



 该项目使用两块W5100S-EVB-PICO板,一块连接Arducam和以太网传输图片到网页,另一块通过‘复制API’执行图像到文本字幕并显示在屏幕。采用BLIP - 2模型,其在零样本字幕方面表现出色。项目当前为图像加标题,未来或用于视障人士等应用。
该项目使用两块W5100S-EVB-PICO板,一块连接Arducam和以太网传输图片到网页,另一块通过‘复制API’执行图像到文本字幕并显示在屏幕。采用BLIP - 2模型,其在零样本字幕方面表现出色。项目当前为图像加标题,未来或用于视障人士等应用。
使用 W5100S-EVB-PICO 板进行的基本项目,利用复制的图像字幕模型生成图像描述

转发: Translating Visuals into Words: Image Captioning with AI
项目介绍
概述
在这个项目中,我们使用两块 W5100S-EVB-PICO 板。
1.第一块板连接Arducam和以太网,起到接收网络请求时将图片传输到网页的作用。

2.第二块板将通过“复制 API”以网址的形式执行图像到文本字幕,通过以太网连接提供来自第一块 PICO 板的图像,并将其显示在 ssd1306 OLED 屏幕上。
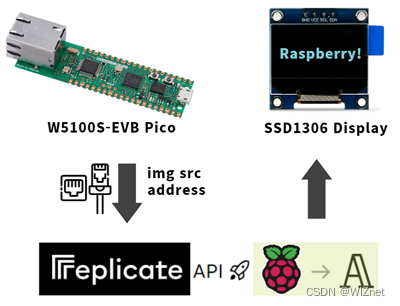
下面更详细地讨论这个问题。
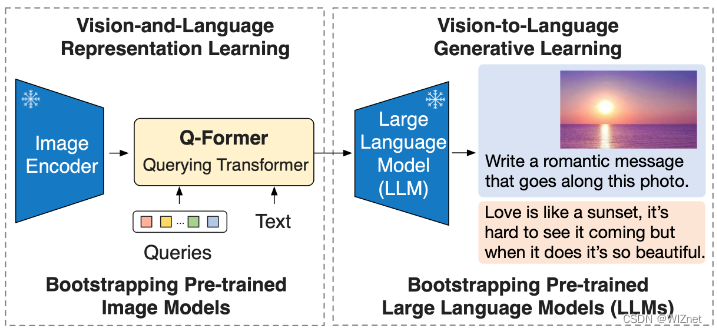
用于图像字幕的模型
BLIP-2 是 Salesforce LAVIS 项目的一部分。 BLIP-2 是一种通用且高效的预训练策略,它利用了预训练视觉模型和大语言模型 (LLM) 的进步。 BLIP-2 在零样本 VQAv2 中超越了 Flamingo(得分为 65.0 vs 56.3),并在零样本字幕方面创下了新的最先进水平(在 NoCaps 上获得了 121.6 的 CIDEr 分数,而之前的最高分数为 113.2)。 当与 OPT 和 FlanT5 等强大的法学硕士结合使用时,BLIP-2 推出了新的零样本指导视觉到语言生成功能,适用于一系列有趣的应用。
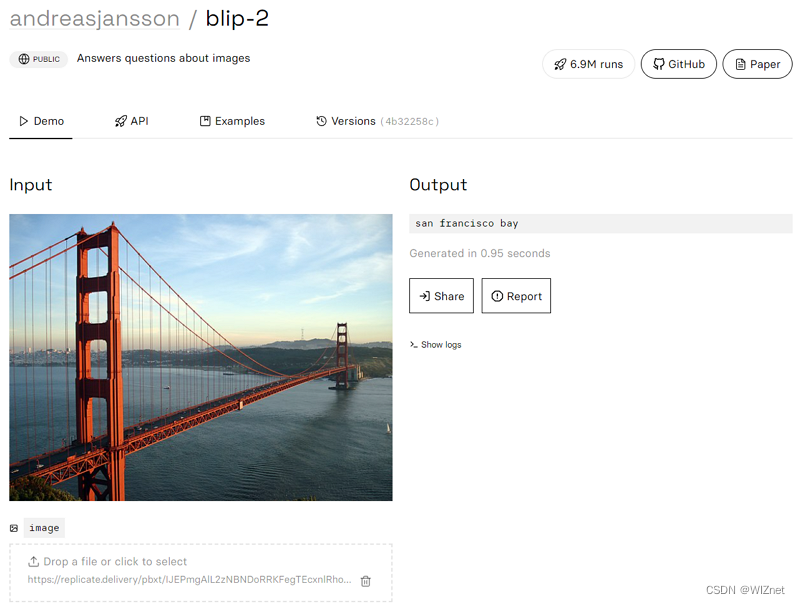
安装及使用方法
进行中
输出
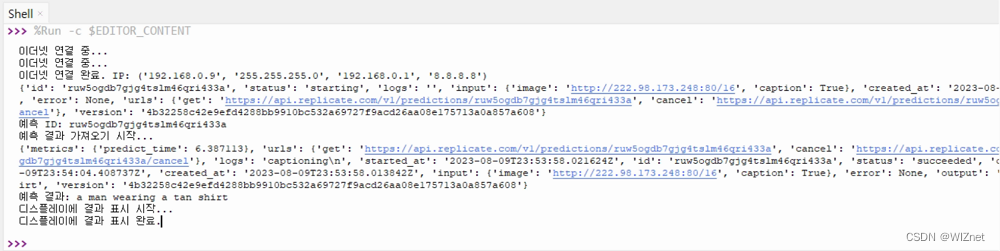

潜在的发展
该项目当前的重点是为图像添加标题并显示文本。 然而,通过在未来添加扬声器,这可能会演变成针对视障人士或异常检测的应用程序以及各种其他项目想法。
贡献和反馈
始终欢迎对该项目的贡献和反馈。 请使用 GitHub 问题跟踪器报告问题或创建拉取请求。
原文链接
文件
- circuitpython - arducam
我稍微修改了代码以获得更稳定的连接。
- micropython-captioning
使用 IMG2TXT 字幕 API 的代码

















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









