 PyTorch神经网络基础:层与神经元
PyTorch神经网络基础:层与神经元




1.2.1 生物神经元
生物神经元是生物体神经系统的基本单位。它们通过一系列步骤工作:
-
信号接收:“树突”,神经元的分支延伸,接收来自其他神经元或感觉感受器的信号。
-
信号整合:接收到的信号在神经元的
细胞体中进行整合。这个积分过程涉及输入信号的求和。 -
信号传导:如果积分信号超过一定阈值,就会产生称为动作电位的电脉冲。这种动作电位沿着“轴突”(一种长纤维样结构)向“突触”行进。
-
信号传播:在“突触”处,电脉冲被转换成化学信号。神经递质被释放到突触中,使信号被传递到下一个神经元的树突。
-
信号处理:该过程在随后的“神经元”中重复,使信号在整个神经系统中传播。
1.2.2 人工神经元
人工神经元,也称为节点或感知器,是一种旨在模仿生物神经元行为的数学模型。它们以不同的方式运行:
-
信号接收:人工
神经元接收来自前一层或外部源的输入信号,通常表示为数值。 -
信号加权:每个输入信号都乘以相应的
weight。这些权重决定了每个输入对整体计算的重要性或贡献。 -
信号求和:加权后的输入信号求和,通常使用线性组合。
-
激活函数:求和的信号通过
激活函数传递,该函数将非线性引入计算中。激活函数根据输入信号确定人工神经元的输出。 -
信号传输:然后将人工神经元的输出传输到下一层或作为神经网络的最终输出。
-
反向传播:神经网络中的
神经通过调整与其连接相关的权重和偏差来学习。这个过程被称为“反向传播”,允许网络优化其性能并做出准确的预测。
1.3 神经元的基本组成
人工神经网络中的神经元与它们的生物学对应的神经元相似,并具有三个主要组成部分:
-
输入:神经元接收来自前一层或外部源的输入信号。这些输入乘以相应的权重,然后求和。
-
激活函数:通过激活函数传递输入的加权和,激活函数将非线性引入网络。激活函数根据输入信号确定神经元的输出。
-
输出:神经元的输出是应用于输入的加权和的激活函数的结果。然后,这个输出被传输到下一层神经元。
