



实验目的
理解和掌握决策树原理,包括划分选择中三种经典指标信息增益、增益率和基尼指数的优缺点,剪枝处理方法及作用、连续值与缺失值处理等。
实验要求
基于给定数据集,采用决策树模型对问题进行分类。通过准确率指标值度量模型性能,对比不同划分选择标准的性能表现。
实验环境
python
numpy
matplotlib
sklearn
实验代码
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import sklearn
matplotlib.use('TkAgg')
# 读入训练数据
train_dataset = np.genfromtxt("experiment_04_training_set.csv", delimiter=',', skip_footer=1)
# 得到数据列数
columns = train_dataset.shape[1]
# 得到训练x
xOfTrainDataset = train_dataset[:, 0:columns-1]
# 得到训练y
yOfTrainDataset = train_dataset[:, columns-1:columns]
# 读入测试数据
test_dataset = np.genfromtxt("experiment_04_testing_set.csv", delimiter=',', skip_footer=1)
# 得到测试数据条数
numberOfTestDataset = test_dataset.shape[0]
# 得到测试x
xOfTestDataset = test_dataset[:, 0:columns-1]
# 得到测试y
yOfTestDataset = test_dataset[:, columns-1:columns]
# 划分指标
criterion = ["gini", "entropy"]
for i in range(2):
# 不同的层数
for j in range(3):
# 创建决策树
clf = sklearn.tree.DecisionTreeClassifier(max_depth=j+1, random_state=1, criterion=criterion[i])
# 训练
clf.fit(xOfTrainDataset, yOfTrainDataset)
# 进行预测
yPred = clf.predict(xOfTestDataset)
