







一.获取测试数据源
二.读取数据源并进行处理
导入相应的模块
import requests
from bs4 import BeautifulSoup
import re
import json
import pandas as pd
数据读取
data = []
#由于数据源文件较大,建议处理的时候通过枚举的方式,通过控制索引 控制读取数据的数量
with open("arxiv-metadata-oai-snapshot.json", 'r') as f:
for index, line in enumerate(f):
# data.append(json.loads(line))
if index != 1000:
data.append(json.loads(line))
else:
break
通过pandas把数据进行简单的处理,筛选出自己想要的数据
data = pd.DataFrame(data) # 将list变为dataframe格式,方便使用pandas进行分析
data["year"] = pd.to_datetime(data["update_date"]).dt.year # 将update_date从例如2019-02-20的str变为datetime格式,并提取处year
del data["update_date"] # 删除 update_date特征,其使命已完成
data = data[data["year"] >= 2019] # 找出 year 中2019年以后的数据,并将其他数据删除
# data.groupby(['categories','year']) #以 categories 进行排序,如果同一个categories 相同则使用 year 特征进行排序
data.reset_index(drop=True, inplace=True) # 重新编号
print(data)
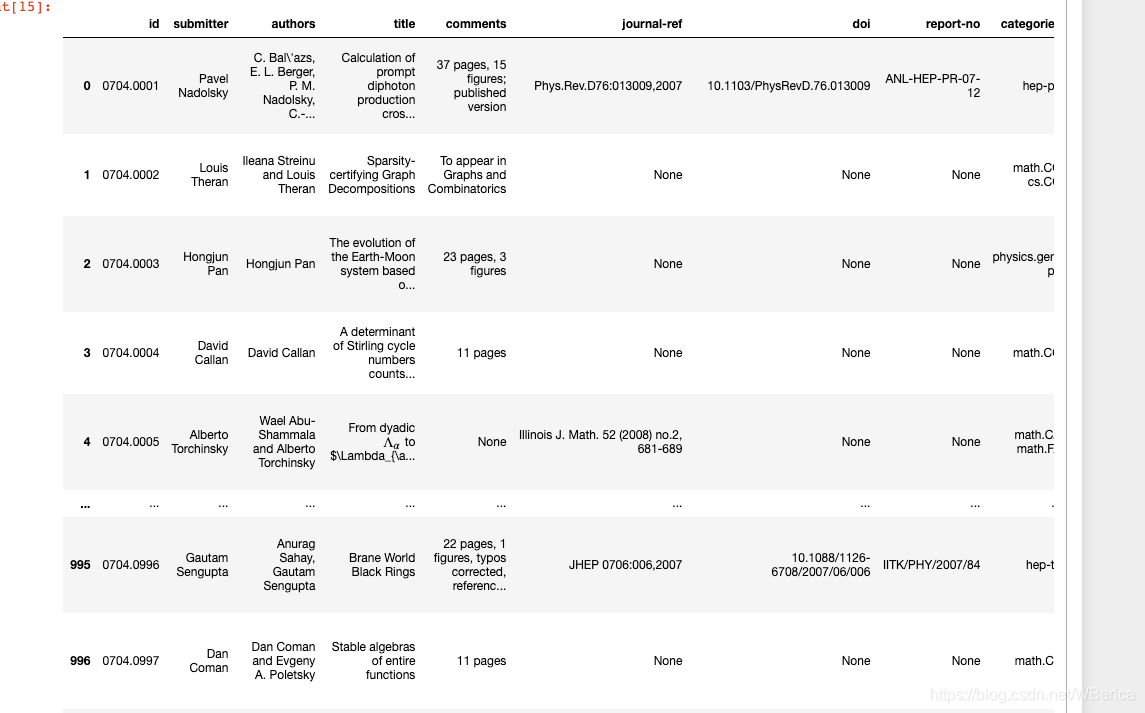
数据进一步处理,由于数据源类别较多,需要数据进行一个维度筛选,抓取数据的方法很多,下面是活动方给出的方案,我对提取提取数据的地方进行了更改,可以对入门更易理解
#爬取所有的类别
website_url = requests.get('https://arxiv.org/category_taxonomy',verify=False).text # 抓取过程中可能会遇到ssl认证的error 这里增加一下取消ssl的验证,配置参数:verify=False
soup = BeautifulSoup(website_url, 'lxml') # 爬取数据,这里使用lxml的解析器,加速
root = soup.find('div', {'id': 'category_taxonomy_list'}) # 找出 BeautifulSoup 对应的标签入口
tags = root.find_all(["h2", "h3", "h4", "p"], recursive=True) # 读取 tags
#初始化 str 和 list 变量
level_1_name = ""
level_2_name = ""
level_2_code = ""
level_1_names = []
level_2_codes = []
level_2_names = []
level_3_codes = []
level_3_names = []
level_3_notes = []
for t in tags:
if t.name == "h2":
level_1_name = t.text
level_2_code = t.text
level_2_name = t.text
elif t.name == "h3":
raw = t.text
level_2_code = re.sub(r"(.*)\((.*)\)", r"\2", raw) # 正则表达式:模式字符串:(.*)\((.*)\);被替换字符串"\2";被处理字符串:raw
level_2_name = re.sub(r"(.*)\((.*)\)", r"\1", raw)
# raw1 = t.text
# raw1_list = raw1.split("(")
# level_2_code = raw1_list[0].strip()
# level_2_name = raw1_list[1].split(")")[0].strip()
# raw1 = t.text
# level_2_code = re.match("(.*)\((.*)\)",raw1).group(1)
# level_2_name = re.match("(.*)\((.*)\)",raw1).group(2)
elif t.name == "h4":
raw = t.text
level_3_code = re.sub(r"(.*) \((.*)\)", r"\1", raw)
level_3_name = re.sub(r"(.*) \((.*)\)", r"\2", raw)
elif t.name == "p":
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
处理爬虫抓取过来的数据转成DataFrame格式
df_taxonomy = pd.DataFrame({
'group_name': level_1_names,
'archive_name': level_2_names,
'archive_id': level_2_codes,
'category_name': level_3_names,
'categories': level_3_codes,
'category_description': level_3_notes
})
# 按照 "group_name" 进行分组,在组内使用 "archive_name" 进行排序
df_taxonomy.groupby(["group_name", "archive_name"])
print(df_taxonomy.head())