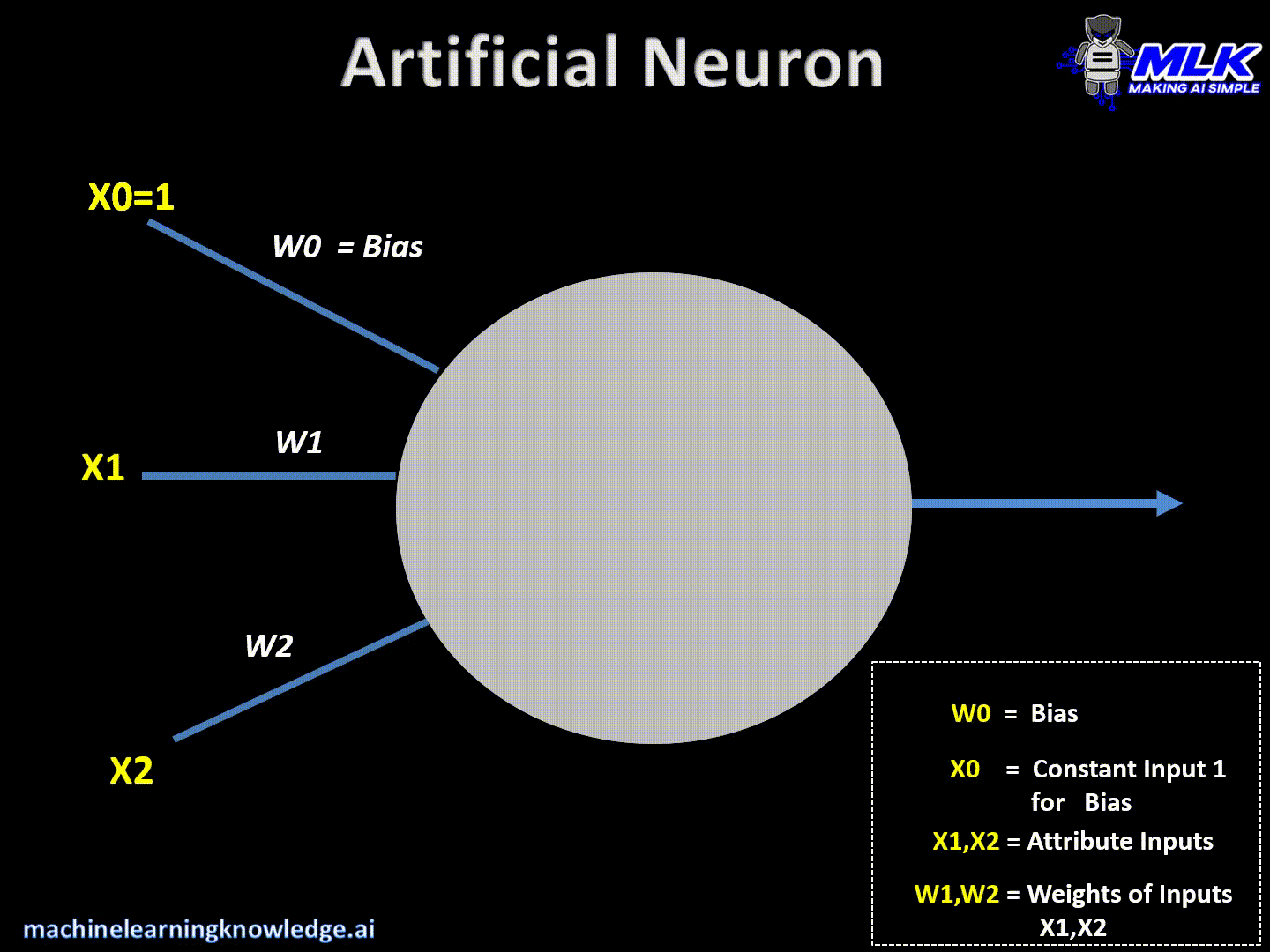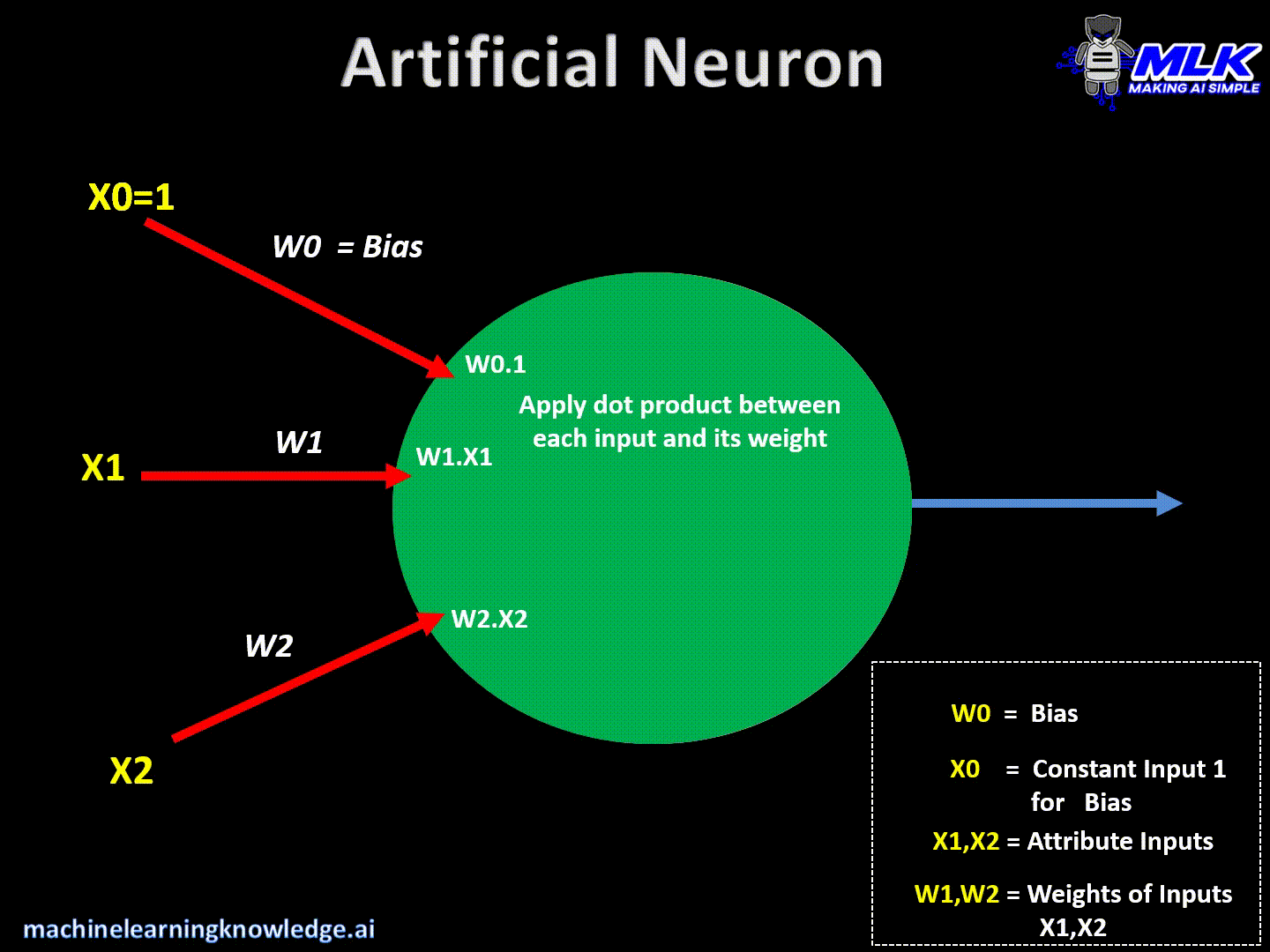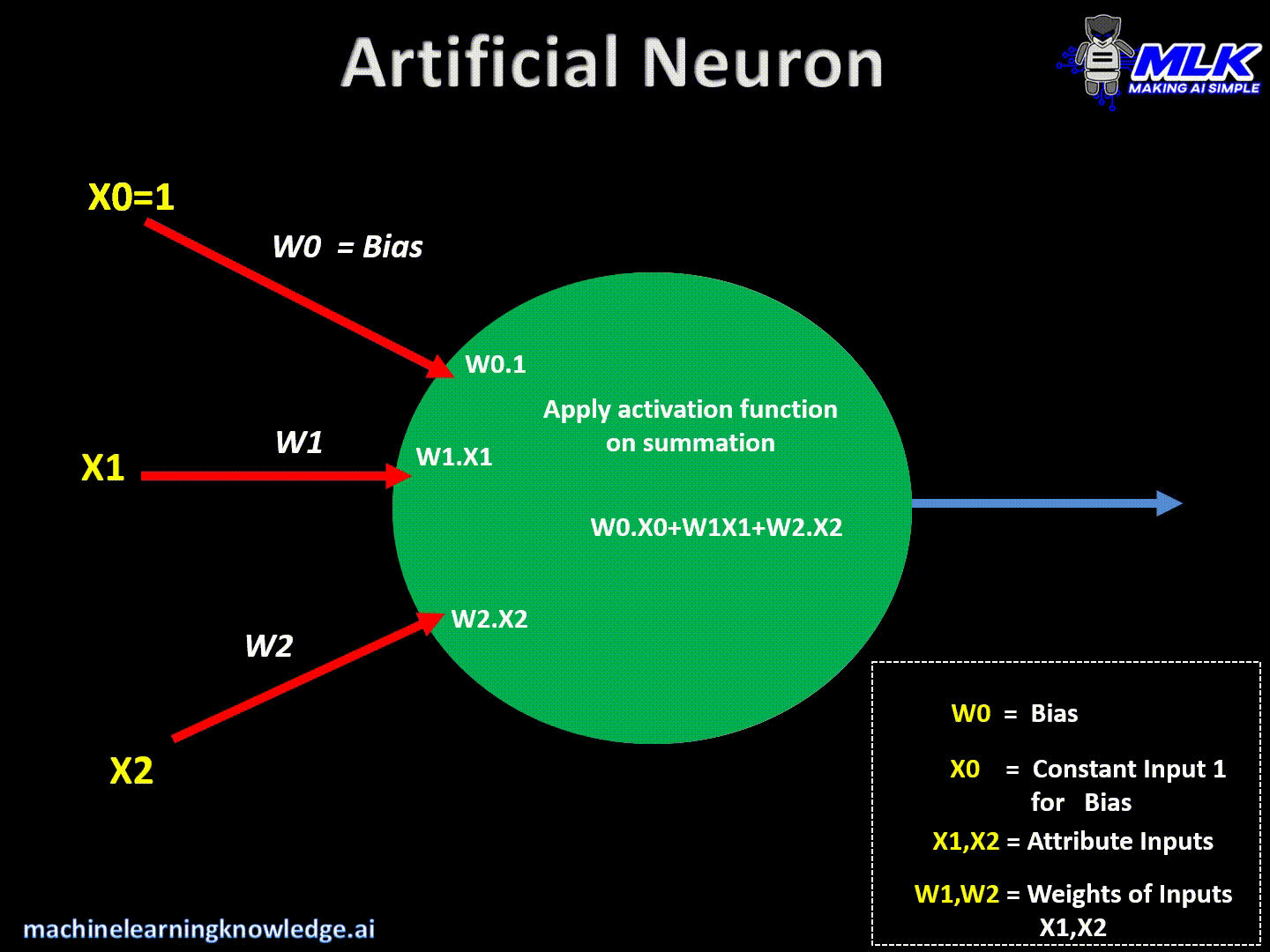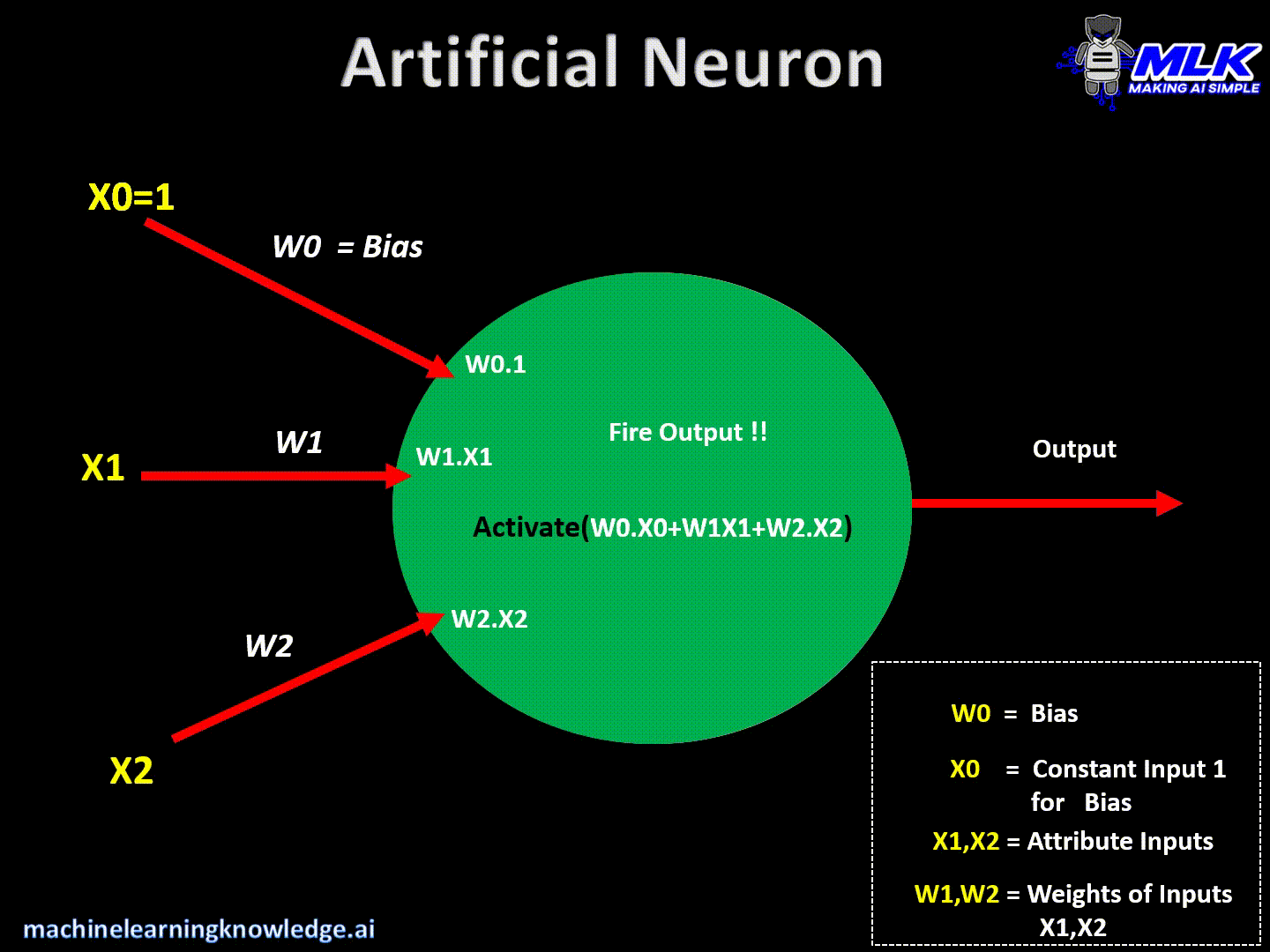
图3:实验设备
1.3.1 神经元权重和偏置
在人工神经网络(ANN)中,每个神经元接收来自前一层或外部源的输入信号。将这些输入信号乘以相应的权重,然后求和。此外,在通过激活函数之前,将偏置项添加到加权和中。
神经元的数学公式可以表示为:
z=∑i=1n(wi⋅xi)+b z = \sum_{i=1}^{n} (w_i \cdot x_i) + b z=i=1∑n(wi⋅xi)+b
out=activation_function(z) out = \text{activation\_function}(z) out=activation_function(z)
- zzz是输入加上偏置项的加权和,
- wiw_iwi表示分配给每个输入xix_ixi的权重,
- bbb是偏倚项,
- outoutout是神经元经过激活函数后的输出。
它们是什么
-
权重:分配给每个输入xix_ixi信号的权重wiw_iwi决定了该输入对神经元整体计算的重要性或贡献。权重越大,表示相应的输入对神经元输出的影响越强。通过在训练期间调整权重,网络学会将“更高的权重分配给更重要的特征,将更低的权重分配给不重要的特征”。
-
偏置:偏置项bbb允许神经元独立于输入信号调整其输出。它作为偏移量或“阈值”,决定神经元的激活水平。
正偏置会将激活函数右移,而负偏置会将其左移.通过调整偏置,网络可以控制神经元的整体输出。
理解并适当地设置神经元的权重和偏置对于人工神经网络的性能和有效性至关重要。在训练过程中不正确的初始化或不正确的调整会导致次优结果,甚至出现收敛问题。
如何计算它们
