






 本文探讨了深度学习中梯度消失与梯度爆炸的问题,并介绍了如何通过明智地初始化权重来缓解这些问题。文章详细解释了不同激活函数下的权重初始化策略,如Xavier初始化和He初始化,以确保神经网络训练过程的稳定性和效率。
本文探讨了深度学习中梯度消失与梯度爆炸的问题,并介绍了如何通过明智地初始化权重来缓解这些问题。文章详细解释了不同激活函数下的权重初始化策略,如Xavier初始化和He初始化,以确保神经网络训练过程的稳定性和效率。
深度学习入门笔记手稿(七)梯度消失与梯度爆炸和神经网络权重初始化
梯度消失与梯度爆炸
训练神经网络会面临导数或梯度变得非常大,或者非常小,这加大了训练难度,而明智的选择随机初始化权重可避免这一问题。
下图是梯度消失和梯度爆炸产生的原因:
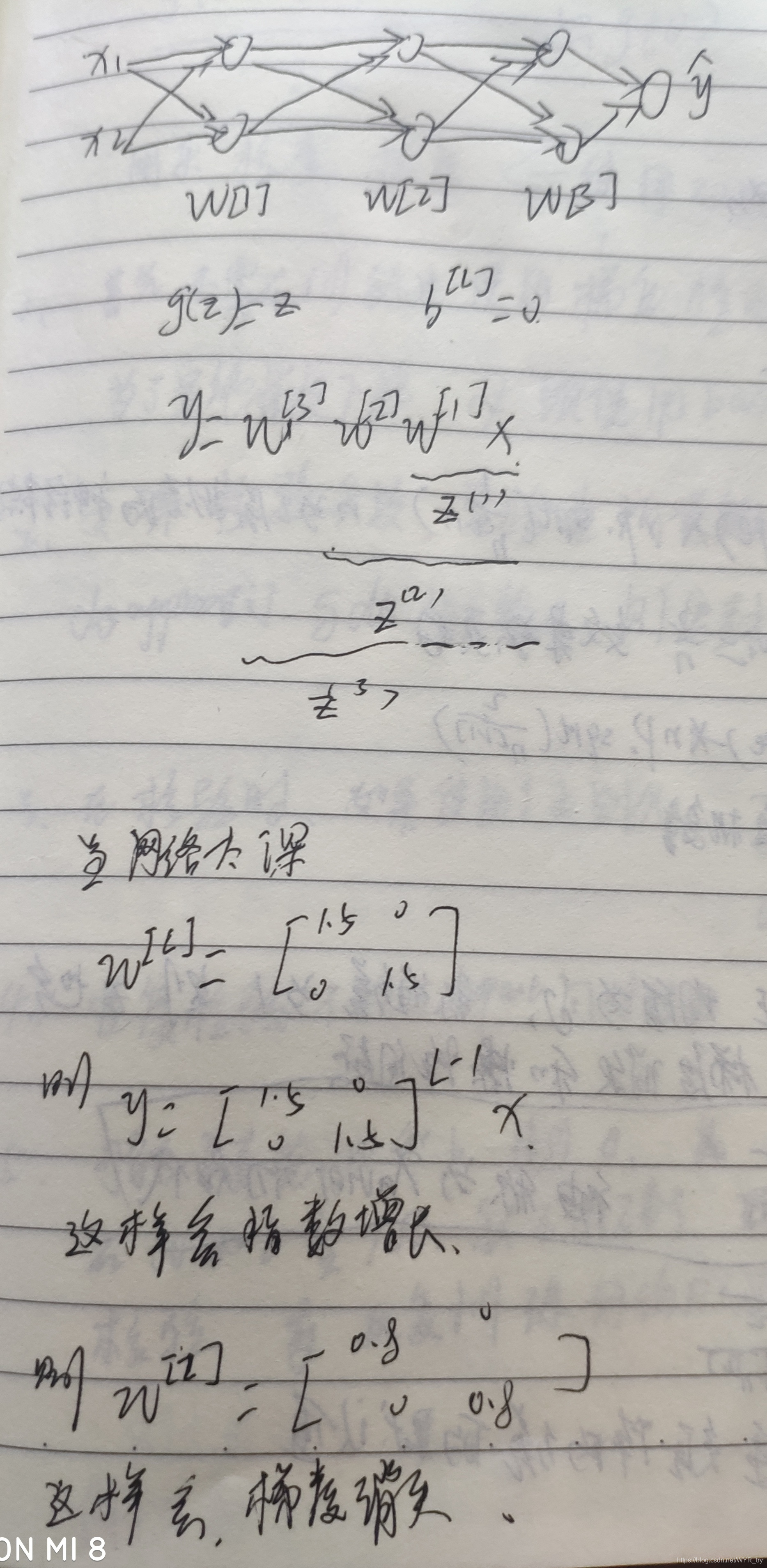
神经网络的权重初始化
针对梯度消失和梯度爆炸的问题
z=w1x1+w2x2+…xnwn
为了预防z值过大或过小,则n越大则希望wi越小 则设置wi=1/n
w[l]=np.random,randn(shape)*np.sqrt(1/n的(l-1次方)) #n为L层拟合的神经节点数
若用的是Relu 则设置wi=2/n 效果更好
w[l]=np.random,randn(shape)*np.sqrt(2/n的(l-1次方))
若激活函数的输入特征均值为0,标准方差为1,则z也会调整到相似的范围,则可以降低梯度消失和梯度爆炸问题。
对tanh来说 是用sqrt(1/n的(l-1次方))被称为xavier初始化
也可以用sqrt(2/(n的(l-1次方)+n的(l次方)))
它们给出初始化权重矩阵的方差的默认值。
具体如下图:


















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









