f2 at 0x000002615C53BEC0>)
running main
registry -> [<function f1 at 0x000002615C53BE20>, <function f2 at 0x000002615C53BEC0>]
Running f1
Running f2
Running f3
- 装饰器函数与被装饰的函数在同一个模块中定义。实际情况是,装饰器通常在一个模块 中定义,然后应用到其他模块中的函数上。
- register 装饰器返回的函数与通过参数传入的相同。实际上,大多数装饰器会在内部定 义一个函数,然后将其返回
6.3. 使用装饰器改进策略模式
6.4. 变量作用域规则
Python中,变量的作用域指的是变量可被访问的范围,包括:
-
全局作用域(Global Scope):
-
在模块顶层定义的变量拥有全局作用域,它们可以在整个模块中被访问
-
在函数外部定义的变量默认为全局变量。
-
全局变量可以在函数内部被访问,但不能在函数内部修改其值(除非使用
global关键字声明)。def f1(a): print(a) print(b) # py认为b是全局变量 # b = 7 # 修改值会报错。 b = 1 f1(2)如果要让上述程序无错误,需要添加
global声明。def f1(a): print(a) global b # 在b使用之前声明 print(b) b = 7 b = 1 f1(2)
-
-
局部作用域(Local Scope):
- 在函数内部定义的变量拥有局部作用域,它们只能在函数内部被访问。
- 局部变量在函数执行结束后会被销毁,不再可用。
- 如果局部变量与全局变量同名,则在函数内部会优先使用局部变量。
-
嵌套作用域(Enclosing Scope):
- 当函数嵌套在另一个函数中时,内部函数可以访问外部函数的变量,但外部函数不能访问内部函数的变量。
- 内部函数可以访问外部函数的局部变量和全局变量。
-
内置作用域(Built-in Scope):
- 内置作用域包含Python中的内置函数和异常名称。这些名称不需要导入即可直接使用。
6.5. 闭包
只有涉及嵌套函数时才有闭包问题。
闭包指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的 非全局变量。函数是不是匿名的没有关系,关键是它能访问定义体之外定义的非全局变量。
# 计算滑动值的平均值 以下输出结果是一样的
class Averager:
def __init__(self):
self.series = []
def __call__(self, new_val):
self.series.append(new_val)
total = sum(self.series)
return total / len(self.series)
ave = Averager()
print(ave(10))
print(ave(11))
print(ave(12))
# 闭包
def make_averager():
series = []
def averager(new_val):
series.append(new_val)
total = sum(series)
return total / len(series)
return averager
avg = make_averager()
print(avg(10))
print(avg(11))
print(avg(12))
make_averager函数的局部变量series在函数被调用后应该消亡,但是实际上并没有。series 是自由变量(free variable)。
Python 在__code__属性(表示编译后的函数定义体) 中保存局部变量和自由变量的名称.
series 的绑定在返回的avg 函数的__closure__ 属性中。avg.__closure__ 中的各个元 素对应于avg.__code__.co_freevars 中的一个名称。这些元素是cell 对象,有个cell_ contents 属性,保存着真正的值。
print(avg.__code__.co_varnames) # ('new_val', 'total')
print(avg.__code__.co_freevars) # ('series',)
print(avg.__closure__[0].cell_contents) # [10, 11, 12]
闭包是一种函数,它会保留定义函数时存在的自由变量的绑定,这样调用函数时, 虽然定义作用域不可用了,但是仍能使用那些绑定。
自由变量不能被嵌套函数改变其值(数字为值,对象类型为引用)。
6.6. nonlocal声明
nonlocal 的作用是把变量标记为自由变量, 即使在函数中为变量赋予新值了,也会变成自由变量。
def make_averager():
total = 0
count = 0
def averager(new_val):
nonlocal total, count
count += 1
total += new_val
return total / count
return averager
avg = make_averager()
print(avg(10))
print(avg(11))
print(avg(12))
print(avg.__code__.co_varnames) # ('new_val')
print(avg.__code__.co_freevars) # ('count', 'total')
print(avg.__closure__[0].cell_contents, avg.__closure__[1].cell_contents) # 3 33
6.7. 实现一个简单的装饰器
需求:装饰器打印出每个被装饰的函数的执行时间,输入和输出。
