




运维课程第三周小结
第七天 文件压缩和软件管理
7.1 UOS的安装
- 安装方式同Ubuntu,此处不再赘述
7.2 软件管理
需要记住术语和流程
7.2.1 软件相关概念
- 接口本质是约定,约定了输入什么、输出什么、遵守什么规则
- API和ABI
7.2.2 程序编译
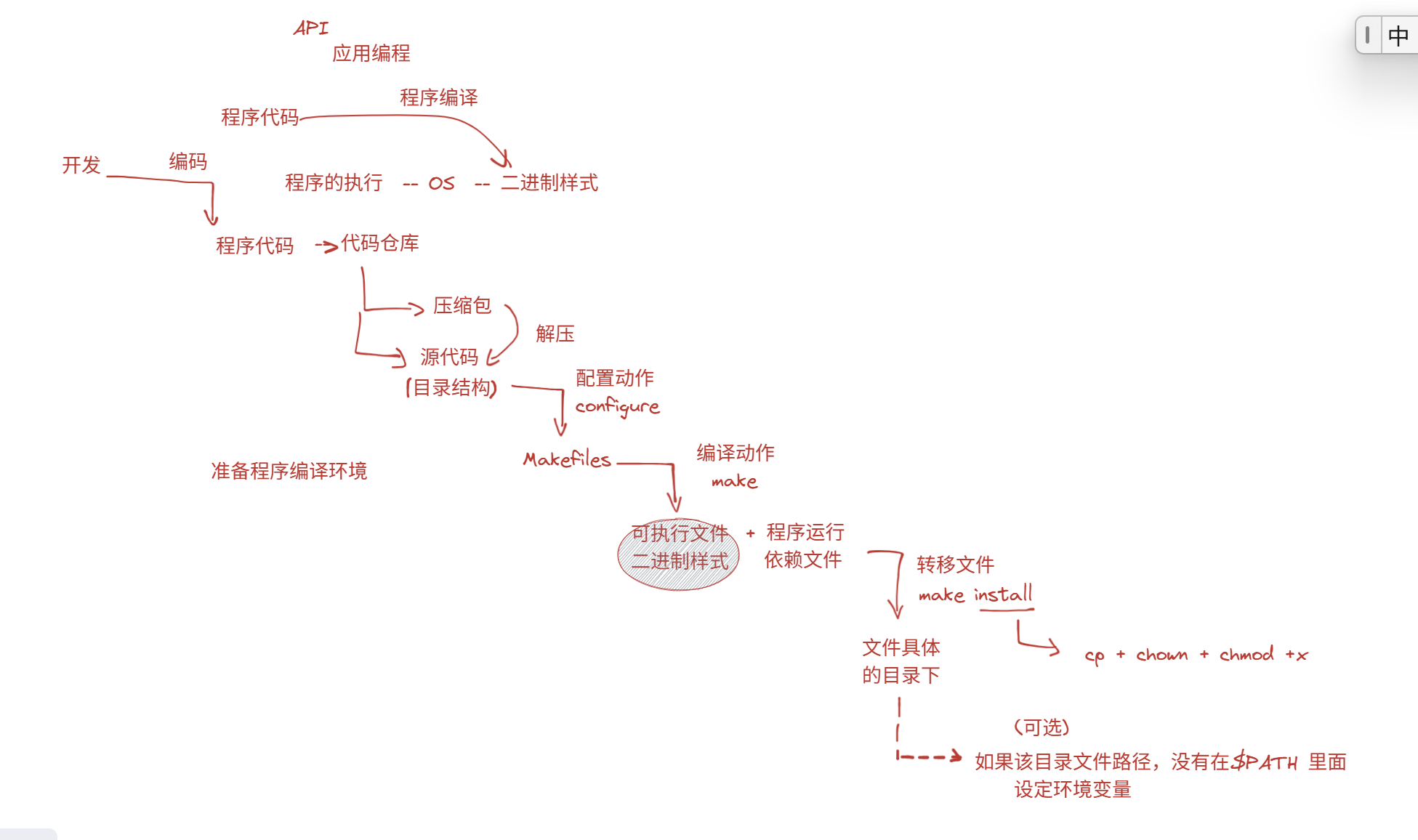
- 程序编译就是从程序代码变成二进制样式的可执行文件的过程
- 开发人员写好的程序代码放在代码仓库中,有两种获取风格
- 源代码风格(一个一个的目录文件)
- 压缩包,解压后就会变成源代码
- 我们需要准备程序编译环境,进行配置(哪个模块运行,哪个模块不运行之类的)
- Makefiles相当于剧本(把每个步骤要干什么写好)
- make(编译动作)相当于把剧本拍摄出来
- make出来可执行文件和程序运行依赖文件
- 这些文件都在临时目录里,需要被转移(make install)
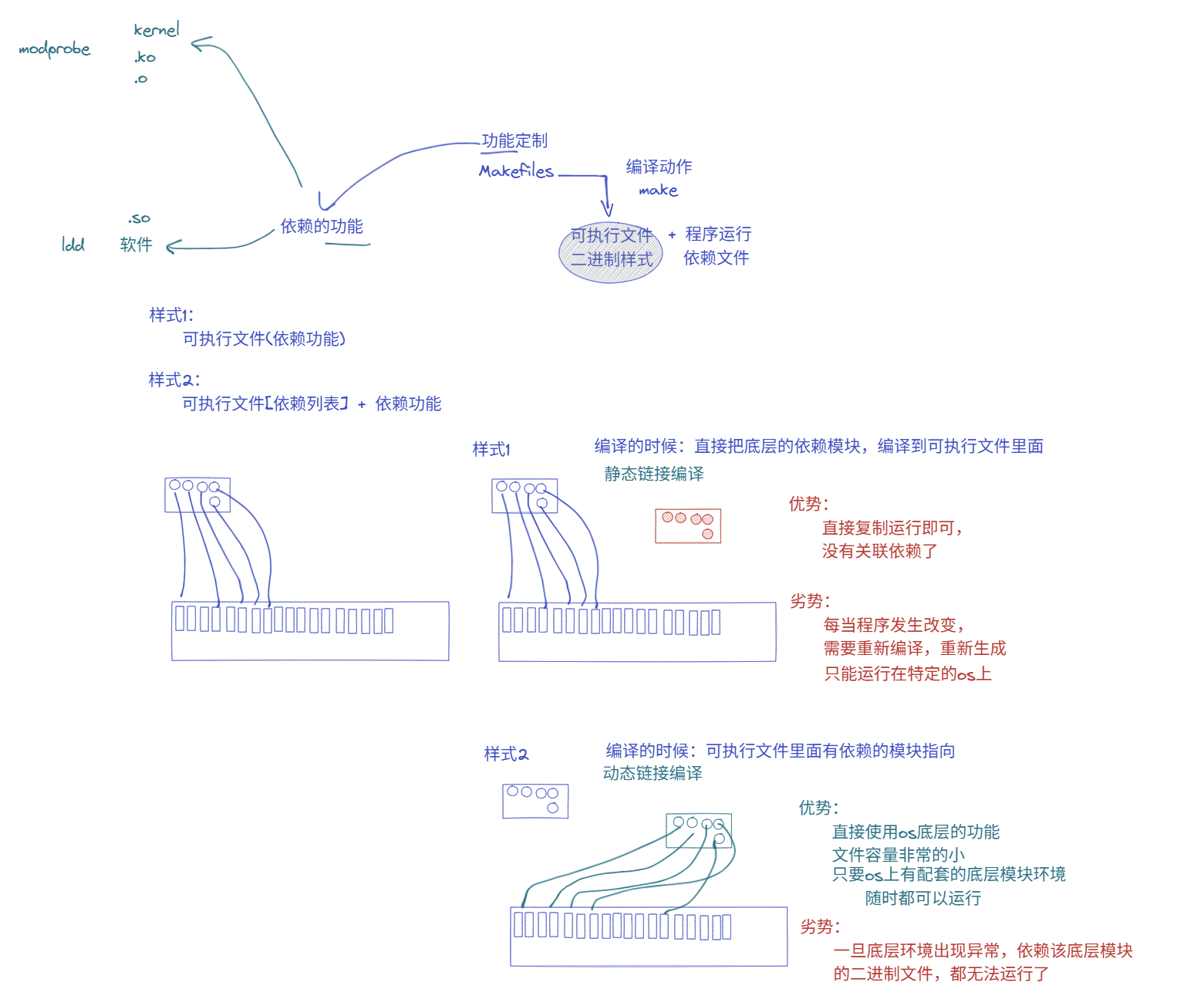
- 在操作系统中有很多依赖模块
- 有两种样式:
- 静态链接编译(相当于带着教练团队去各个球队执教)
- 动态链接编译(自己一个人,去球队里面找符合条件的教练)
7.3 软件包功能简介
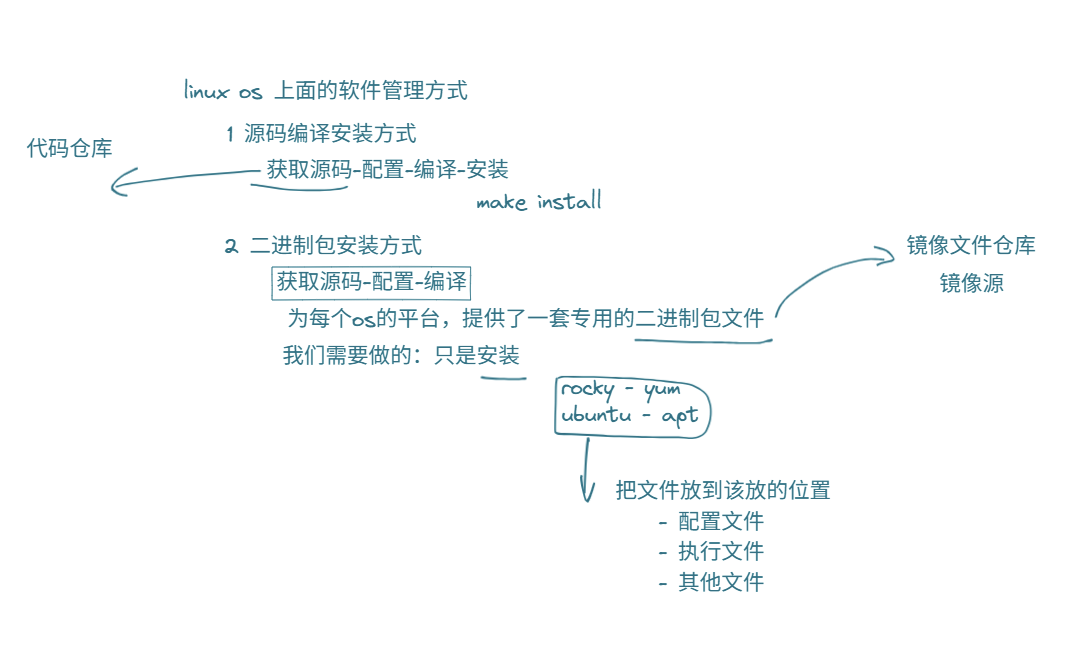
Linux os上有两种软件管理方式
- 源码编译安装方式(一步一步全都自己来),获取源头是代码仓库
- 二进制包安装方式(只要自己安装),也就是apt或yum ——把文件放到该放的位置
获取位置是镜像源(阿里云,南京大学镜像站等等)
而二进制包安装方式还可以拆分成两种:
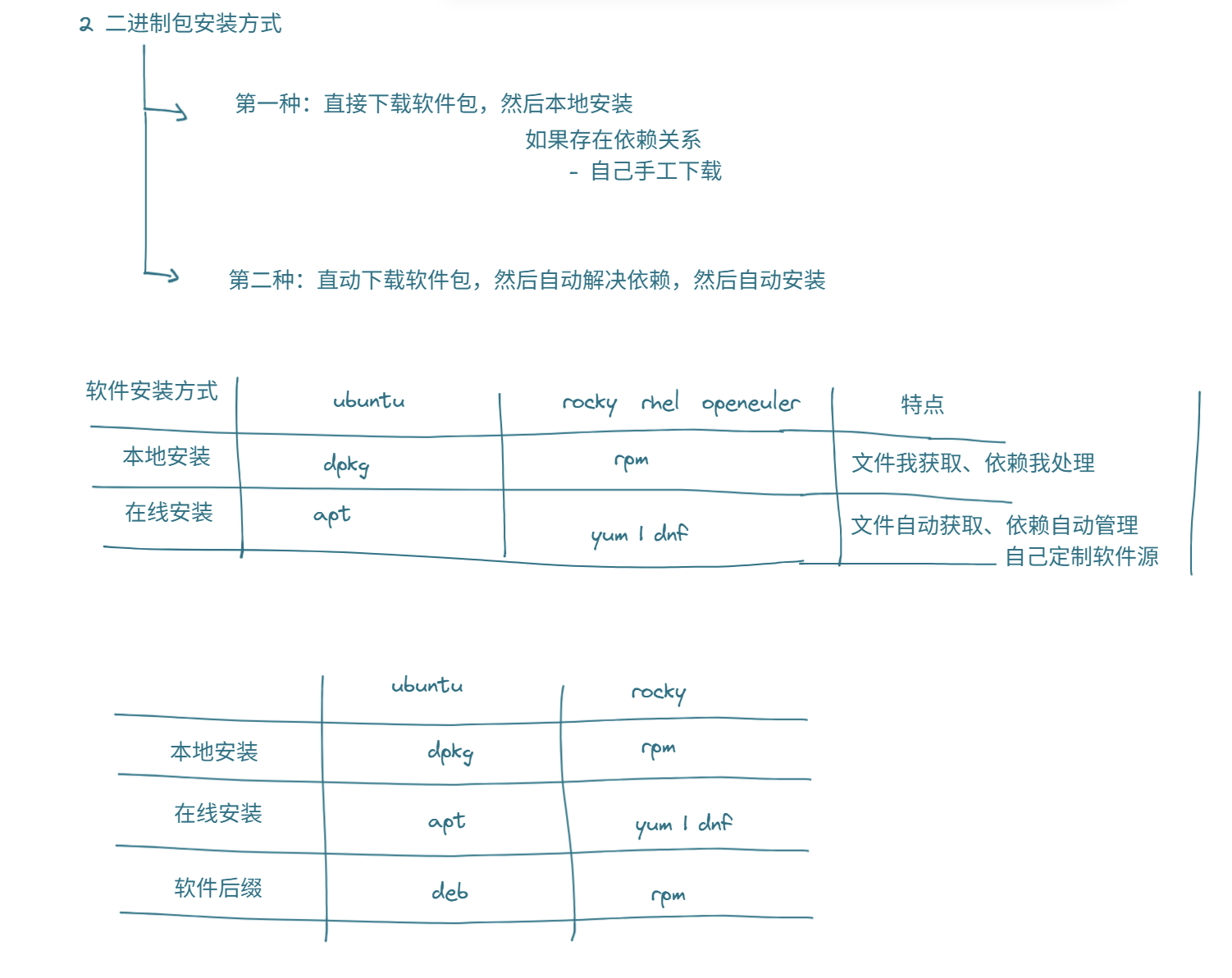
- 手动安装 dpkg和rpm
- 自动安装 apt和yum | dnf
7.4 实战演练
/etc/skel ——新用户的一些基础配置会从这个目录下面拿,所以我们的.rc文件要放进去
systemctl set-default multi-user.target -- 用来把os图形界面改成默认文字界面
进行rocky中软件下载演示:
mkdir /data/softs -p
cd /data/softs
yum--downloadonly --downloaddir=./ install nginx -- 指定目录仅下载不安装
源码包打包文件命名:软件包名字……tar.gz
二进制打包文件命名:软件包名字……架构.rpm
想看光盘文件/dev/cdrom,就需要挂载mount到一个空目录里去看
mount /dev/cdrom /mnt
ls /mnt
镜像在BaseOS和AppStream里
BaseOS里的Packages是包文件所在目录,repodata是仓库文件所在
7.5 包管理器rpm
mkdir /data/softs
cd /data/softs
wget ...
我从网上通过wget命令下载了一些二进制安装包的链接下来,接下来我需要做的就是安装了
rocky环境软件安装:rpm -ivh
rocky环境软件卸载:rpm -evh
查看指定的程序包安装后生成所有文件:rpm -ql
查看指定的文件由哪个程序包安装生成:rpm -qf(从哪个路径)
查看信息:rpm -qi(名字,架构之类的具体信息)
7.6 yum和dnf
- yum由服务端和客户端组成
