



从0开始学习自然语言处理:用字符级循环神经网络生成名字
学习目标
在本课程中你将学习如何使用字符级循环神经网络(RNN)生成不同语言的名字,并理解语言模型的基本概念和实现方法。
相关知识点
- RNN在文本生成中的应用
学习内容
1 RNN在文本生成中的应用
1.1 字符级RNN的工作原理
语言模型是一种能够计算或评估一段文本的概率分布的模型。它常用于各种自然语言处理任务,如文本生成、机器翻译和语音识别。
在本课程中,我们使用字符级RNN作为语言模型,逐个字符地生成名字。这种方法也可以扩展到单词或其他更高层次的语言结构。
%matplotlib inline
1.2 导入数据和依赖
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/f20d4082e81811ef894cfa163edcddae/data.zip
!unzip data.zip
from __future__ import unicode_literals, print_function, division
from io import open
import glob
import os
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS marker
def findFiles(path): return glob.glob(path)
# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
# Read a file and split into lines
def readLines(filename):
with open(filename, encoding='utf-8') as some_file:
return [unicodeToAscii(line.strip()) for line in some_file]
# Build the category_lines dictionary, a list of lines per category
category_lines = {}
all_categories = []
for filename in findFiles('data/names/*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
if n_categories == 0:
raise RuntimeError('Data not found. Make sure that you downloaded data '
'from https://download.pytorch.org/tutorial/data.zip and extract it to '
'the current directory.')
print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))
1.3 创建网络
import torch
import torch_npu
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, category, input, hidden):
input_combined = torch.cat((category, input, hidden), 1)
hidden = self.i2h(input_combined)
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
1.4 训练
import random
# Random item from a list
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
# Get a random category and random line from that category
def randomTrainingPair():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
return category, line
对于每个时间步(即训练词中的每个字母),网络的输入将是(类别, 当前字母, 隐藏状态),而输出将是(下一个字母, 下一个隐藏状态)。因此,对于每个训练集,我们需要类别、一组输入字母和一组输出/目标字母。
由于我们在每个时间步预测当前字母的下一个字母,因此字母对是从行中连续的字母组创建的——例如,对于 "ABCD<EOS>",我们将创建(“A”, “B”), (“B”, “C”),
(“C”, “D”), (“D”, “EOS”)这样的字母对。
# One-hot vector for category
def categoryTensor(category):
li = all_categories.index(category)
tensor = torch.zeros(1, n_categories)
tensor[0][li] = 1
return tensor
# One-hot matrix of first to last letters (not including EOS) for input
def inputTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li in range(len(line)):
letter = line[li]
tensor[li][0][all_letters.find(letter)] = 1
return tensor
# LongTensor of second letter to end (EOS) for target
def targetTensor(line):
letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))]
letter_indexes.append(n_letters - 1) # EOS
return torch.LongTensor(letter_indexes)
为了在训练过程中方便地获取随机的(类别,行)对并将其转换为所需的(类别,输入,目标)张量,我们可以创建一个 randomTrainingExample 函数。这个函数将从数据集中随机选择一个样本,并生成相应的张量。
# Make category, input, and target tensors from a random category, line pair
def randomTrainingExample():
category, line = randomTrainingPair()
category_tensor = categoryTensor(category)
input_line_tensor = inputTensor(line)
target_line_tensor = targetTensor(line)
return category_tensor, input_line_tensor, target_line_tensor
与分类任务不同,在分类任务中仅使用最后一个输出进行预测,而在生成任务中我们在每个时间步都进行预测,因此我们需要在每个时间步计算损失。
得益于自动求导(autograd)的魔力,你可以简单地将每一步的损失相加,并在最后调用 backward() 来反向传播梯度。
criterion = nn.NLLLoss()
learning_rate = 0.0005
def train(category_tensor, input_line_tensor, target_line_tensor):
target_line_tensor.unsqueeze_(-1)
hidden = rnn.initHidden()
hidden = hidden.to(device)
rnn.zero_grad()
loss = 0
for i in range(input_line_tensor.size(0)):
output, hidden = rnn(category_tensor.to(device), input_line_tensor[i].to(device), hidden)
l = criterion(output, target_line_tensor[i].to(device))
loss += l
loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item() / input_line_tensor.size(0)
为了跟踪训练所需的时间,我们可以添加一个 timeSince(timestamp)函数,该函数返回一个人类可读的时间字符串。这个函数将计算从给定时间戳到现在经过的时间,并将其格式化为分钟和秒数。
import time
import math
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
训练过程与常规操作相同——多次调用 train 函数并等待几分钟,每 print_every个样本打印当前的时间和损失,并在 all_losses 中存储每 plot_every个样本的平均损失,以便后续绘图。
from tqdm import tqdm
device = "npu"
rnn = RNN(n_letters, 128, n_letters)
rnn.to(device)
# 本课程中为了快速跑通,设置的训练轮次偏小
# 如果想要训练得到更好的结果,可以自行调整
n_iters = 30000
print_every = 5000
plot_every = 500
all_losses = []
total_loss = 0 # Reset every plot_every iters
start = time.time()
for iter in tqdm(range(1, n_iters + 1), desc='Training', unit='iter'):
output, loss = train(*randomTrainingExample())
total_loss += loss
if iter % print_every == 0:
print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss))
if iter % plot_every == 0:
all_losses.append(total_loss / plot_every)
total_loss = 0