# 初始化正确个数
A = 0
# 统计正确个数
for k in range(numberOfTestDataset):
if np.isclose(yPred[k], yOfTestDataset[k]):
A += 1
# 计算精度
A = A / numberOfTestDataset
# 打印结果
print(f"准则: {criterion[i]} 层数: {j+1} Accuracy: {A: .4f}")
# 画图
sklearn.tree.plot_tree(clf, filled=True, rounded=True)
plt.show()
结果分析
使用sklearn中tree.DecisionTreeClassifier构建决策树,设置random_state=1(消除随机性,多次实验结果相同),划分标准依次选择criterion = ‘gini’和criterion = ‘entropy’,决策树最大层数依次设置max_depth = 1,max_depth = 2,max_depth = 3,填写如下实验结果。
测试集上精度(accuracy)为
|
准则\层数 |
1 |
2 |
3 |
|
基尼系数(gini) |
0.6552 |
0.8966 |
0.9483 |
|
信息熵entropy) |
0.5862 |
0.9483 |
0.9655 |
得到的六个决策树依次为(tree.plot_tree()描绘决策树):
图1 准则基尼系数,最大层数1
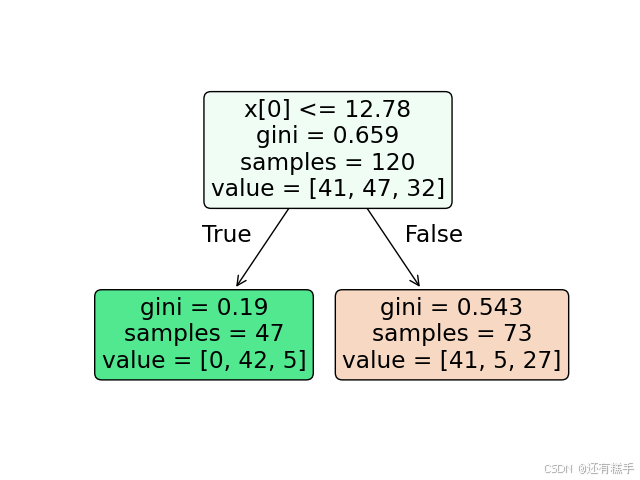
图2 准则基尼系数,最大层数2
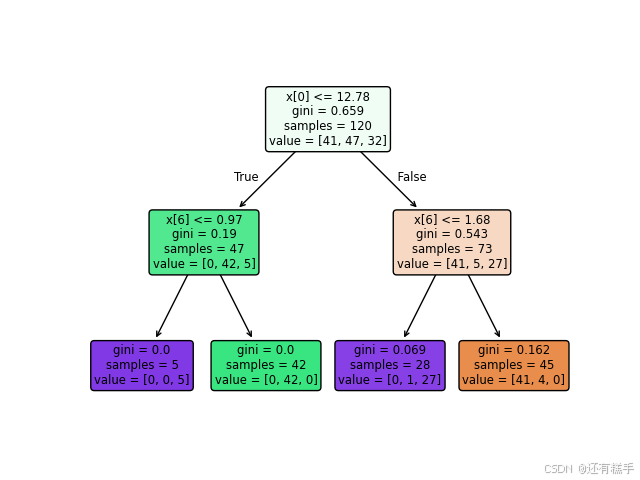
图3 准则基尼系数,最大层数3
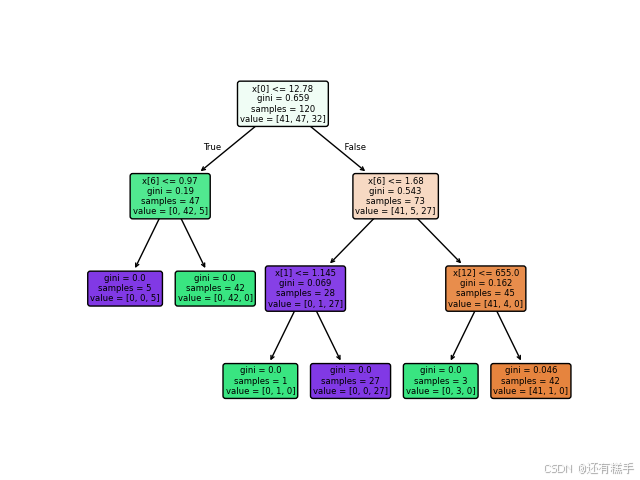
图4 准则信息熵,最大层数1
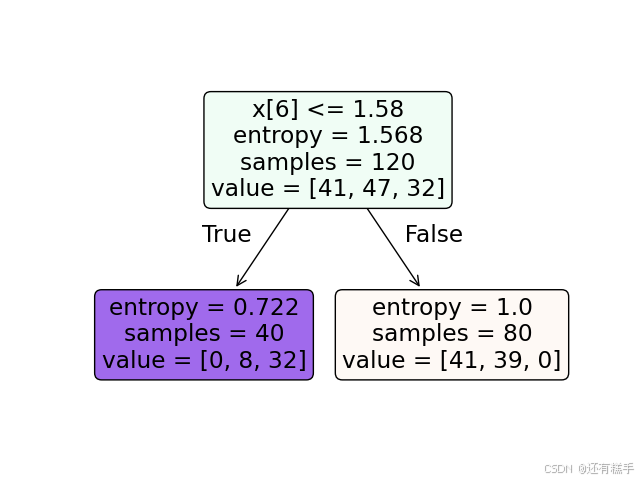
图5 准则信息熵,最大层数2
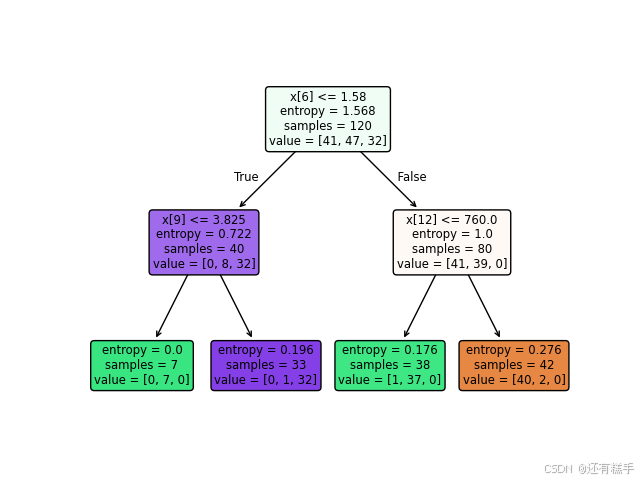
图6 准则信息熵,最大层数3
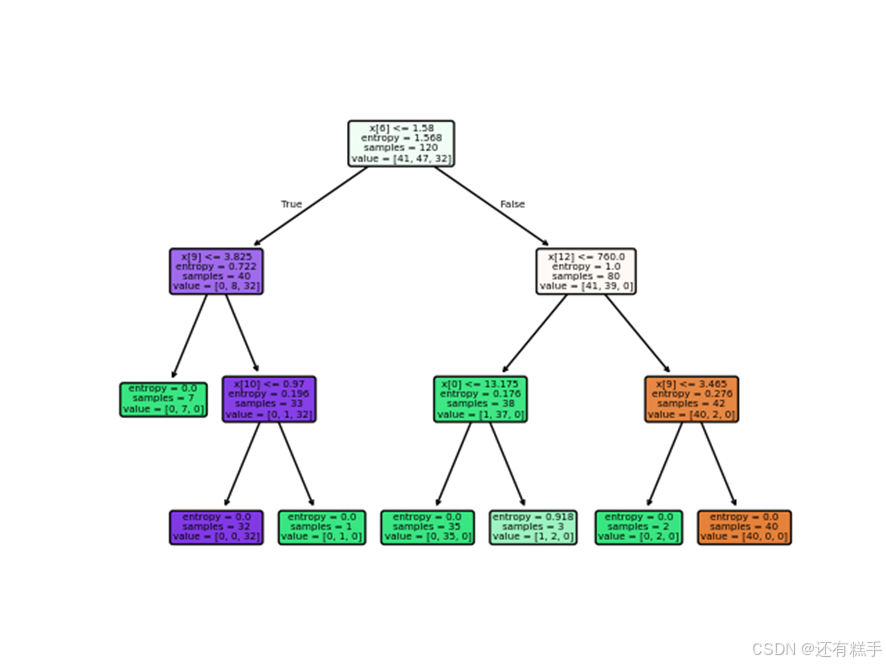


















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