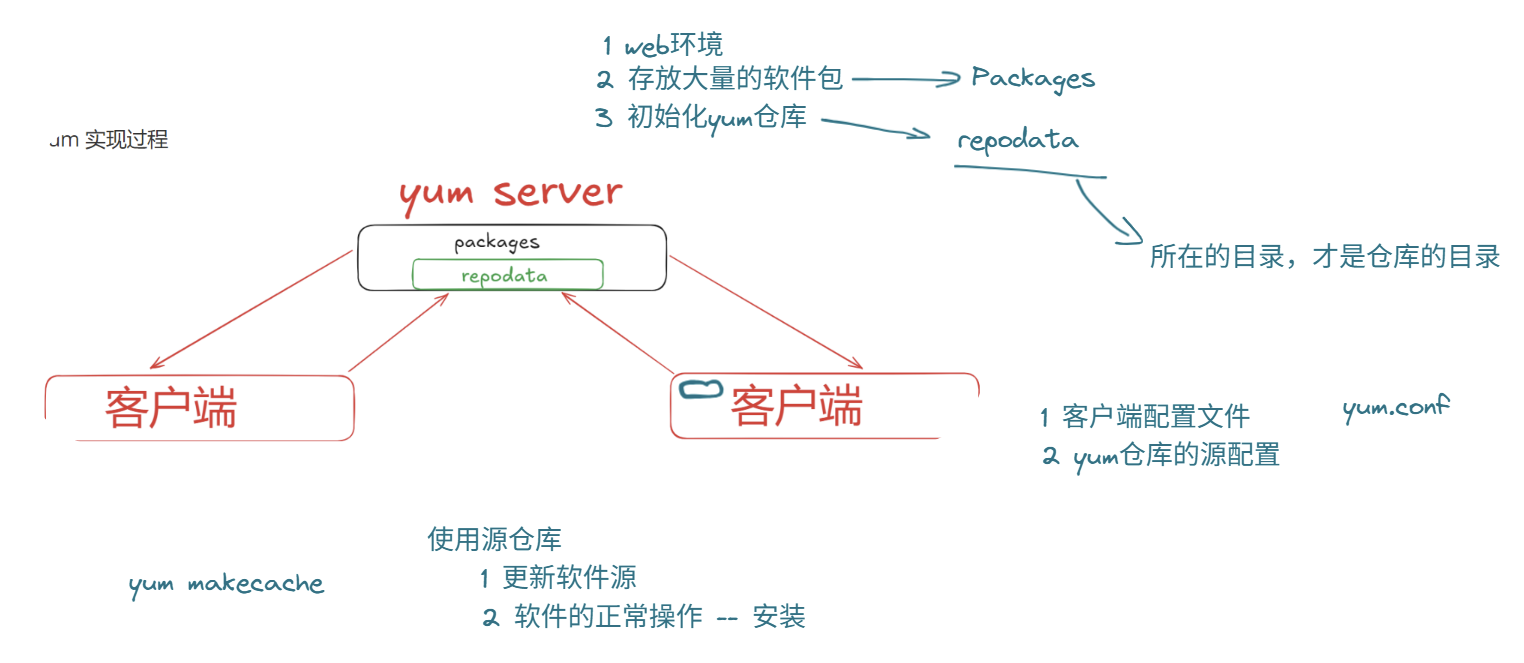
-
服务端:配置yum server
- 要准备web环境,因为一般界面就是一个web网站
- 存放大量的软件包(松散的,需要yum仓库搜集源数据信息,找到依赖)放到Packages
- 初始化yum仓库 放到repodata
-
客户端:
- yum.conf
- yum仓库的源配置
使用源仓库
- 更新软件源
yum makecache,把更新后的repodata拿到本地 - 安装
服务端是别人来操作的,我们只需要关心客户端怎么来配置
首先看看yum仓库在哪里吧
cat /etc/yum.conf -- 这是主配置所在的地方,一般不用去改,用默认的就可以
在/etc/yum.repos.d下有大量repo文件,里面都是仓库
cd /etc/yum.repos.d/ -- 仓库配置文件所在地
cat rocky.repo
主配置:
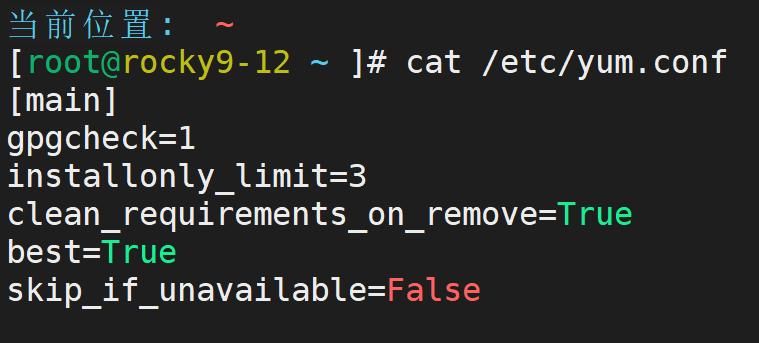
gpgcheck是包检测,一般来说禁用
软件源仓库配置
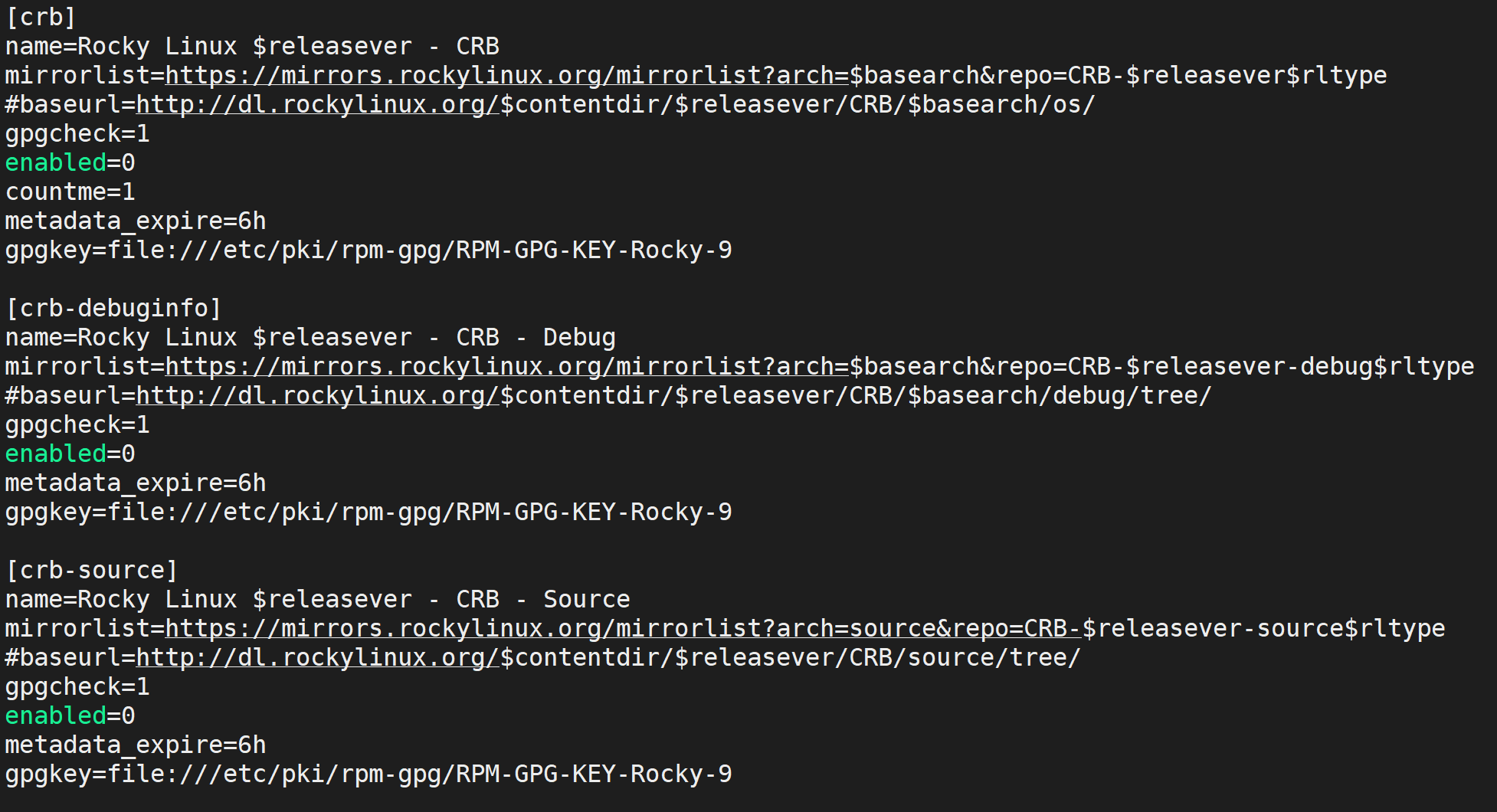
每一个[ ]都是一个软件源仓库配置段
其中:
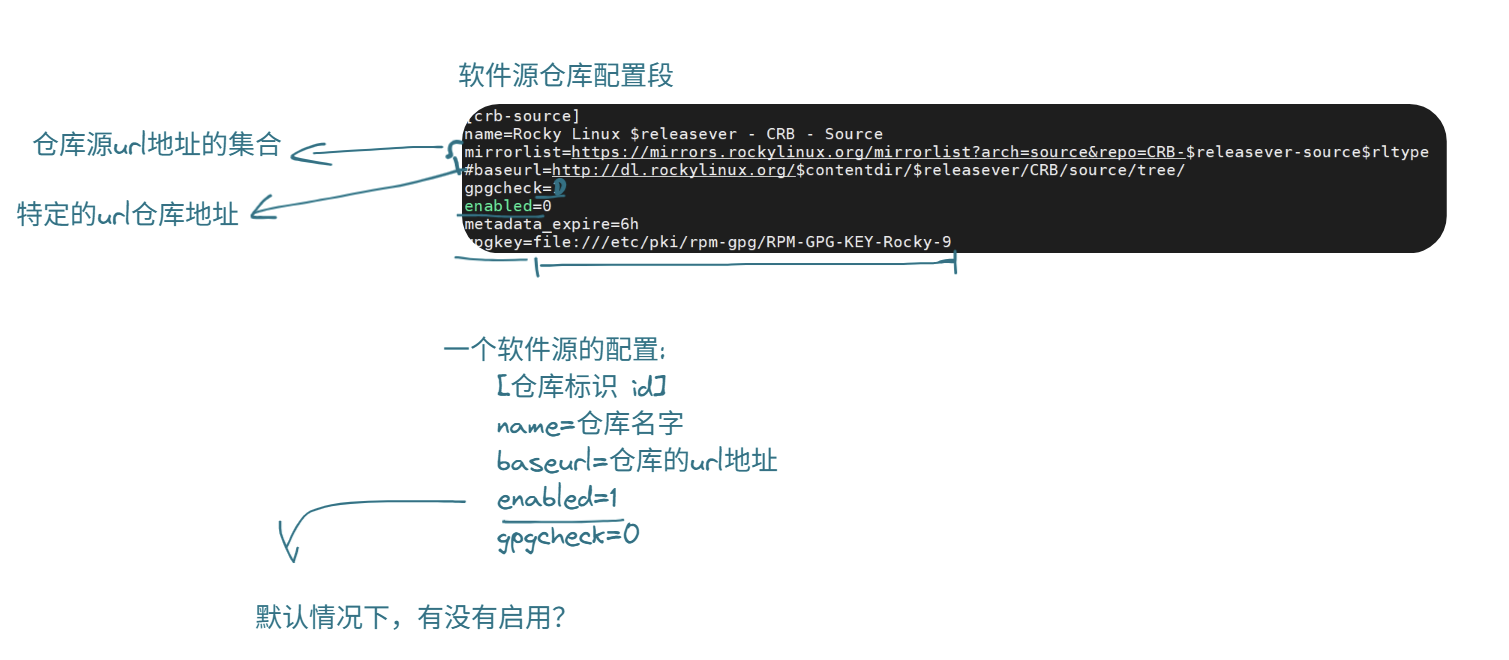
- mirrorlist中有很多url地址,是集合,不建议使用(随机挑一个用)
- baseurl是特定仓库地址(建议用,可以自己选择速度快的)
- gpgcheck=0 从我选择的仓库中下载文件时不要检查
- enable=1 仓库要用就为1,不用为0
服务端中动不动就会增加一些新东西,6h是我们更新的周期