1.5 绘制损失曲线
绘制 all_losses 中的历史损失可以展示网络的学习过程。通过观察损失随时间的变化,我们可以评估模型的训练效果,并判断是否需要调整超参数或改进模型结构。
import matplotlib.pyplot as plt
plt.figure()
plt.plot(all_losses)
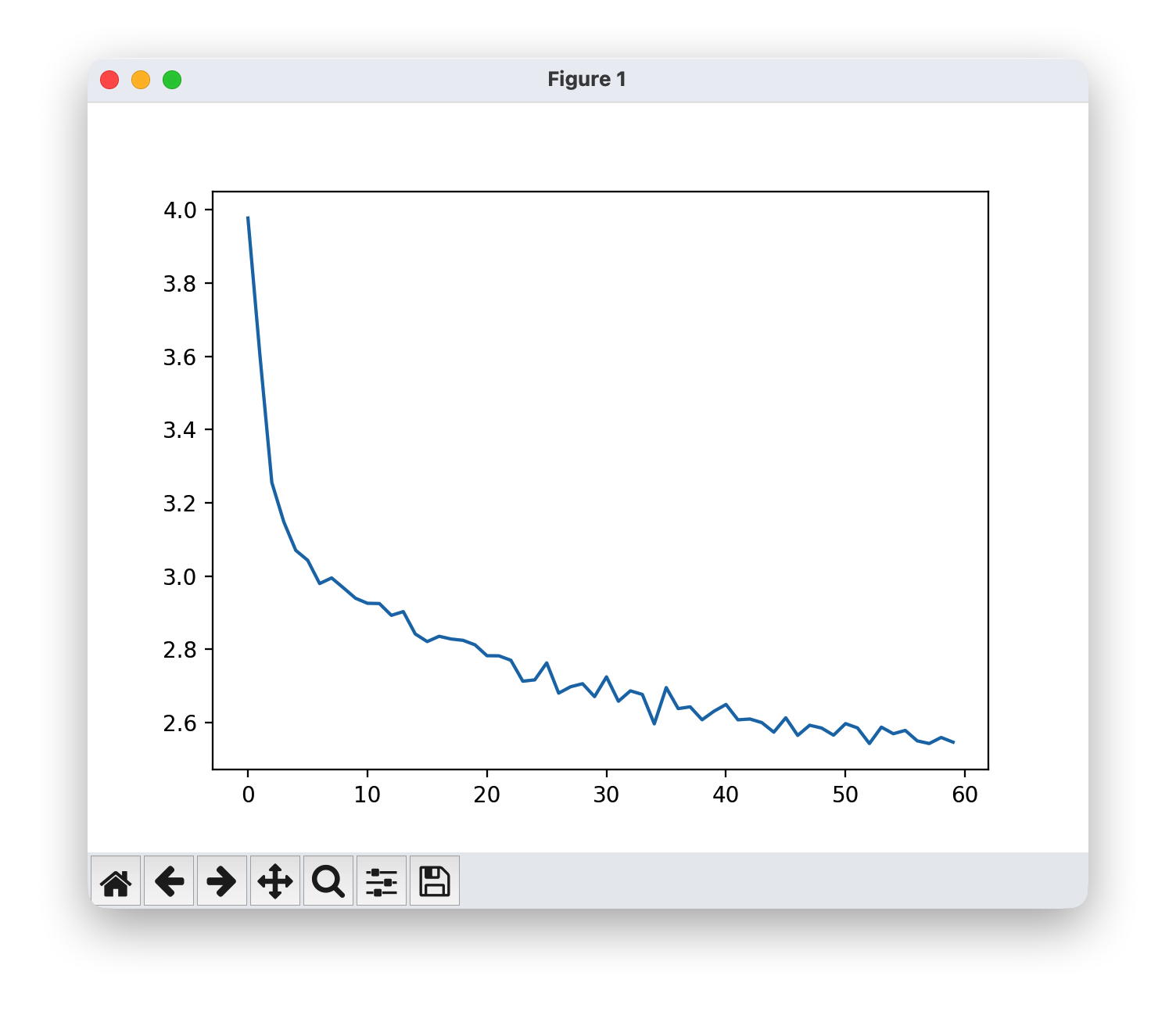
为了进行采样,我们给网络一个字母并询问下一个字母是什么,然后将这个字母作为下一个输入,重复这个过程直到遇到 EOS(End of Sequence)标记。
以下是具体的步骤:
- 创建张量:
- 创建表示输入类别的张量、起始字母的张量和空的隐藏状态张量。
- 初始化输出字符串:
- 创建一个包含起始字母的字符串 output_name。
- 循环生成字母:
- 在达到最大输出长度之前,
- 将当前字母输入到网络中。
- 获取下一个字母(即输出中概率最高的字母)和下一个隐藏状态。
- 如果该字母是 EOS 标记,则停止生成。
- 如果是常规字母,则将其添加到 output_name 中,并继续生成下一个字母。
- 返回最终生成的名字。
注意:
另一种策略是不提供起始字母,而是在训练时包括一个“字符串开始”标记,让网络自行选择起始字母。
max_length = 20
# Sample from a category and starting letter
def sample(category, start_letter='A'):
with torch.no_grad(): # no need to track history in sampling
category_tensor = categoryTensor(category)
input = inputTensor(start_letter)
hidden = rnn.initHidden().to(device)
output_name = start_letter
for i in range(max_length):
output, hidden = rnn(category_tensor.to(device), input[0].to(device), hidden)
topv, topi = output.topk(1)
topi = topi[0][0]
if topi == n_letters - 1:
break
else:
letter = all_letters[topi]
output_name += letter
input = inputTensor(letter)
return output_name
# Get multiple samples from one category and multiple starting letters
def samples(category, start_letters='ABC'):
for start_letter in start_letters:
print(sample(category, start_letter))
samples('Russian', 'RUS')
samples('German', 'GER')
samples('Spanish', 'SPA')
samples('Chinese', 'CHI')




















 9168
9168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









