



观看完本文后,你将能够认识到接受失败的重要性,解释从失败中快速恢复的重要性,描述重试模式、断路器模式和舱壁模式如何帮助应用程序抵御故障,并描述混沌工程。
一旦你将应用程序设计为一组无状态的微服务,就会有很多活动部件,这意味着可能会出现很多问题。
服务偶尔会响应缓慢,甚至出现故障,所以你不能总是指望在需要它们时它们就能正常可用。
希望这些故障持续时间很短,但你肯定不希望仅仅因为某个依赖服务运行缓慢,或者某天网络延迟很高,你的应用程序就出现故障。
这就是为什么你需要在应用程序层面进行故障设计。
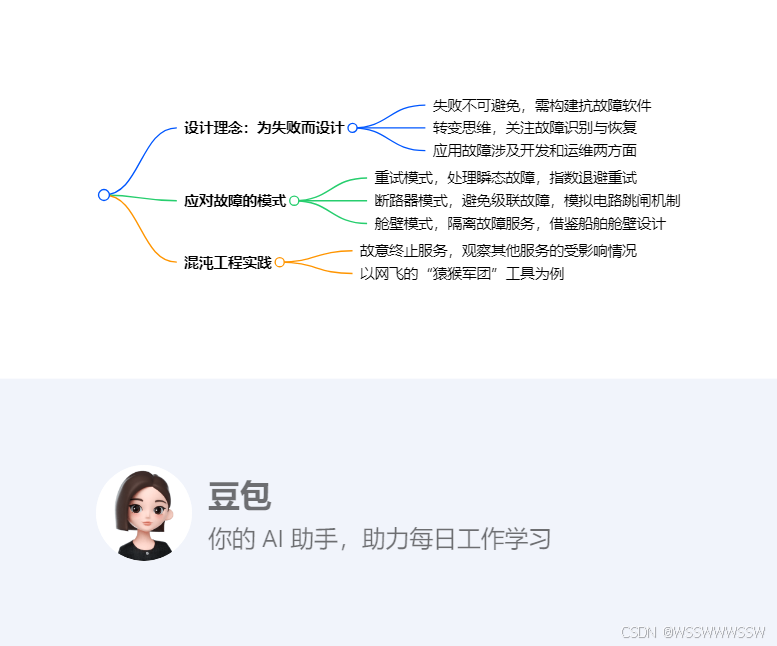
由于故障不可避免,你必须构建能够抵御故障并可横向扩展的软件。
我们必须为故障而设计。
我们必须接受失败。
失败是唯一不变的。
我们必须改变思维方式,从思考如何避免失败,转变为思考当失败发生时如何识别它,以及如何从中恢复。
这就是我们将 DevOps 度量指标从 “平均故障间隔时间” 转变为 “平均恢复时间” 的原因之一。
关键不在于努力不失败。
而在于确保当失败发生时(它必然会发生),你能够快速恢复。
应用程序故障不再仅仅是运维方面的问题。
它也是开发方面的问题。
为了使应用程序具有抗故障能力或弹性,开发人员需要从一开始就构建这种弹性。
而且由于微服务总是会对不受你控制的服务进行外部调用,这些服务就特别容易出现问题。
要做好被限流的打算。
你要为云服务提供商提供的一定服务质量水平付费,他们会按照协议来限制你。
比如说,你选择了一个每秒允许进行 20 次数据库读取操作的套餐。
当你超过这个限制时,服务就会对你进行限流。
你得到的将是 429_TOO_MANY_REQUESTS 错误,而不是 200_OK,你需要处理这种情况。
在这种情况下,你会重试,对吧。
这个逻辑需要写在你的应用程序代码中。
当你重试时,如果失败了,你要采用指数退避策略。
目的是要实现优雅降级。
如果可以的话,在适当的地方进行缓存,这样如果答案不会改变,你就不必总是对这些服务进行远程调用。
有很多模式是帮助你让应用程序具备弹性的重要策略。
我想介绍几种流行的模式。
第一种是重试模式。
它使应用程序在尝试连接服务或网络资源时,能够通过透明地重试和使操作失败来处理瞬态故障。
我听过开发人员说,必须在启动我的服务之前部署数据库,因为服务启动时需要数据库已经就位。
这是一种脆弱的设计,不适合云原生应用程序。
如果数据库未就绪,你的应用程序应该耐心等待,然后再重试。
你必须能够连接、重新连接,即便连接失败也要继续尝试连接。
这才是设计健壮的云原生微服务的方法。
这里的关键是重试模式,采用指数退避策略,每次重试之间的等待时间逐渐延长。
不要连续重试 10 次,把服务挤爆,而是重试一次,如果失败了。
等待 1 秒后再重试。
然后等待 2 秒,接着等待 4 秒,再等待 8 秒。
