



Neo4j 是一款基于 图数据库(Graph Database) 模型的开源数据库管理系统,由瑞典公司 Neo4j, Inc. 开发。它以“节点”和“关系”为核心存储单元,擅长处理复杂的关联数据,尤其在社交网络、知识图谱、推荐系统、供应链分析等场景中表现出色。
核心概念与特点
-
图数据模型
- 节点(Nodes):表示实体(如用户、产品、地点等),包含属性(键值对)。
- 关系(Relationships):表示节点之间的连接(如“关注”“购买”“属于”等),有方向、类型和属性。
- 标签(Labels):用于分组节点(如“用户”“商品”)。
- 属性(Properties):为节点和关系添加描述性数据(如用户姓名、关系强度)。
-
原生图存储
- 直接使用图结构存储数据,而非将图数据映射到传统关系型数据库的表结构,避免了“连接查询”的性能损耗。
- 关系查询速度与数据规模无关(仅取决于路径长度),适合处理高关联度数据。
-
Cypher 查询语言
- 类似 SQL 的声明式查询语言,简洁易读,支持模式匹配、路径查找等操作。
- 示例:查询“用户A关注的所有用户”
MATCH (user:User {name: "A"})-[:FOLLOWS]->(followed:User) RETURN followed.name;
-
高扩展性
- 支持集群部署(企业版),通过复制和分片提升吞吐量和可用性。
- 提供 ACID 事务特性,确保数据一致性。
-
生态与工具
- 支持多种编程语言驱动(Java、Python、JavaScript 等)。
- 提供桌面版管理工具 Neo4j Browser,支持可视化查询和图结构展示。
- 集成 ETL 工具(如 Apache NiFi)和数据分析框架(如 Spark)。
适用场景
- 知识图谱:构建实体关系网络(如人物关系、药物相互作用)。
- 社交网络:分析用户连接、社群发现、病毒传播路径。
- 推荐系统:基于用户行为和物品关联生成个性化推荐。
- 欺诈检测:通过关联分析识别异常交易网络。
- 供应链与物流:优化路径规划、追踪节点依赖关系。
与传统数据库的对比
| 维度 | Neo4j(图数据库) | 关系型数据库(如MySQL) |
|---|---|---|
| 数据模型 | 节点 + 关系(图结构) | 表 + 行 + 列(二维结构) |
| 查询优势 | 高效处理复杂关联查询(如路径搜索) | 适合结构化事务性操作 |
| 数据规模影响 | 关系查询性能与数据量无关 | 多表连接性能随数据量下降显著 |
| 典型场景 | 社交网络、知识图谱 | 订单管理、交易系统 |
版本与社区支持
- 社区版(Community Edition):免费开源,适合小型项目和开发测试。
- 企业版(Enterprise Edition):提供集群管理、高可用性、安全审计等高级功能,支持商业场景。
- 云服务(Neo4j Cloud):基于 AWS、Azure 等平台的托管服务,简化部署和运维。
Neo4j 凭借其独特的图数据模型和高效的关联查询能力,已成为处理复杂关系数据的首选工具之一,尤其在需要实时分析动态网络结构的场景中表现突出。
安装教程:
以下是在不同操作系统上安装和配置 Neo4j 的详细步骤,包含社区版和 Docker 安装方式:
一、系统要求
- 操作系统:Windows、Linux(Ubuntu/Debian、CentOS/RHEL)、macOS
- Java:OpenJDK 11 或 17(Neo4j 4.4+ 支持)
- 内存:至少 2GB RAM(生产环境建议 8GB+)
- 磁盘空间:根据数据量调整,建议预留 10GB+
二、安装 Java
Neo4j 依赖 Java 运行环境,需先安装 OpenJDK:
Ubuntu/Debian:
sudo apt update
sudo apt install openjdk-11-jdk
java -version # 验证安装
CentOS/RHEL:
sudo yum install java-11-openjdk-devel
java -version
macOS(使用 Homebrew):
brew install openjdk@11
三、安装 Neo4j(社区版)
1. Ubuntu/Debian(使用 APT)
# 添加 Neo4j 仓库密钥
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -
# 添加仓库源
echo 'deb https://debian.neo4j.com stable 4.4' | sudo tee -a /etc/apt/sources.list.d/neo4j.list