# clock_decorator.py
import time
def clock(func):
def clocked(*args):
t0 = time.perf_counter()
result = func(*args)
elapsed = time.perf_counter() - t0
name = func.__name__
arg_str = ', '.join(repr(arg) for arg in args)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked
# clock_demo.py
from clock_decorator import clock
import time
@clock
def snooze(sec):
time.sleep(sec)
@clock
def factorial(n):
return 1 if n < 2 else n * factorial(n - 1)
if __name__ == '__main__':
print('*' * 40, 'Calling snooze(.123)')
snooze(.123)
print('*' * 40, 'Calling factorial(6)')
print('6 != ', factorial(6))
输出为:
**************************************** Calling snooze(.123)
[0.12384130s] snooze(0.123) -> None
**************************************** Calling factorial(6)
[0.00000060s] factorial(1) -> 1
[0.00000690s] factorial(2) -> 2
[0.00001140s] factorial(3) -> 6
[0.00001500s] factorial(4) -> 24
[0.00001840s] factorial(5) -> 120
[0.00002270s] factorial(6) -> 720
6 != 720
上述装饰器的不足:
- 不支持关键字参数
- 遮盖了被装饰函数 的
__name__和__doc__属性
使用@functools.wraps装饰器:
# clock_decorator2.py
import time
import functools
def clock(func):
@functools.wraps(func)
def clocked(*args, **kwargs):
t0 = time.perf_counter()
result = func(*args, **kwargs)
elapsed = time.perf_counter() - t0
name = func.__name__
arg_list = []
if args:
arg_list.append(', '.join(repr(arg) for arg in args))
if kwargs:
pair = ['%s=%r' % (k, v) for k, v in kwargs.items()]
arg_list.append(', '.join(pair))
print('[%0.8fs] Method:%s, Param:%s, Return:%r' % (elapsed, name, arg_list, result))
return result
return clocked
from clock_decorator2 import clock
@clock
def tag(name, *content, cls=None, **attrs):
"""生成一个或多个HTML标签"""
if cls is not None:
attrs['class'] = cls
if attrs:
attr_str = ''.join(' %s="%s"' % (attr, value) for attr, value in sorted(attrs.items()))
else:
attr_str = ''
if content:
return '\n'.join('<%s%s>%s</%s>' % (name, attr_str, c, name) for c in content)
else:
return '<%s%s />' % (name, attr_str)
if __name__ == '__main__':
my_tag = {'name': 'img', 'title': 'Sunset Boulevard', 'src': 'sunset.jpg', 'cls': 'framed'}
res = tag(**my_tag)
# 最后输出
# [0.00000750s] Method:tag, Param:["name='img', title='Sunset Boulevard', src='sunset.jpg', cls='framed'"], Return:'<img class="framed" src="sunset.jpg" title="Sunset Boulevard" />'
6.8. 标准库的装饰器
Python 内置了三个用于装饰方法的函数:property、classmethod 和 staticmethod。另外一些常见的装饰器是functools.wraps,lru_cache 和全新的 singledispatch它的作用是协助构建行为良好的装饰
6.8.1. 使用functools.lru_cache做备忘
