




 本文深入探讨Transformer模型中的Self-Attention和Multi-HeadAttention机制。Self-Attention允许模型关注输入序列的不同位置信息,而Multi-HeadAttention通过结合多个注意力头,提升了模型从不同表示子空间学习的能力,广泛应用于自然语言处理和计算机视觉任务中。
本文深入探讨Transformer模型中的Self-Attention和Multi-HeadAttention机制。Self-Attention允许模型关注输入序列的不同位置信息,而Multi-HeadAttention通过结合多个注意力头,提升了模型从不同表示子空间学习的能力,广泛应用于自然语言处理和计算机视觉任务中。
转载大佬:详解Transformer中Self-Attention以及Multi-Head Attention
原文名称:《Attention Is All You Need》
原文链接:https://arxiv.org/abs/1706.03762
最近Transformer在CV领域很火,Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的(之前的RNN模型记忆长度有限且无法并行化,只有计算完 t i 时刻后的数据才能计算 t i + 1 时刻的数据,但Transformer都可以做到)。在这篇文章中作者提出了Self-Attention的概念,然后在此基础上提出Multi-Head Attention,所以本文对Self-Attention以及Multi-Head Attention的理论进行详细的讲解。
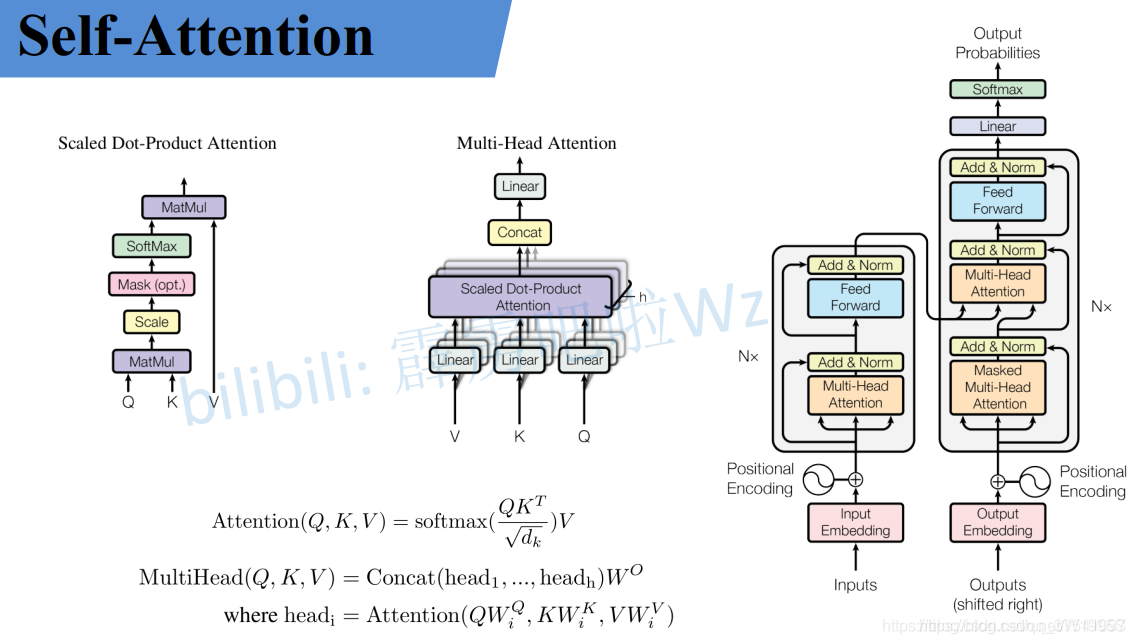
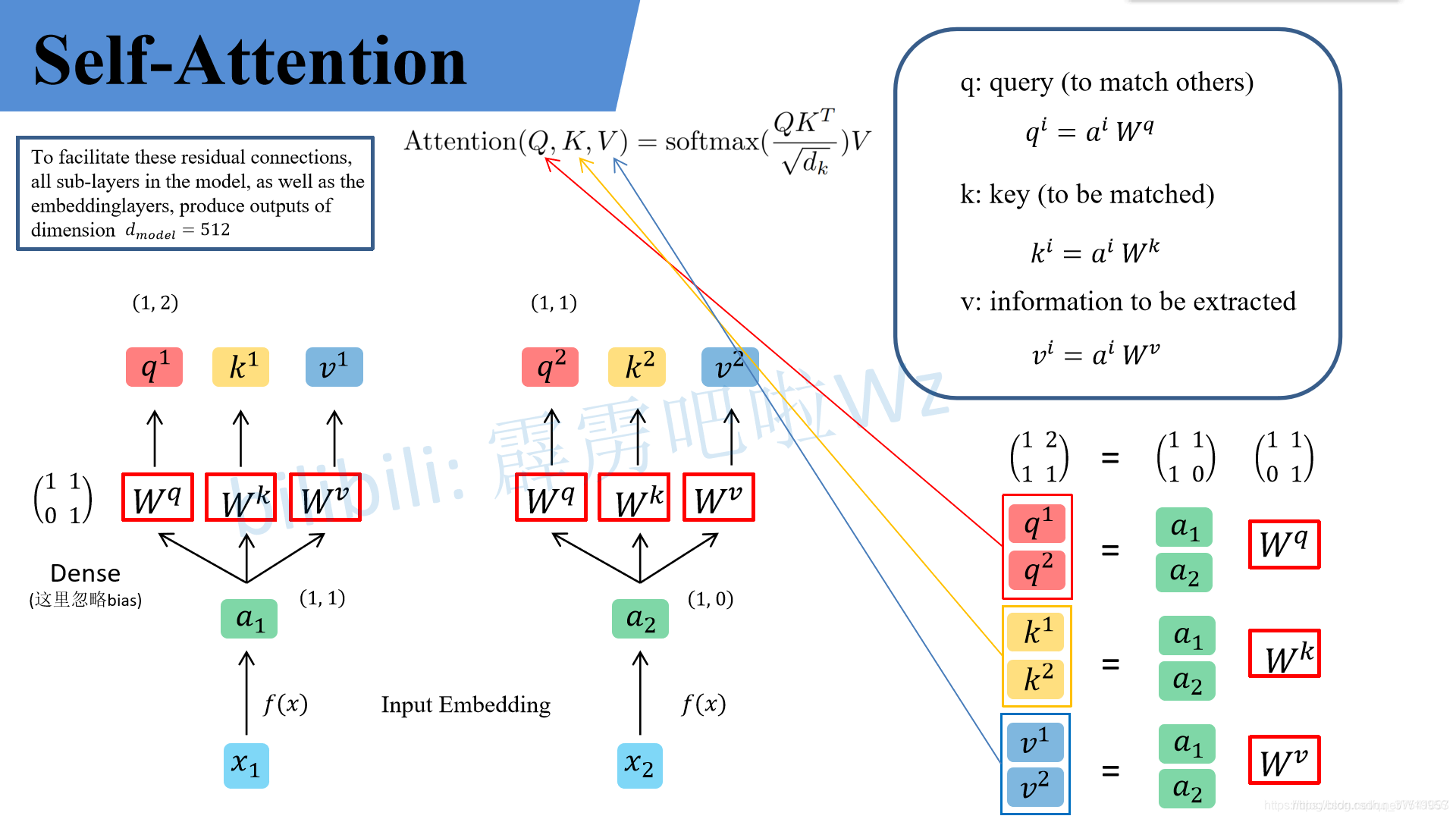
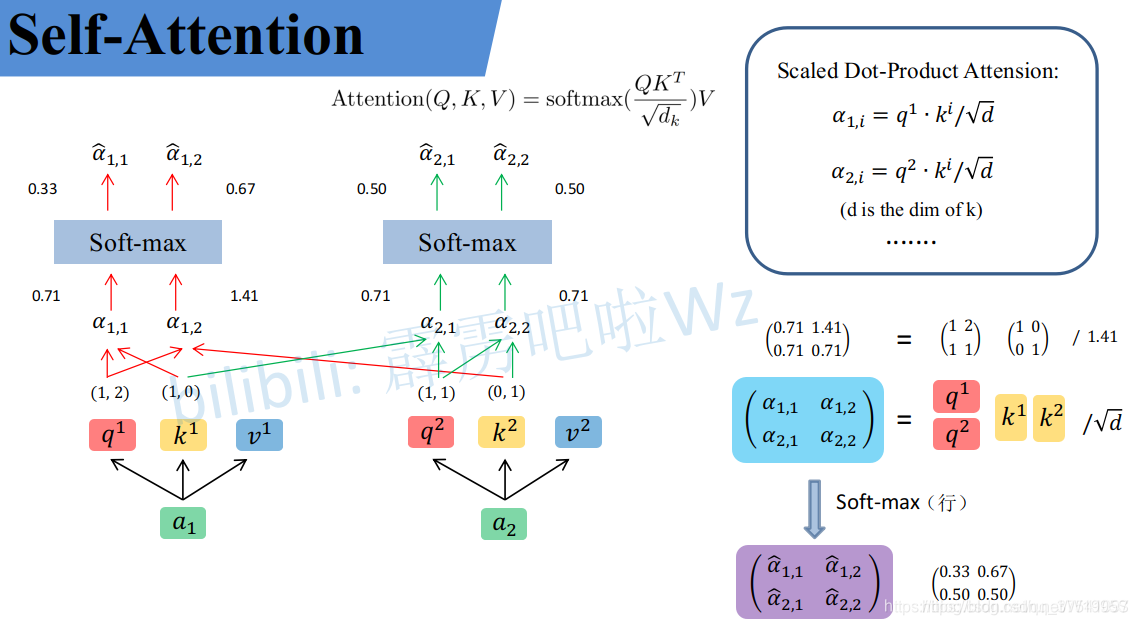
Self-Attention

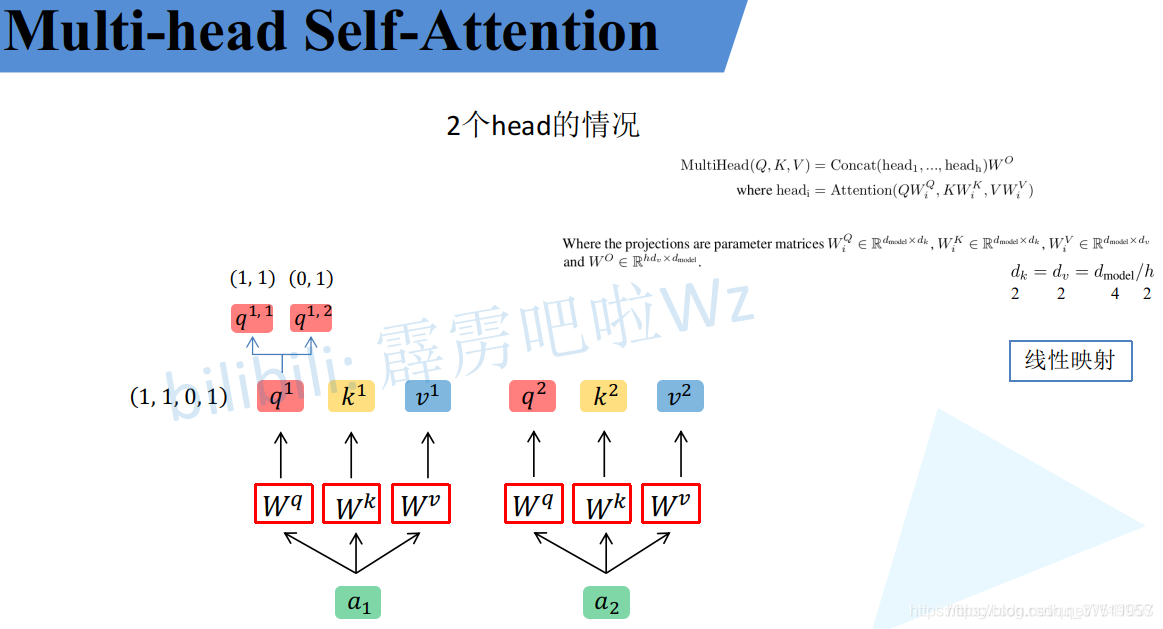

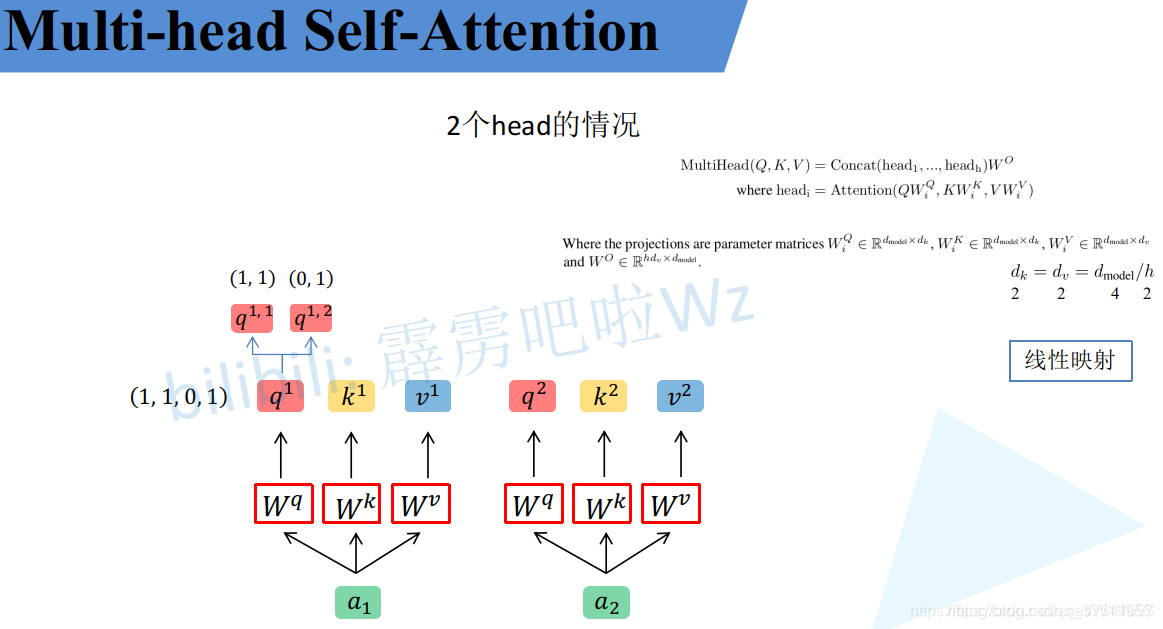
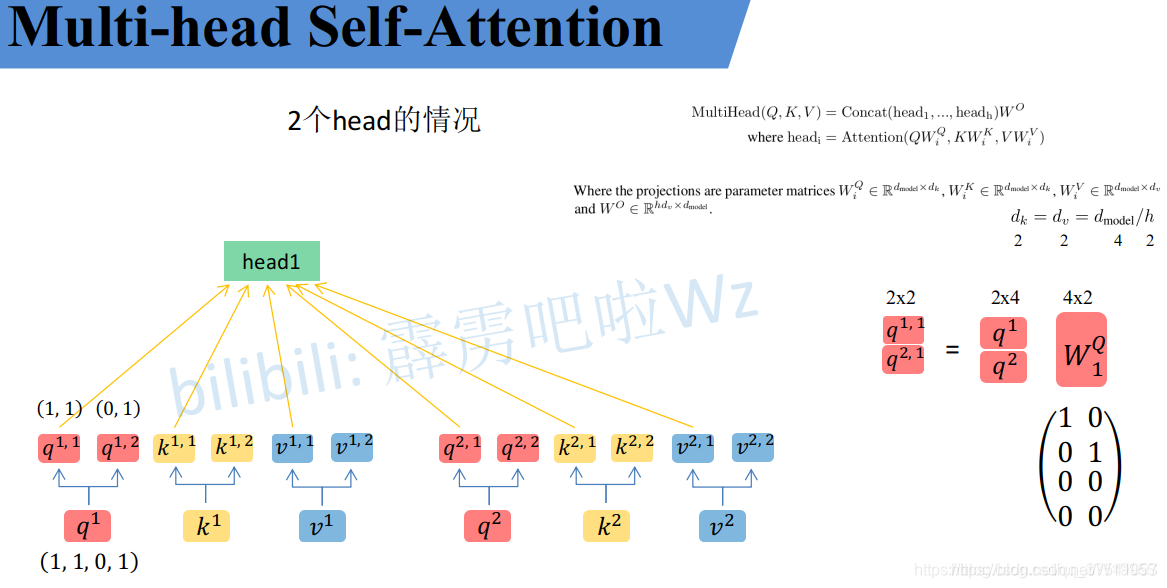