yum makecache -- 更新状态
接下来我们进行实战
cd /etc/yum.repos.d/
mkdir bak/
mv rocky* bak/ -- 先备份一下源文件
接下来我们自己搞一个yum仓库源配置
cp /bak/rocky.repo aliyun.repo -- 直接复制一个出来
vim aliyun.repo
把里面的内容删除至只留一个配置段

看到baseurl里面的条件,环境变量需要自己按照情况配置(arch查看自己主机的arch)
但这个是官方的,我不用,我选择阿里云的
找相同格式的url
粘贴上去

编辑完软件源之后每次都需要更新一下 yum makecache
可以再加一个仓库,用来安装其他文件的
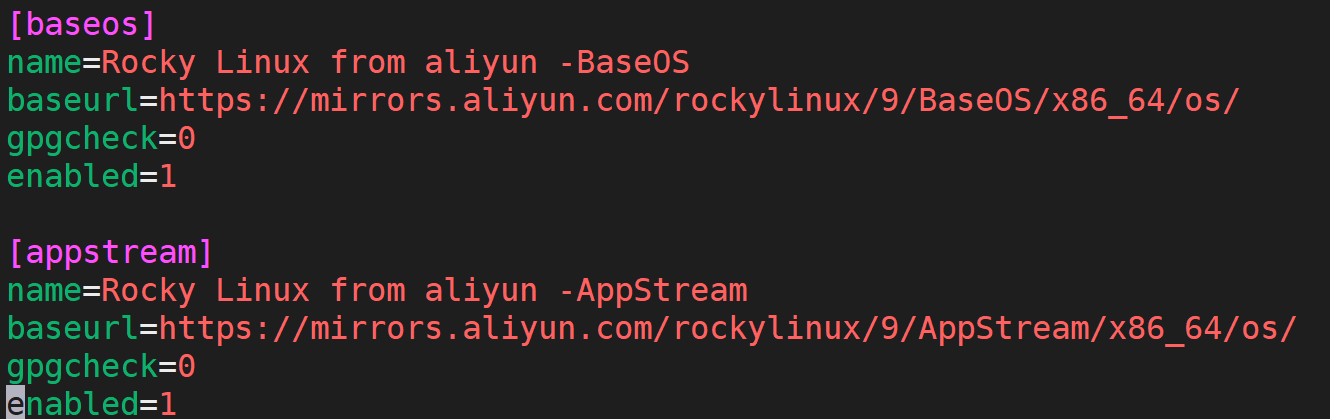
我们来看看刚刚配置好的软件源仓库:
yum repolist
同时,我们也可以连接到本地的库
ls /mnt/BaseOS
cp aliyun.repo basecdrom.repo
vim basecdrom.repo
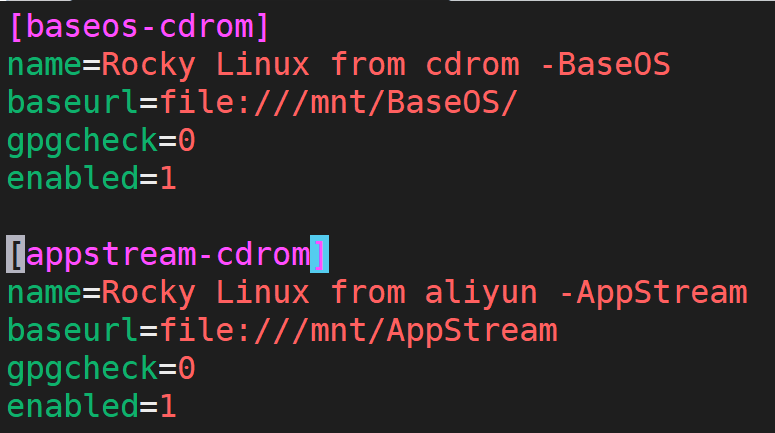
在线的协议是http,本地的就换成file://
id也需要修改(否则会覆盖)
得到的效果: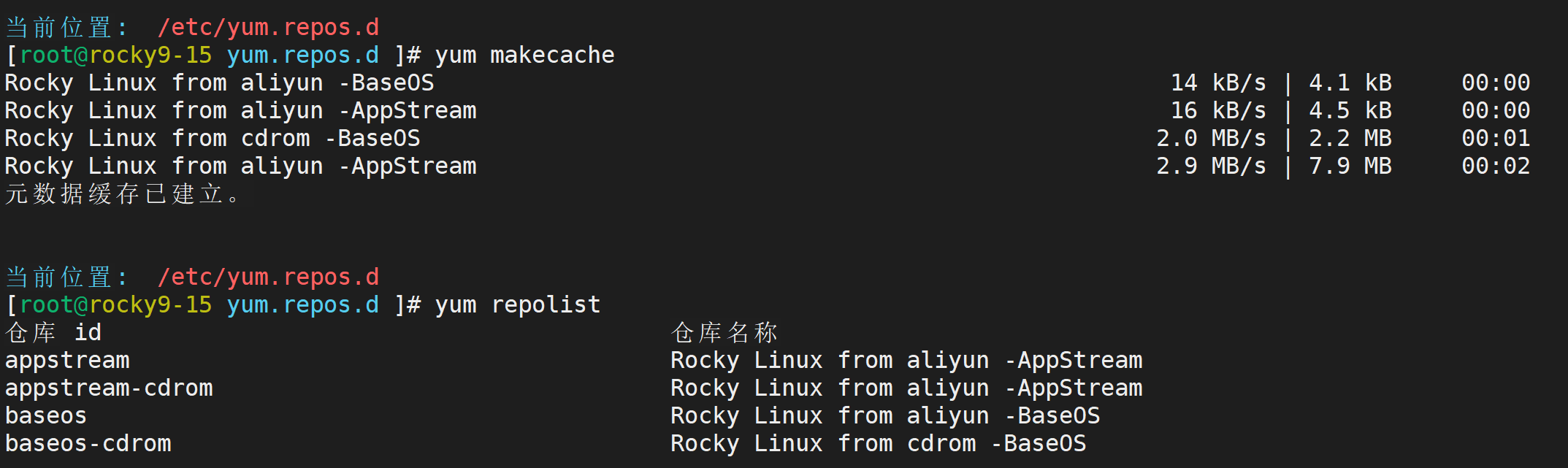
7.7 yum命令
yum install -- 安装
yum autoremove -- 卸载
yum clean -- 清除缓存
yum makecache -- 建立缓存
yum list -- 列出所有包
yum info -- 查看当前软件信息