functools.lru_cache 是非常实用的装饰器,它实现了备忘(memoization)功能。这是一 项优化技术,它把耗时的函数的结果保存起来,避免传入相同的参数时重复计算。LRU 三 个字母是“Least Recently Used”的缩写,表明缓存不会无限制增长,一段时间不用的缓存 条目会被扔掉。
import functools
from clock_decorator import clock
@functools.lru_cache()
@clock
def fibonacci(n):
return n if n < 2 else fibonacci(n - 1) + fibonacci(n - 2)
if __name__ == '__main__':
print('*' * 40, 'Calling factorial(30)')
print('6 != ', fibonacci(30))
@functools.lru_cache()写在@clock之上,表示作用于clock的结果- 必须像常规函数那样调用
lru_cache。这一行中有一对括号:@functools.lru_ cache()。这么做的原因是,lru_cache可以接受配置参数。
函数的签名:functools.lru_cache(maxsize=128, typed=False):
maxsize参数指定存储多少个调用的结果。缓存满了之后,旧的结果会被扔掉,腾出空间。 为了得到最佳性能,maxsize应该设为 2 的幂typed参数如果设为True,把不同参数类型 得到的结果分开保存,即把通常认为相等的浮点数和整数参数(如 1 和 1.0)区分开
因为
lru_cache使用字典存储结果,而且键根据调用时传入的定位参数和关键 字参数创建,所以被lru_cache装饰的函数,它的所有参数都必须是可散列的
6.8.2. 单分派泛函数
Python 不支持重载方法或函数,所以我们不能使用不同的签名定义 函数 的变体, 也无法使用不同的方式处理不同的数据类型。
使用 @singledispatch 装饰的普通函数会变成 泛函数(generic function):根据第一个参数的类型,以不同方式执行相同操作的一组函 数。
import html
import numbers
from collections import abc
from functools import singledispatch
@singledispatch
def htmlize(obj):
content = html.escape(repr(obj))
return '<pre>{}</pre>'.format(content)
@htmlize.register(str)
def _(text):
content = html.escape(text).replace('\n', '<br>\n')
return '<p>{}</p>'.format(content)
@htmlize.register(numbers.Integral)
def _(n):
return '<pre>{0} (0x{0:x})</pre>'.format(n)
@htmlize.register(tuple)
@htmlize.register(abc.MutableSequence)
def _(seq):
inner = '</li>\n<li>'.join(htmlize(item) for item in seq)
return '<ul>\n<li>' + inner + '</li>\n</ul>'
if __name__ == '__main__':
print(htmlize({1, 2, 3})) # <pre>{1, 2, 3}</pre>
print(htmlize(abs)) # <pre><built-in function abs></pre>
print(htmlize('Heimlich & Co.\n- a game'))
"""
<p>Heimlich & Co.<br>
- a game</p>
"""
print(htmlize(42)) # <pre>42 (0x2a)</pre>
print(htmlize(['alpha', 66, {3, 2, 1}]))
"""
<ul>
<li><p>alpha</p></li>
<li><pre>66 (0x42)</pre></li>
<li><pre>{1, 2, 3}</pre></li>
</ul>
"""
使用总结:
@singledispatch标记处理object类型的基函数(设定函数名为:base_function)- 各个专门函数使用
@base_functio.register({type})装饰 - 专门函数的名称无关紧要;
_是个不错的选择,简单明了. - 为每个需要特殊处理的类型注册一个函数。
numbers.Integral是int的虚拟超类 。 - 可以叠放多个
register装饰器,让同一个函数支持不同类型
6.9. 叠放装饰器
6.10. 参数化装饰器
7. 对象引用、可变性和垃圾回收
7.1. == vs is
==运算符比较两个对象的值(对象中保存的数据),而is比较对象的标识。- is 运算符比 == 速度快,因为它不能重载,所以 Python 不用寻找并调用特殊方法,而是直 接比较两个整数 ID.
- 而
a == b是语法糖,等同于a.__eq__(b)。继承自 object 的__eq__方法比较两个对象的 ID,结果与is一样.
7.2. 元组的相对不可变性
- 元组与多数 Python 集合(列表、字典、集,等等)一样,保存的是对象的引用。
- 如果引 用的元素是可变的,即便元组本身不可变,元素依然可变。也就是说,元组的不可变性其 实是指 tuple 数据结构的物理内容**(即保存的引用)不可变**,与引用的对象无关.