# 安装 Neo4j
sudo apt update
sudo apt install neo4j=1:4.4.15
# 启动服务
sudo systemctl start neo4j
sudo systemctl enable neo4j # 设置开机自启
2. Windows(使用安装包)
- 从 Neo4j 官网 下载 Windows 安装包(
.exe) - 运行安装程序,按向导提示完成安装
- 启动 Neo4j Desktop,创建并启动数据库实例
3. macOS(使用 Homebrew)
brew install neo4j
neo4j start # 启动服务
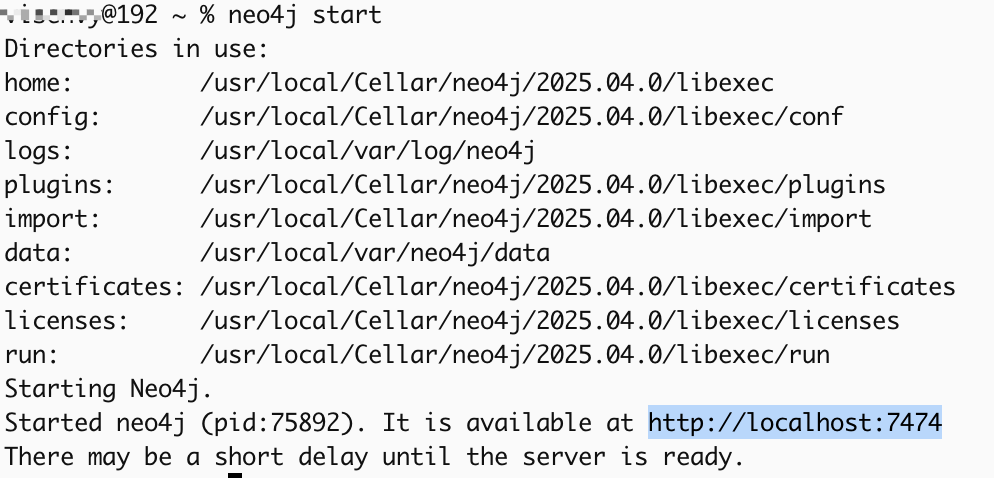
四、配置 Neo4j
编辑配置文件 conf/neo4j.conf(Linux/macOS)或通过 Neo4j Desktop 图形界面配置:
1. 启用远程访问(默认仅本地访问)
# 取消注释以下行
dbms.default_listen_address=0.0.0.0
2. 调整内存分配(根据服务器内存调整)
dbms.memory.heap.initial_size=1G
dbms.memory.heap.max_size=2G
3. 配置密码(首次启动后设置)
# 初始默认密码为 "neo4j"
# 启动后访问 http://localhost:7474,按提示修改密码
五、验证安装
-
启动 Neo4j 服务:
# Linux/macOS sudo systemctl start neo4j # 或使用 neo4j start # Windows(通过服务管理器或 Neo4j Desktop) -
访问浏览器:
- 打开 http://localhost:7474
- 使用默认用户名
neo4j和初始密码neo4j登录 - 按提示设置新密码
-
执行测试查询:
CREATE (n:Person {name:"Alice"})-[:KNOWS]->(m:Person {name:"Bob"}) RETURN n, m;
六、卸载 Neo4j
Ubuntu/Debian
sudo apt remove neo4j
sudo apt purge neo4j # 彻底删除配置文件
Windows
通过控制面板的“程序和功能”卸载。
macOS
brew uninstall neo4j
七、Docker 快速安装(推荐)
# 拉取官方镜像
docker pull neo4j:4.4-community
# 启动容器
docker run \
--name neo4j \
-p 7474:7474 -p 7687:7687 \
-d \
-v $HOME/neo4j/data:/data \
-v $HOME/neo4j/logs:/logs \
-v $HOME/neo4j/import:/var/lib/neo4j/import \
-v $HOME/neo4j/plugins:/plugins \
--env NEO4J_AUTH=neo4j/password \
neo4j:4.4-community
- 访问 http://localhost:7474,使用
neo4j/password登录
八、常见问题
- 端口冲突:检查是否有其他服务占用 7474(HTTP)或 7687(Bolt)端口。
- 内存不足:调整
neo4j.conf中的堆内存参数。 - 权限问题:确保数据目录有写入权限。
- 防火墙:开放 7474 和 7687 端口(生产环境建议限制访问)。
九、后续学习
- 官方文档:Neo4j 文档
- Cypher 教程:Cypher 查询语言
- 示例项目:Neo4j 示例
安装完成后,你可以开始构建自己的图数据库应用!如果遇到问题,建议查看 Neo4j 日志文件(位于 logs/ 目录)获取详细错误信息。
十、Cypher 查询语言基础
一、基础增删改查
1. 创建数据(CREATE)
// 创建单个节点(带标签和属性)
CREATE (:User {name: "Alice", age: 30})
// 创建两个节点并建立关系
CREATE (u:User {name: "Bob"})-[r:FRIENDS_WITH {since: 2020}]->(v:User {name: "Charlie"})
RETURN u, r, v;
// 批量创建节点(使用UNWIND)
UNWIND [{name: "Dave", age: 25}, {name: "Eve", age: 28}] AS data