常见软件会分成很多小组
yum group... -- 多一个group前缀
在groupinstall的时候。可能会出现兼容性问题,需要yum update一下
7.8 虚拟机克隆
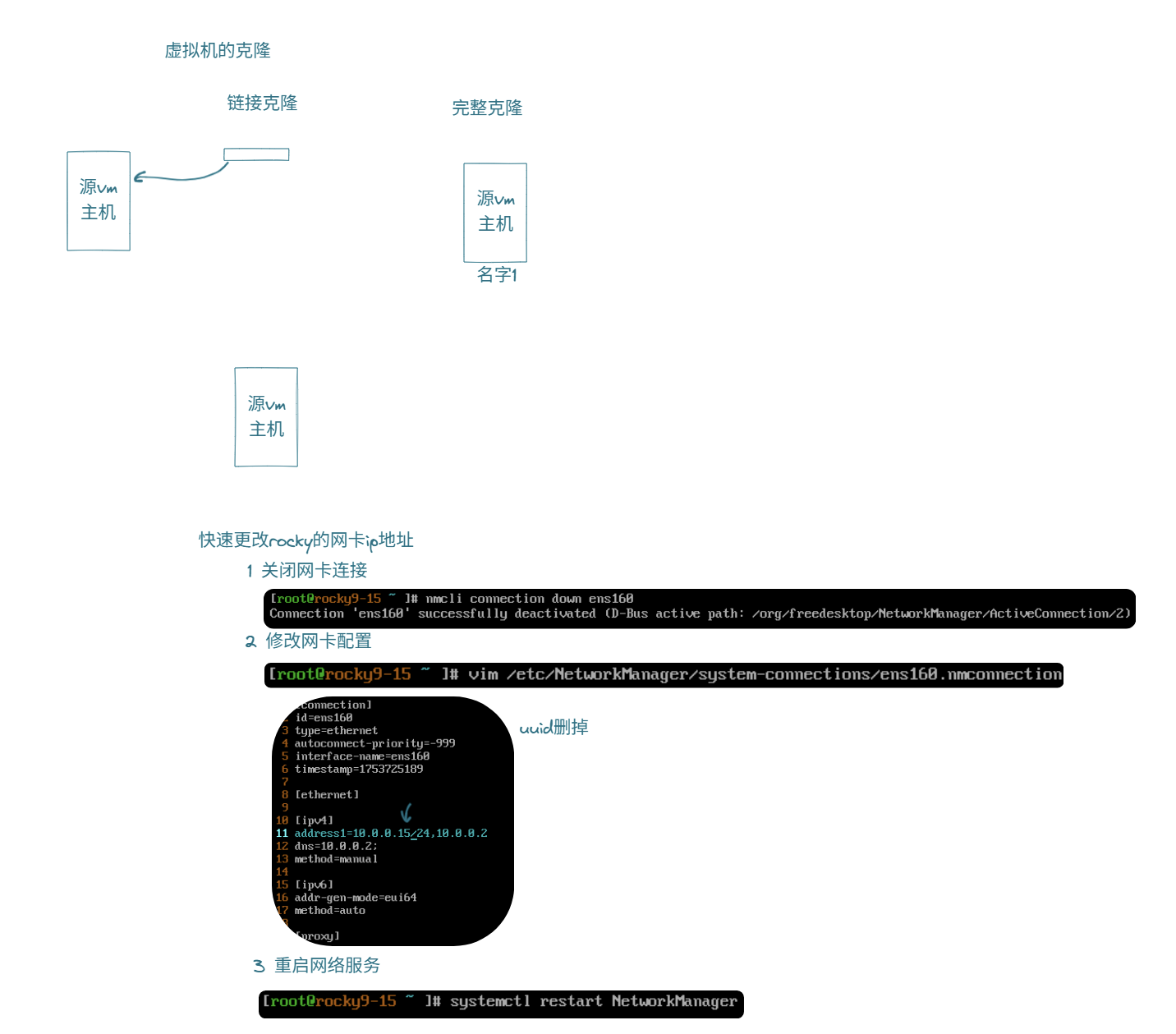
要改MAC地址,随机生成一个
7.8 自建yum仓库
yum仓库搭建:
- web环境
- 软件文件
- repodata
搭建web环境
yum install -y httpd
mkdir /etc/httpd/bak
ls /etc/httpd/conf.d/
mv /etc/httpd/conf.d/* /etc/httpd/bak -- 先把东西全部移走,目前不学http
ls /etc/httpd/conf.d/
systemctl stop firewalld.service -- 关闭防火墙
systemctl start httpd.service
systemctl status httpd
获取软件文件和建立repodata目录
yum reposync --repoid=nju-extras --download-metadata -p /var/www/html/ -- 从网上下载,速度慢
mkdir /cdrom -- 直接从本地下载
mount /dev/cdrom /cdrom
cp -r /cdrom/BaseOS /var/www/html;
cd /var/www/html/
mkdir BaseOS
mv Packages BaseOS/
mv repodata BaseOS/
cp -a /mnt/Appstream ./
对另一个主机进行客户端配置