计算神经元权重和偏置的过程包括两个主要步骤:
-
初始化:初始时,神经元的权重wiw_iwi和偏置bbb被
随机分配或用较小的值初始化。这种随机初始化有助于打破对称性,并允许网络学习不同的特征。 -
训练:在训练过程中,网络调整权重wiw_iwi和偏置bbb,以
最小化预测输出和实际输出之间的差异。这种调整是使用优化算法完成的,例如梯度下降,它根据预测和实际输出之间的误差迭代更新权重wiw_iwi和偏置bbb。
1.3.2 激活函数
神经元的激活函数根据输入的加权和确定其输出。它将非线性引入神经网络,使其能够学习复杂的模式并做出预测。
常用的激活函数包括:
| Step | Sigmoid | Tanh |
 |  |  |
| ReLU | LReLU | Softmax |
 |  |  |
import numpy as np
步进激活函数
基于阈值输出二进制值的简单激活函数。如果输入小于阈值,则返回0,否则返回1。阶跃函数经常用于二元分类问题。
数学函数可以表示为:
step(x)={1,if x≥00,otherwise \text{step}(x) = \begin{cases} 1, & \text{{if }} x \geq 0 \\ 0, & \text{{otherwise}} \end{cases} step(x)={1,0,if x≥0otherwise
def step(x):
return np.where(x >= 0, 1, 0)
Sigmoid激活函数
常用于二分类问题的输出层。它将输出压缩在0和1之间,表示正类的概率。如果在隐藏层中使用,可能会导致消失梯度问题。
sigmoid数学函数可以表示为:
sigmoid(x)=11+e−x \text{sigmoid}(x) = \frac{1}{{1 + e^{-x}}} sigmoid(x)=1+e−x1
def sigmoid(x):
return 1 / (1 + np.exp(-x))
Tanh(双曲切线)激活函数