关联读取的数据与爬虫抓取的数据
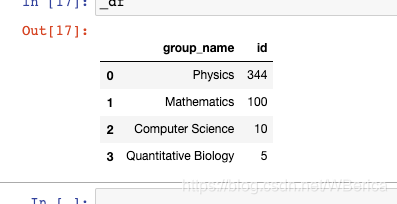
_df = data.merge(df_taxonomy, on="categories", how="left").drop_duplicates(["id","group_name"]).groupby("group_name").agg({"id":"count"}).sort_values(by="id",ascending=False).reset_index()
print(_df.head())
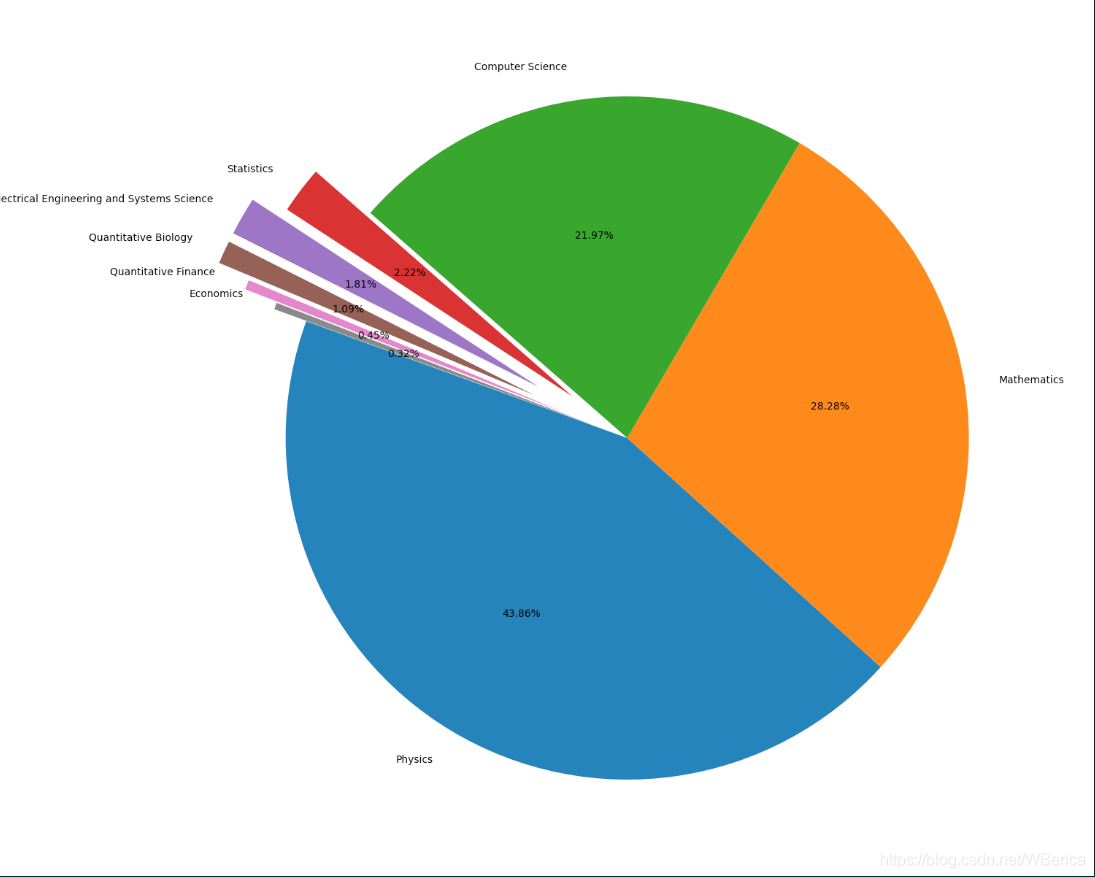
三.图表制作
import matplotlib.pyplot as plt # 画图工具
fig = plt.figure(figsize=(15,12))
#explode = (0, 0, 0, 0)
#plt.pie(_df["id"], labels=_df["group_name"], autopct='%1.2f%%', startangle=160)
explode = (0, 0, 0, 0.2, 0.3, 0.3, 0.2, 0.1)
plt.pie(_df["id"], labels=_df["group_name"], autopct='%1.2f%%', startangle=160, explode=explode)
plt.tight_layout()
plt.show()
四.总结
本项目适合数据分析新手练习使用,需要有一点python的基础,了解pandas和matplotlib的基本使用

















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