7.3. 默认做浅复制
- 构造方法或
[:]做的是浅复制(即复制了最外层容器,副本中的元素是源容器中元 素的引用)。 - 想要做深复制,
copy模块提供的deepcopy和copy函数能为任意对象做深复制和浅复制 - 深拷贝需要考虑循环引用的情况,在类中重写
def __copy__(self): pass和def __deepcopy__(self, memodict={}): pass方法解决。
7.4. 函数的参数作为引用时
Python 唯一支持的参数传递模式是共享传参(call by sharing)。多数面向对象语言都采用 这一模式,包括 Ruby、Smalltalk 和 Java(Java 的引用类型是这样,基本类型按值传参)。
这种方案的结果是,函数可能会修改作为参数传入的可变对象,但是无法修改那些对象的标识(即不能把一个对象替换成另一个对象)。
7.4.1. 不要使用可变类型作为参数的默认值
如果默认 值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。可变默认值导致的这个问题说明了为什么通常使用 None 作为接收可变值的参数的默认值
7.4.2. 防御可变参数
7.5. del 与 垃圾回收
del 语句删除名称,而不是对象。del 命令可能会导致对象被当作垃圾回收,但是仅当删除 的变量保存的是对象的最后一个引用,或者无法得到对象时。
有个__del__特殊方法,但是它不会销毁实例,不应该在代码中调用。即将销 毁实例时,Python 解释器会调用__del__方法,给实例最后的机会,释放外部资源。类似于Java 的finalize方法
7.6. 弱引用
7.7. Python对不可变类型施加的把戏
8. 符合Python风格的对象
8.1. 对象表现形式
python 获取对象的字符串表示形式的标准方式:
repr():以便于开发者理解的方式返回对象的字符串表示形式。str():以便于用户理解的方式返回对象的字符串表示形式。
其他表现形式函数:
bytes()函数调用它获取对象的字节序列表示形式__format__方法会被内置的format()函数和str.format()方法调用,使用特殊的格式 代码显示对象的字符串表示形式。
# vector2d_v0.py
import math
from array import array
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.x = x
self.y = y
def __iter__(self):
return (i for i in (self.x, self.y))
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return bytes([ord(self.typecode)]) + bytes(array(self.typecode, self))
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
from vector2d_v0 import Vector2d
v1 = Vector2d(3, 4)
v1_clone = eval(repr(v1)) # eval执行某个表达式 返回一个对象
print(v1) # (3, 4)
print(v1_clone) # (3, 4)
print(v1 == v1_clone) # True
print(bytes(v1)) # b'd\x00\x00\x00\x00\x00\x00\x08@\x00\x00\x00\x00\x00\x00\x10@'
print(abs(v1)) # 5.0
print(bool(v1), bool(Vector2d(0, 0))) # True False
注意上述
==存在这种情况: Vector2d(3, 4) == [3, 4] 为True
8.2. 备选构造方法
可以把 Vector2d 实例转换成字节序列了;同理,也应该能从字节序列转换成 Vector2d 实例。
添加方法如下:
class Vector2d:
# ...
@classmethod
def frombytes(cls, octets):
# chr() 返回指定 Unicode 码点对应的字符
typecode = chr(octets[0]) # 从第一个字节中读取 typecode
memv = memoryview(octets[1:]).cast(typecode)
return cls(*memv)
8.3. classmethod与staticmethod
classmethod:定义操作类,而不是操作实例的方法。类方法的第一个参数名为cls。staticmethod:也会改变方法的调用方式,但是第一个参数不是特殊的值。
8.4. 格式化显示
内置的format() 函数和str.format() 方法把各个类型的格式化方式委托给相应的.__format__(format_spec)方法
8.5. 可散列的Vector
想要散列Vector,需要满足以下几点:
Vector实现了__hash____eq__方法Vector的hash值跟本身状态无关。可以理解为Vector无状态。
为了实现第二点,即将Vector的属性x和y变为一旦设置不可更改。需要作如下改动:
- 使用两个前导下划线(尾部没有下划线,或者有一个下划线),把属性标记为私有的。
@property装饰器把读值方法标记为特性。- 读值方法与公开属性同名,都是
x。 - 需要读取
x和y分量的方法可以保持不变,通过self.x和self.y读取公开特性,而不 必读取私有属性。
import math
from array import array
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.__x = float(x)