CREATE (user:User) SET user = data;
2. 查询数据(MATCH)
// 查询所有用户节点
MATCH (u:User) RETURN u;
// 查询名为Alice的用户
MATCH (u:User {name: "Alice"}) RETURN u;
// 查询朋友关系(含关系属性)
MATCH (u:User)-[r:FRIENDS_WITH]->(v:User)
RETURN u.name, r.since, v.name;
// 查询特定路径(Bob的朋友的朋友)
MATCH (b:User {name: "Bob"})-[:FRIENDS_WITH*2]-(fof:User)
RETURN fof.name;
3. 更新数据(SET、REMOVE)
// 修改节点属性
MATCH (u:User {name: "Alice"})
SET u.age = 31, u.city = "New York"
RETURN u;
// 添加标签
MATCH (u:User {name: "Bob"})
SET u:Developer
RETURN u;
// 删除属性
MATCH (u:User {name: "Charlie"})
REMOVE u.age
RETURN u;
4. 删除数据(DELETE、DETACH DELETE)
// 删除无关系节点
MATCH (u:User {name: "Eve"})
DELETE u;
// 删除节点及其所有关系(危险操作!)
MATCH (u:User {name: "Dave"})
DETACH DELETE u;
// 删除所有节点和关系(清空数据库)
MATCH (n)
DETACH DELETE n;
5. 聚合统计
// 计算用户数量
MATCH (u:User)
RETURN count(u) AS total_users;
// 计算每个用户的朋友数量
MATCH (u:User)-[:FRIENDS_WITH]->(f:User)
RETURN u.name, count(f) AS friend_count
ORDER BY friend_count DESC;
6. 路径查询
// 查找两个用户之间的最短路径
MATCH p=shortestPath((a:User {name: "Alice"})-[:FRIENDS_WITH*]-(b:User {name: "Charlie"}))
RETURN p;
7. 条件过滤(WHERE)
// 查询年龄大于25的用户
MATCH (u:User)
WHERE u.age > 25
RETURN u.name, u.age;
// 复杂条件(AND、OR、IN)
MATCH (u:User)
WHERE u.age > 25 AND u.name IN ["Alice", "Bob"]
RETURN u;
二、完整案例:社交网络分析
1. 数据导入
// 创建用户节点
CREATE (:User {id: 1, name: "Alice", city: "New York"})
CREATE (:User {id: 2, name: "Bob", city: "London"})
CREATE (:User {id: 3, name: "Charlie", city: "Paris"})
CREATE (:User {id: 4, name: "Dave", city: "New York"})
CREATE (:User {id: 5, name: "Eve", city: "London"});
// 创建朋友关系
MATCH (a:User {id: 1}), (b:User {id: 2})
CREATE (a)-[:FRIENDS_WITH {since: 2019}]->(b);
MATCH (a:User {id: 1}), (c:User {id: 3})
CREATE (a)-[:FRIENDS_WITH {since: 2020}]->(c);
MATCH (b:User {id: 2}), (d:User {id: 4})
CREATE (b)-[:FRIENDS_WITH {since: 2018}]->(d);
MATCH (c:User {id: 3}), (e:User {id: 5})
CREATE (c)-[:FRIENDS_WITH {since: 2021}]->(e);
2. 查询示例
// 查询纽约用户及其朋友
MATCH (u:User {city: "New York"})-[:FRIENDS_WITH]->(f:User)