cd /etc/yum.repo.d/
mkdir bak
mv rocky* bak
cp bak/rocky.repo localrepo.repo
vim localrepo.repo
修改baseurl=http://10.0.0.12/BaseOS/
添加AppStream
yum makecache
7.9 Ubuntu软件管理
类比方式来记忆:
rocky中: 配置文件所在 /etc/yum.repos.d/.repo
yum仓库中的repodata
yum仓库中的Packages
ubuntu中: 配置文件所在 /etc/apt/sources.list
ubuntu中的dists
ubuntu中的pool
配置文件格式
deb 二进制包
deb-src 源码
先挂载文件:
mount /dev/cdrom /mnt
ls /mnt
进去之后发现有dists和pool
cd /etc/apt/
cat sources.list
发现文件被移动到了另一个里
cat source.list.d/ubuntu.sources -- 找到版本noble
mkdir bak/
mv source.list.d/ubuntu.sources* bak/
去镜像库里找新配置,给ubuntu加速一下

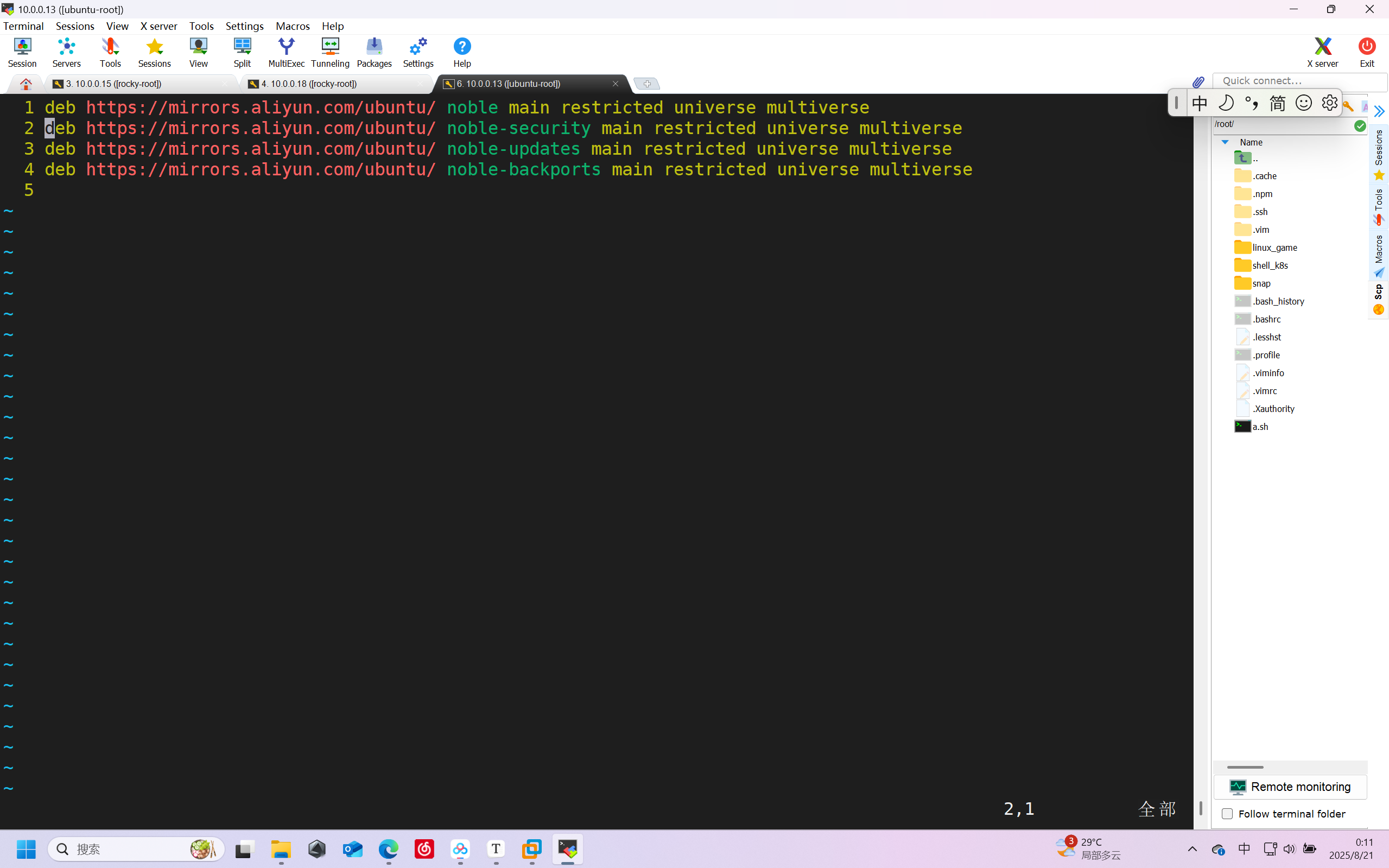
只保留二进制包
此时,就从aliyun里把ubuntu的源定制好了
再来定制清华源

点击问号,就能找到配置
删除不需要的
进行apt update
进行总结:
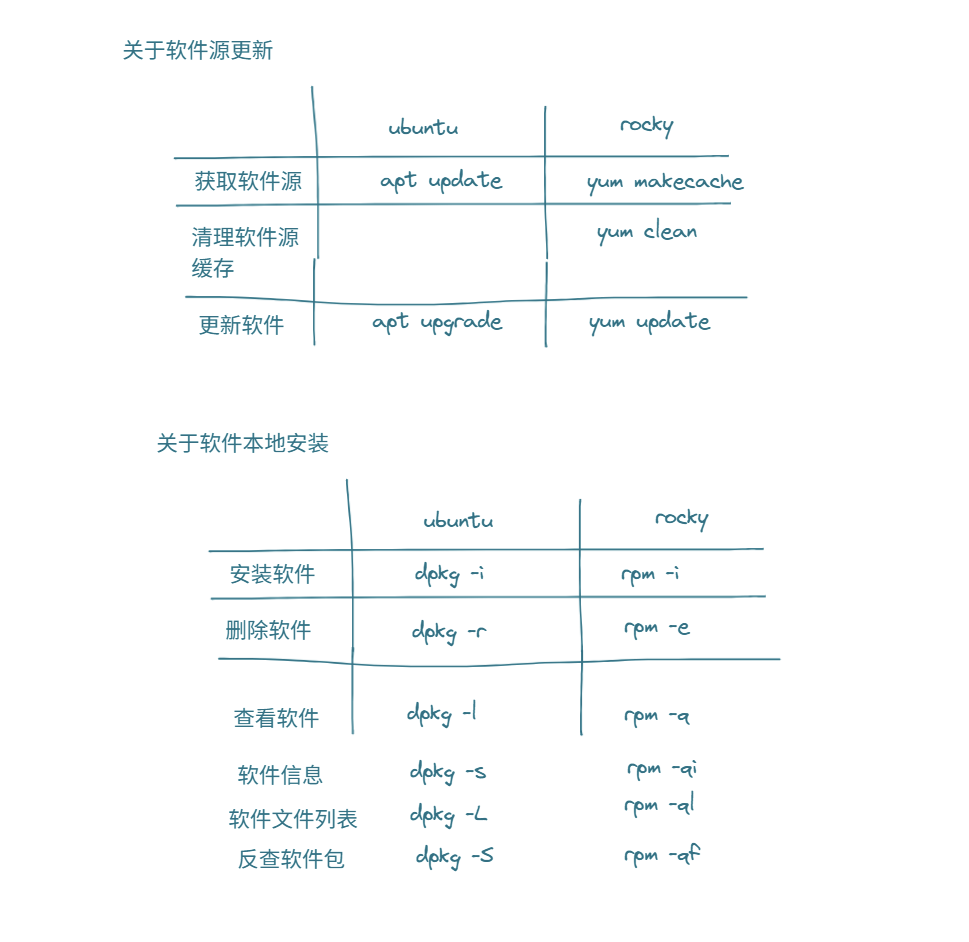