self.__y = float(y)
@property
def x(self):
return self.__x
@property
def y(self):
return self.__y
def __iter__(self):
return (i for i in (self.x, self.y))
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return bytes([ord(self.typecode)]) + bytes(array(self.typecode, self))
def __hash__(self):
return hash(self.x()) ^ hash(self.y)
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
# chr() 返回指定 Unicode 码点对应的字符
typecode = chr(octets[0]) # 从第一个字节中读取 typecode
memv = memoryview(octets[1:]).cast(typecode)
return cls(*memv)
from vector2d_v1 import Vector2d
v1 = Vector2d(3, 4)
hash(v1) # True
8.6. 私有属性和“受保护的”属性
python没有提供private关键字,公共属性可能会被子类的属性覆盖。为了避免这种情况,假设有父类Dog和子类Beagle,同名属性为mood,则如果以 __mood 的形式(两个前导下划线,尾部没有或最多有一个下划 线)命名实例属性,Python 会把属性名存入实例的 __dict__ 属性中,而且会在前面加上一 个下划线和类名。因此,对 Dog 类来说,__mood 会变成 _Dog__mood;对 Beagle 类来说,会 变成 _Beagle__mood。这个语言特性叫名称改写(name mangling)。
但是上述不能保证一定没问题。例子v1._Vector__x = 7
8.7. __slots__
继承自超类的__slots__ 属性没有效果。Python 只会使用各个类中定义的 __slots__ 属性
在Python中,__slots__是一个特殊的变量,用于指定一个类的实例能够存在的属性集合。通常情况下,Python类的实例可以动态地添加任意的属性。然而,当你需要限制一个类的实例只能拥有特定的属性时,就可以使用__slots__。
使用__slots__有以下几个优点:
- 减少内存消耗:使用
__slots__可以避免每个实例都创建一个__dict__字典来存储实例的属性,从而节省内存。 - 提高访问速度:由于实例属性是固定的,Python可以使用更快的方式来访问这些属性。
以下是一个简单的例子,演示了如何使用__slots__:
class Person:
__slots__ = ('name', 'age') # 只允许实例有'name'和'age'属性
def __init__(self, name, age):
self.name = name
self.age = age
# 创建一个Person实例
person = Person('Alice', 30)
# 添加一个新属性将会引发AttributeError
# person.address = '123 Main Street' # 这一行会报错
# 访问允许的属性是允许的
print(person.name) # 输出: Alice
print(person.age) # 输出: 30
8.8. 覆盖类属性
类属性:不写在__init__以及其他函数里面,直接函数的外面,类的里面。
9. 序列的修改、散列和切片
10. 从协议到抽象
10.1. 标准库中的抽象基类
10.1.1. collections.abc模块中的抽象基类
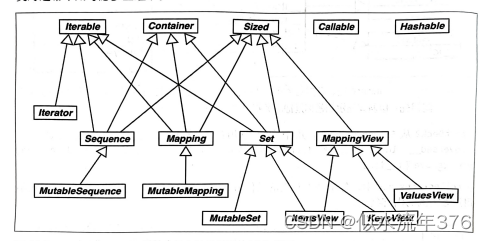
(1)Iterable、Container 和 Sized
各个集合应该继承这三个抽象基类,或者至少实现兼容的协议。Iterable 通过__iter__方法支持迭代,Container 通过 __contains__ 方法支持 in 运算符,Sized 通过__len__方法支持 len() 函数。
(2)Sequence、Mapping 和 Set
这三个是主要的不可变集合类型,而且各自都有可变的子类。
(3)MappingView
在 Python 3 中,映射方法 .items()、.keys() 和 .values() 返回的对象分别是 ItemsView、 KeysView 和 ValuesView 的实例。前两个类还从 Set 类继承了丰富的接口。
(4)Callable 和 Hashable
这两个抽象基类与集合没有太大的关系,只不过因为 collections.abc 是标准库中定义 抽象基类的第一个模块,而它们又太重要了,因此才把它们放到 collections.abc 模块 中。这两个抽象基类的主要作用是为内置函 数isinstance提供支持,以一种安全的方式判断对象能不能调用或散列。
(5)Iterator
注意它是 Iterable 的子类。
10.1.2. 抽象基类的数字塔
numbers 包(https://docs.python.org/3/library/numbers.html)定义的是“数字塔”(即各个抽 象基类的层次结构是线性的),其中 Number 是位于最顶端的超类,随后是 Complex 子类, 依次往下,最底端是 Integral 类。
• Number
• Complex
• Real
• Rational
• Integral