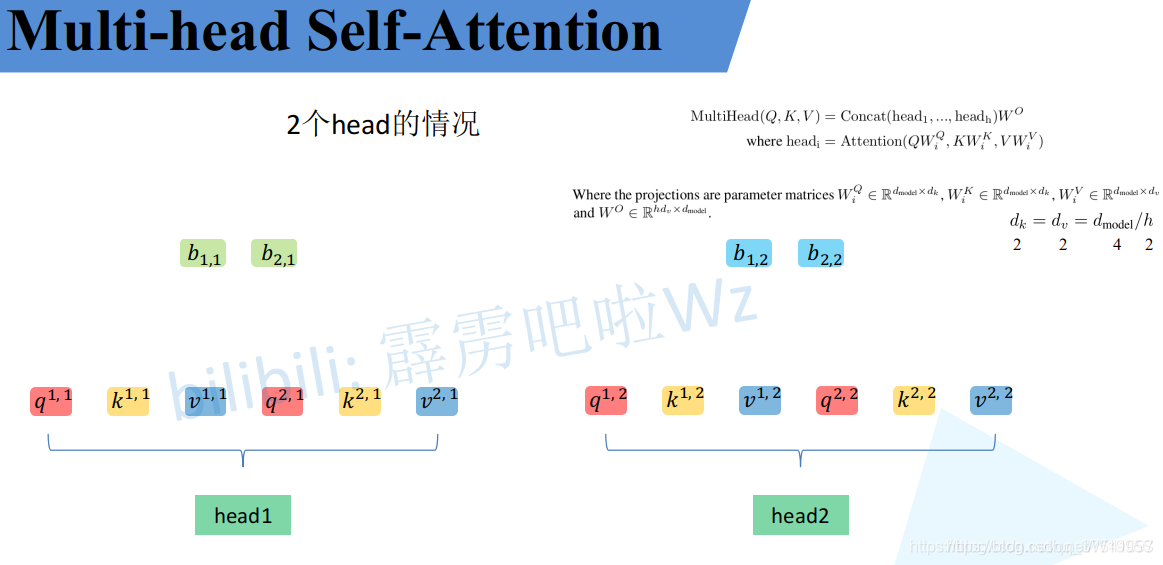
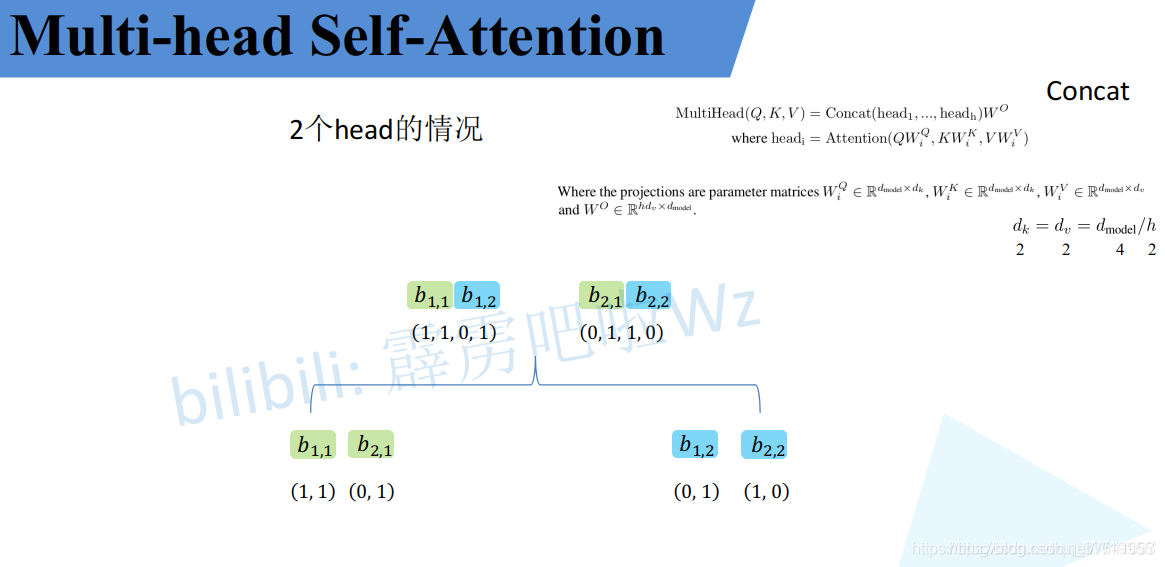
Multi-Head Attention
刚刚已经聊完了Self-Attention模块,接下来再来看看Multi-Head Attention模块,实际使用中基本使用的还是Multi-Head Attention模块。原论文中说使用多头注意力机制能够联合来自不同head部分学习到的信息。Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.其实只要懂了Self-Attention模块Multi-Head Attention模块就非常简单了。



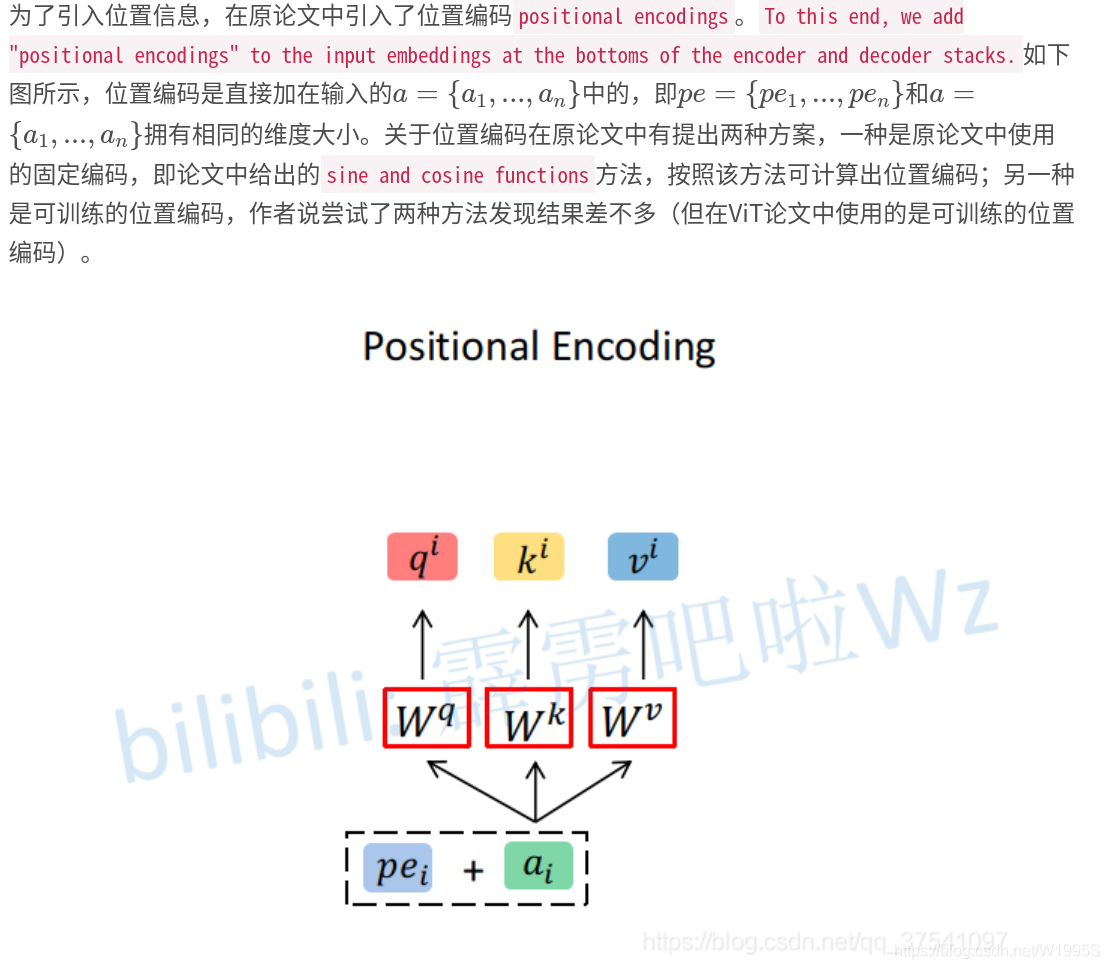
positional encodings

















 6143
6143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