压缩-1和1之间的输入值。它围绕原点对称,对于捕获数据中的非线性关系非常有用。如果在隐藏层中使用,可能会导致消失梯度问题。
双曲正切(tanh)函数的数学表示是:
tanh(x)=ex−e−xex+e−x \text{tanh}(x) = \frac{{e^x - e^{-x}}}{{e^x + e^{-x}}} tanh(x)=ex+e−xex−e−x
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
ReLU(整流线性单元)激活函数
将所有负值设置为零,并保持正值不变。会患上垂死的神经元问题“垂死的ReLU”。
ReLU(整流线性单元)激活函数的数学表示是:
ReLU(x)=max(0,x) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
def relu(x):
return np.maximum(0, x)
LReLU(泄漏ReLU)激活函数
ReLU激活函数的变体,允许小的负值,而不是将其设置为零。这有助于缓解“死亡ReLU”问题,即神经元可能变得不活跃并停止学习。
Leaky ReLU (LReLU)的数学表示是:
LReLU(x)={x,if x≥0αx,otherwise \text{LReLU}(x) = \begin{cases} x, & \text{if } x \geq 0 \\ \alpha x, & \text{otherwise} \end{cases} LReLU(x)={x,αx,if x≥0otherwise
其中α\alphaα是一个小的正常数,用于确定负值xxx时函数的斜率。
def lrelu(x, alpha=0.01):
return np.where(x >= 0, x, alpha * x)
Softmax激活函数
常用于多类分类问题的输出层。它将输出归一化为类上的概率分布。
softmax激活函数的数学表示为:
softmax(xi)=exi∑j=1nexj \text{softmax}(x_i) = \frac{{e^{x_i}}}{{\sum_{j=1}^{n} e^{x_j}}} softmax(xi)=∑j=1nexjexi
其中xix_ixi表示iii元素的输入值,nnn是输入向量中元素的总数。
def softmax(x):
exps = np.exp(x - np.max(x, axis=1, keepdims=True))
return exps / np.sum(exps, axis=1, keepdims=True)
附录:softMax激活函数计算过程详解
Softmax激活函数常用于多分类问题的输出层,它能将一组任意实数(通常是模型的原始输出,称为“logits”)转换为范围在[0, 1]且总和为1的概率分布,直观表示每个类别的预测概率。
Softmax计算公式
对于输入向量x = [x₁, x₂, ..., xₙ],Softmax的计算如下:
Softmax(xi)=exi∑j=1nexj
\text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{n} e^{x_j}}
Softmax(xi)=∑j=1nexjexi
其中:
- 分子是输入元素
x_i的指数函数(e为自然常数,约2.718); - 分母是所有输入元素的指数函数之和,确保输出总和为1。
具体例子:三分类问题
假设模型对一个样本的原始输出(logits)为:
logits = [2.0, 1.0, 0.1]
我们用Softmax将其转换为概率分布,步骤如下:
步骤1:计算每个元素的指数(分子)
e2.0≈7.389e1.0≈2.718e0.1≈1.105 \begin{align*} e^{2.0} &\approx 7.389 \\ e^{1.0} &\approx 2.718 \\ e^{0.1} &\approx 1.105 \\ \end{align*} e2.0e1.0e0.1≈7.389≈2.718≈1.105