每次重试,你都按一定倍数增加等待时间,直到所有重试次数用完,然后返回错误状态。
这就给了后端服务时间,让它从导致故障的任何问题中恢复过来。
可能只是暂时的网络延迟。
断路器模式和你家里的电路断路器类似。
你可能在家里遇到过断路器跳闸的情况。
你可能做了一些超过电路功率限制的事情,导致灯熄灭。
这时你会拿着手电筒去地下室,重置断路器,让灯重新亮起来。
断路器模式的工作原理也是如此。
它用于识别问题,然后采取措施避免级联故障。
级联故障是指一个服务不可用,进而导致一系列其他服务也出现故障。
使用断路器模式,你可以通过跳闸并让备用路径返回有用信息,来避免这种情况,直到原始服务恢复,断路器再次关闭。
其工作方式是,只要断路器处于闭合状态,一切就会正常运行。
断路器会监控故障情况,直到达到一定限度。
一旦达到那个限制阈值,断路器就会跳闸打开,之后所有对断路器的调用都会返回错误,甚至不会调用受保护的服务。
然后在超时之后,它会进入半开状态,尝试再次与服务进行通信。
如果失败,它会立即回到打开状态。
如果成功,它会再次完全闭合。
舱壁模式可用于隔离出现故障的服务,限制故障的影响范围。
在这种模式下,使用单独的线程池可以通过将流量导向仍处于活动状态的备用线程池,帮助从数据库连接失败中恢复过来。
它的名字来源于船上的舱壁设计。
水线以下的舱室之间有被称为 “舱壁” 的墙壁。
如果船体破裂,只有一个舱室会进水。
舱壁能阻止水影响其他舱室,防止船沉没。
使用舱壁模式可以将消费者与服务隔离开来,避免级联故障,在服务出现故障时,使消费者仍能保留部分功能。
应用程序的其他服务和功能可以继续运行。
最后是混沌工程,也称为猴子测试。
虽然它不是一种软件设计模式,但它是一种很好的实践方法,可以证明你所有的设计模式在故障情况下都能按预期工作。
在混沌工程中,你故意终止一些服务,以观察其他服务受到的影响。
网飞(Netflix)有一套名为 “猿猴军团”(The Simian Army)的故障诱导工具。
“混沌猴子”(Chaos Monkey)专门负责随机终止实例。
网飞会随机终止一些服务,看看它们能否重新启动,以及系统是否能够优雅地恢复。
在生产环境中,只有当某个服务真的出现故障时,你才会知道它在故障情况下的反应。
所以,网飞故意这么做。
所有这些模式都可以帮助你构建更健壮的软件,优雅地应对间歇性故障。
在本文中,你了解到故障是不可避免的,所以我们要为故障而设计,而不是试图避免故障。
开发人员需要构建弹性机制,以便能够快速恢复。
重试模式通过重试失败的操作来起作用。
断路器模式旨在避免级联故障。
舱壁模式可用于隔离出现故障的服务。
混沌工程则是故意使服务出现故障,以观察其他服务受到的影响。
为故障而设计
于 2025-02-08 10:26:54 首次发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









