




 本文详细解析了一种寻找数组中丢失和重复数值的算法,通过创建一个额外的计数数组来记录每个元素出现的次数。当计数为0时,表示找到丢失的数值,计数为2则表示找到重复的数值。这种方法适用于处理1到n的整数数组。文章强调了理解并掌握这种算法的重要性。
本文详细解析了一种寻找数组中丢失和重复数值的算法,通过创建一个额外的计数数组来记录每个元素出现的次数。当计数为0时,表示找到丢失的数值,计数为2则表示找到重复的数值。这种方法适用于处理1到n的整数数组。文章强调了理解并掌握这种算法的重要性。
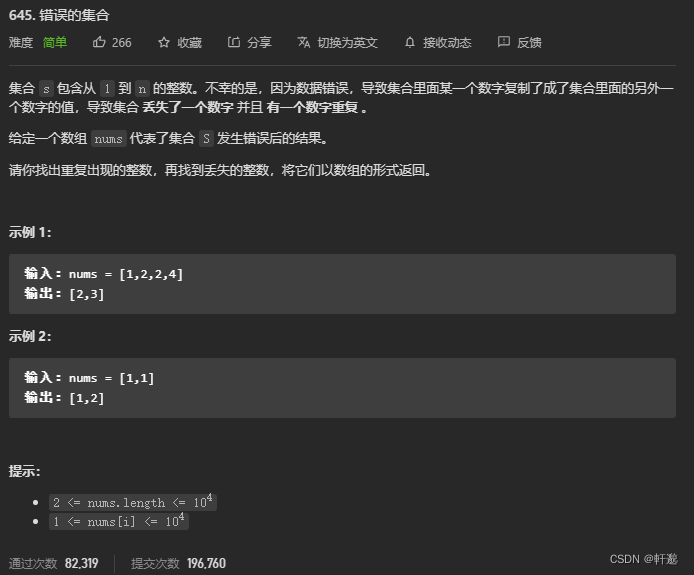
原创:
int* findErrorNums(int* nums, int numsSize, int* returnSize)
{
int *pArryVal = (int *)malloc(sizeof(int)*2); /* pArryVal[0]用来存储重复的值 和 pArryVal[1]用来存储丢失的值 */
int iArry[numsSize + 1]; /* 该数组是来存储 nums 数组中每个元素出现的次数 */
*returnSize = 2; /* 返回数组的元素的个数 */
memset(iArry,0,sizeof(iArry)); /* 注意在使用前面清理下,否则里面存储的是垃圾值 */
for(int i = 0; i < numsSize; i++) /* 因为 nums 中的元素是从 0 开始存储的,所以这里遍历是从 0 开始 */
{
iArry[nums[i]] ++; /* 将 nums 数组中的值当作 iArry 的下标来进行 ++ ,因为根据题目他是个1~n的值,所以可以根据这一特性 */
}
for(int i = 1; i <= numsSize; i++) /* 此时 i 就相当于 nums 数组中的值,对其进行遍历,注意这里需要是等号 */
{
if(iArry[i] == 0) /* 一次都没有出现,说明这个值就是丢失的值 */
{
pArryVal[1] = i;
}
if(iArry[i] == 2) /* 出现了两次,说明这个值就是重复的值 */
{
pArryVal[0] = i;
}
}
return pArryVal;
}
解释:
/*
举例说明下,为什么需要加上“=”号:
1.第一在上面定义存储 nums 数组每个元素出现的次数时,数组的大小是 numsSize + 1;
2.为什么是 numsSize + 1? 举例:[5,4,4,2,1] 这个是 nums 数组;你会发现,他最大的值为5,
那么如果他要作为数组的下标的话,那么这个数组的长度需要是6才可以,不然就会越界,
因为数组的下标是从0开始计数的;
3.所以在下面数组遍历的时候,需要算上 numsSize ,因为其本来就是一个正常数组下标,再举例,[1,1] 为 nums 数组,
那么此时计数元素次数的数组中,iArry[1] = 2; iArry[2] = 0; 并且 iArry[2] 就是
表示的丢失的数,因为 nums 数组中元素的大小是从1~n,所以计数数组中所有的 iArry[0]
都是等于0的,无意义。
*/
总结:
不单单需要知道,还得掌握,掌握就要弄得清清楚楚!






















 到【灌水乐园】发言
到【灌水乐园】发言