步骤2:计算指数之和(分母)
∑exj=7.389+2.718+1.105≈11.212 \sum e^{x_j} = 7.389 + 2.718 + 1.105 \approx 11.212 ∑exj=7.389+2.718+1.105≈11.212
步骤3:每个元素的指数除以总和,得到概率
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …\ \end{align*}
结果验证
概率总和:0.659 + 0.242 + 0.099 = 1.0,符合Softmax的特性。
在这个例子中,模型预测该样本属于第一个类别的概率最高(65.9%)。
PyTorch代码验证
用PyTorch的torch.softmax函数可以快速实现上述计算:
import torch
logits = torch.tensor([2.0, 1.0, 0.1])
probabilities = torch.softmax(logits, dim=0) # dim=0表示对第0维(向量本身)计算
print(probabilities) # 输出:tensor([0.6590, 0.2424, 0.0986])
print(probabilities.sum()) # 输出:tensor(1.0000)(总和为1)
核心特点
- 概率化:输出值均为
[0, 1],且总和为1,可直接作为分类概率; - 放大差异:输入中数值较大的元素,对应的输出概率会被“放大”(如例子中
2.0的概率远高于其他值); - 多分类适配:适用于互斥的多分类场景(如识别图片是猫、狗还是鸟)。
通过Softmax,模型的原始输出被赋予了明确的概率意义,便于后续决策(如选择概率最高的类别作为预测结果)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