RETURN u.name AS user, f.name AS friend, f.city AS friend_city;
// 查找有共同朋友的用户对
MATCH (u1:User)-[:FRIENDS_WITH]->(f:User)<-[:FRIENDS_WITH]-(u2:User)
WHERE u1.id < u2.id // 避免重复对
RETURN u1.name, u2.name, count(f) AS common_friends
ORDER BY common_friends DESC;
3. 删除示例
在Neo4j中删除关系有多种方式,下面为你介绍一些主要的删除方法。
使用下述方法时,请务必谨慎操作,因为在Neo4j中删除操作是不可回滚的。
3.1 删除单个关系
假设你要删除Person节点和Movie节点之间名为ACTED_IN的关系,可按如下方式操作:
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
WHERE p.name = 'Tom Hanks' AND m.title = 'Forrest Gump'
DELETE r
此查询会找出由演员Tom Hanks到电影Forrest Gump的ACTED_IN关系并将其删除。
3.2 删除特定类型的所有关系
若要删除图中所有FOLLOWS类型的关系,可使用下面的查询:
MATCH ()-[r:FOLLOWS]->()
DELETE r
执行这个查询后,所有FOLLOWS类型的关系都会被删除,但相关节点不会受到影响。
3.3 删除节点及与之关联的所有关系
当你要删除某个节点,同时删除该节点的所有入站和出站关系时,可以这样做:
MATCH (p:Person {name: 'Alice'})-[r]-()
DELETE p, r
该查询会删除名为Alice的节点以及与它相关的所有关系。
3.4 使用 DETACH DELETE 直接删除节点及其关系
使用DETACH DELETE语句能更简洁地删除节点及其所有关系:
MATCH (p:Person {name: 'Bob'})
DETACH DELETE p
此操作会自动删除与Bob节点相关的所有关系,然后再删除Bob节点。
3.5 性能考量
进行大量关系删除操作时,建议采用分批处理的方式,防止内存不足。可以使用LIMIT和APOC程序来实现分批删除,示例如下:
CALL apoc.periodic.commit("
MATCH ()-[r:OLD_RELATIONSHIP]->()
WITH r LIMIT 1000
DELETE r
RETURN count(*)
")
这个方法每次会删除1000个OLD_RELATIONSHIP类型的关系,直至全部删除完毕。
三、索引与约束
// 创建唯一约束(确保用户名唯一)
(neo4j version <4.0)
CREATE CONSTRAINT ON (u:User) ASSERT u.name IS UNIQUE;
(neo4j version >= 4.0)
CREATE CONSTRAINT FOR (u:User) REQUIRE u.name IS UNIQUE;
// 创建索引(加速属性查询)
(neo4j version <4.0)
CREATE INDEX ON :User(age);
(neo4j version >= 4.0)
CREATE INDEX FOR (u:User) ON (u.age);
四、执行建议
-
使用 Neo4j Browser
- 启动 Neo4j 服务后,访问 http://localhost:7474,输入用户名和密码(默认
neo4j/neo4j,首次登录需修改)。
- 启动 Neo4j 服务后,访问 http://localhost:7474,输入用户名和密码(默认
-
可视化结果
- Neo4j Browser 会自动将查询结果以图形方式展示,节点用图标表示,关系用箭头连接。
-
性能提示
- 避免全图扫描(如
MATCH (n) RETURN n),始终使用标签和索引。 - 使用
EXPLAIN或PROFILE分析查询性能:EXPLAIN MATCH (u:User)-[:FRIENDS_WITH]->(f:User) RETURN u, f;
- 避免全图扫描(如
通过以上示例,你可以掌握 Neo4j 的基本操作。建议通过 Neo4j 官方文档 和 在线沙盒 进一步学习高级特性(如事务、聚合函数、APOC 过程等)。

















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