如果想检查一个数是不是整数,可以使用 isinstance(x, numbers.Integral),这样 代码就能接受 int、bool(int 的子类),或者外部库使用 numbers 抽象基类注册的其他类 型。
如果一个值可能是浮点数类型,可以使用isinstance(x, numbers.Real)检查。 这样代码就能接受 bool、int、float、fractions.Fraction,或者外部库(如 NumPy,它 做了相应的注册)提供的非复数类型。
10.2. 声明抽象基类
类实现或继承的公开属性(方 法或数据属性),包括特殊方法,如__getitem__或 __add__。
声明抽象基类最简单的方式是继承abc.ABC或其他抽象基类。以下是一个抽象基类:
import abc
import random
class Tombola(abc.ABC):
"""抽象基类"""
@abc.abstractmethod
def load(self, iterable) -> None:
"""从可迭代对象中添加元素"""
@abc.abstractmethod
def pick(self):
"""随机删除元素,然后将其返回"""
def loaded(self) -> bool:
"""如果至少有一个元素,返回True"""
return bool(self.inspect())
def inspect(self) -> tuple:
"""返回一个有序数组,由当前元素组成"""
items = []
while True:
try:
items.append(self.pick())
except LookupError:
break
self.load(items)
return tuple(sorted(items))
11. 继承的优缺点
11.1. 多重继承和方法解析顺序
菱形继承:
class A:
def ping(self):
print('ping:', self)
class B(A):
def pong(self):
print('pong B:', self)
class C(A):
def pong(self):
print('pong C:', self)
class D(B, C):
def pingpong(self):
self.ping()
self.pong()
if __name__ == '__main__':
print(D.__mro__)
d = D() # (<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
d.pong() # pong B: <__main__.D object at 0x0000027AD38FD490>
12. 运算符重载
重载对象:一元运算符(~ -) 和 中缀运算符+ |等
• 不能重载内置类型的运算符
• 不能新建运算符,只能重载现有的
• 某些运算符不能重载——is、and、or 和 not(不过位运算符 &、| 和 ~ 可以)
12.1. 一元运算符
三个运算符和对应的特殊方法:
-=>__neg__:一元取负运算符+=>__pos__:一元取整运算符,定义为+x = x,除了decimal精度不一致的场景~=>__invert__:对整数按位取反,定义为~x == ~(x+1)
对于+ -返回的结果应该是副本,而对于~没有一致的要求,例如可以表示反集。
12.2. 中缀运算符:
在Python中,中缀运算符有对应的特殊方法名称,它们用于在类中定义这些运算符的行为。下面是一些常见的中缀运算符及其对应的方法名称:
- 加法:
+-__add__ - 减法:
--__sub__ - 乘法:
*-__mul__ - 除法:
/-__truediv__ - 取整除法:
//-__floordiv__ - 模除法:
%-__mod__ - 乘方:
**-__pow__ - 等于:
==-__eq__ - 不等于:
!=-__ne__ - 小于:
<-__lt__ - 小于等于:
<=-__le__ - 大于:
>-__gt__ - 大于等于:
>=-__ge__ - 位与:
&-__and__ - 位或:
|-__or__ - 位异或:
^-__xor__ - 左移:
<<-__lshift__ - 右移:
>>-__rshift__
这些方法名称在定义类时被称为特殊方法(或魔术方法),通过实现它们,可以自定义类的行为以支持对应的运算符。
在Python中,特殊方法用于定义对象在执行特定操作时的行为。这些方法可以分为三类:正向方法(forward methods)、反向方法(reverse methods)和就地方法(in-place methods)。
- 正向方法(forward methods):这些方法是常规的操作符重载方法,它们定义了对象在左侧是操作数时的行为。例如,在
a + b表达式中,a是左操作数,b是右操作数,因此在a上定义__add__()方法会被调用。 - 反向方法(reverse methods):反向方法用于当对象是右操作数时的行为。当左操作数的方法未定义时,Python 解释器会尝试调用右操作数的对应反向方法。例如,在
a + b表达式中,如果a没有定义__add__()方法,Python 将尝试调用b的__radd__()方法。 - 就地方法(in-place methods):这些方法在原地修改对象的值,而不是创建一个新的对象。例如,
a += b表达式将调用a的__iadd__()方法,如果定义了该方法的话。如果没有定义,则会退回到正向方法,即__add__(),然后再赋值给a。
对于算符表达式:
定义一个类,并且想要支持比较运算符时,可以实现对应的正向比较方法(例如__lt__、__le__、__eq__、__ne__、__gt__、__ge__),如果在比较时对象类型不匹配或者不支持,可以让方法返回NotImplemented,这样Python会尝试调用反向方法来完成比较。