7.10 dpkg包管理器(类比rpm)
dpkg -V -- 查看包是否被安装
dpkg -i -- 安装包文件
dpkg -r -- 删除文件(注意清理不干净)
dpkg -l -- 查看包的状态
7.11 apt命令用法

apt purge -- 才能真正卸载文件干净
apt update = yum makecache -- 建立缓存
apt list --installed --查看已安装的包
7.12 源码编译

转移文件,也就是安装文件
以上图片内的逻辑需要重点记忆:
- 拿到源代码后,通过wget下载,得到类似于/data/softs中.tar.gz的文件,通过tar xf命令解压
- 接下来进行configure配置(也可以理解为写剧本)(我需要开启或者关闭什么功能,需要将文件放在什么目录里(可以用–prefix来制指定)),执行完configure后会生成makefiles文件,也就是剧本已经写好
- make命令依据剧本里的逻辑进行操作(把剧演下来),生成一大堆文件,这些文件放在临时目录里
- 进行转移(make install)
接下来是以上操作的实操:
wget动作之前已经操作过了,下载下来的文件放在/data/softs里
cd /data/softs
tar xf nginx-1.29.0.tar.gz -- 进行解压动作
cd nginx-1.29.0/
ls
netstat -tnulp -- 查看一下目标nginx端口80有没有被占用,发现httpd占用了
yum autoremove httpd -- 移除掉
ls /var/www/html
rm -rf /var/www/html/* -- 全部删除