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
print("Forward less than method called")
if isinstance(other, MyClass):
return self.value < other.value
else:
return NotImplemented
def __gt__(self, other):
print("Reverse greater than method called")
if isinstance(other, MyClass):
return self.value > other.value
else:
return NotImplemented
a = MyClass(5)
b = MyClass(10)
result1 = a < b # Forward less than method called
result2 = b > a # Reverse greater than method called
增值运算符对应的魔术方法(就是就地方法):
- 加法赋值(
+=) -__iadd__ - 减法赋值(
-=) -__isub__ - 乘法赋值(
*=) -__imul__ - 除法赋值(
/=) -__itruediv__ - 取模赋值(
%=) -__imod__ - 幂赋值(
**=) -__ipow__ - 取整除赋值(
//=) -__ifloordiv__
11. 可迭代的对象、迭代器和生成器
迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据 项的方式,即按需一次获取一个数据项。
在 Python 语言内部,迭代器用于支持:
- for 循环
- 构建和扩展集合类型
- 逐行遍历文本文件
- 列表推导、字典推导和集合推导
- 元组拆包
- 调用函数时,使用 * 拆包实参
11.1. 序列可以迭代的原因:iter函数
解释器需要迭代对象 x 时,会自动调用 iter(x)。内置的iter函数有以下作用:
(1) 检查对象是否实现了 __iter__ 方法,如果实现了就调用它,获取一个迭代器。
(2) 如果没有实现 __iter__ 方法,但是实现了 __getitem__ 方法,Python 会创建一个迭代 器,尝试按顺序(从索引 0 开始)获取元素。
(3) 如果尝试失败,Python 抛出 TypeError 异常,通常会提示“C object is not iterable”( C 对象不可迭代),其中 C 是目标对象所属的类
两种类型:
鸭子类型(duck typing)的极端形式:不仅要实现特殊的
__iter__方 法,还要实现__getitem__方法,而且__getitem__方法的参数是从 0 开始的整数(int), 这样才认为对象是可迭代的。白鹅类型(goose-typing)理论中,可迭代对象的定义简单一些,不过没那么灵活:如果 实现了
__iter__方法,那么就认为对象是可迭代的。此时,不需要创建子类,也不用注册, 因为 abc.Iterable 类实现了__subclasshook__方法
12. 上下文管理器
在Python中,上下文管理器(Context Managers)用于管理资源的获取和释放,确保资源在使用完毕后被正确地释放,以避免资源泄漏。上下文管理器通常与with语句一起使用,with语句能够自动管理资源的获取和释放,使代码更加简洁和可读。
12.1. 使用类和__enter__()、__exit__()方法
创建一个类,并在其中实现__enter__()和__exit__()方法,__enter__()方法用于获取资源,__exit__()方法用于释放资源。
class MyContextManager:
def __enter__(self):
print("Entering the context")
# 获取资源
return self
def __exit__(self, exc_type, exc_value, traceback):
"""
:param exc_type: 异常类(例如 ZeroDivisionError)。
:param exc_val: 异常实例。有时会有参数传给异常构造方法,例如错误消息,这些参数可以使用 exc_value.args 获取。
:param exc_tb: traceback 对象。
:return:
"""
print("Exiting the context")
# 释放资源
with MyContextManager() as obj:
# 在此处执行需要使用资源的代码块
print("Inside the context")
12.2. 使用contextlib模块中的装饰器
contextlib模块提供了contextmanager装饰器,可以用于将生成器函数转换为上下文管理器。通过yield语句将资源提供给with语句块,在yield语句之前的代码作为__enter__()方法,yield语句之后的代码作为__exit__()方法。
from contextlib import contextmanager
@contextmanager
def my_context_manager():
print("Entering the context")
# 获取资源
yield
print("Exiting the context")
# 释放资源
with my_context_manager():
# 在此处执行需要使用资源的代码块
print("Inside the context")

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