ls -- 发现有readme,按照指令操作(Building from source)
默认的configure和make都有分散的目录,我想要集中下载,因此需要定制
找到绿色的config
./config --help
./configure --prefix=/lnmp/nginx --with-http_ssl_module
配置完了,导演剧本已经写好
make -- 拍一下电视剧
make install --转移文件到该去的地方
7.13 打包压缩

上面这几个必须得会
解压unzip文件的方法:
unzip -d 路径 -- 解压文件到指定目录
第八天 Linux磁盘存储和文件系统管理
8.1 磁盘存储
硬盘分为机械硬盘和固态硬盘
此处的磁盘存储主要是偏os层面的分区
linux中的设备文件可以分为三个设备类型
- 字符设备文件(键盘)
- 块设备文件(u盘)
- 网络设备文件(网卡)
磁盘设备的设备文件命名
SAS, SATA, SCSI等设备的设备文件命名为/dev/sda,/dev/sdb,/dev/sdc
nvme协议硬盘设备的设备文件命名为/dev/nvme0n1,/dev/nvme0n2,/dev/nvme0n3
虚拟磁盘的设备文件命名为/dev/vda,/dev/vdb,/dev/xvda
在主机中添加硬盘,重新启动后会找不到操作系统的的位置,是为什么?
- 操作系统在启动的时候,会经过BIOS(小程序,基本输入输出系统 ,引导系统在哪个盘中)
- 默认先去SCSI去找,但我们操作系统放在nvme盘里面了,按照顺序排在后面,因此找不到
解决方法
- 右击虚拟机,去电源里的“打开电源时进入固件”进入BIOS
- 去boot里按加号把nvme移上去
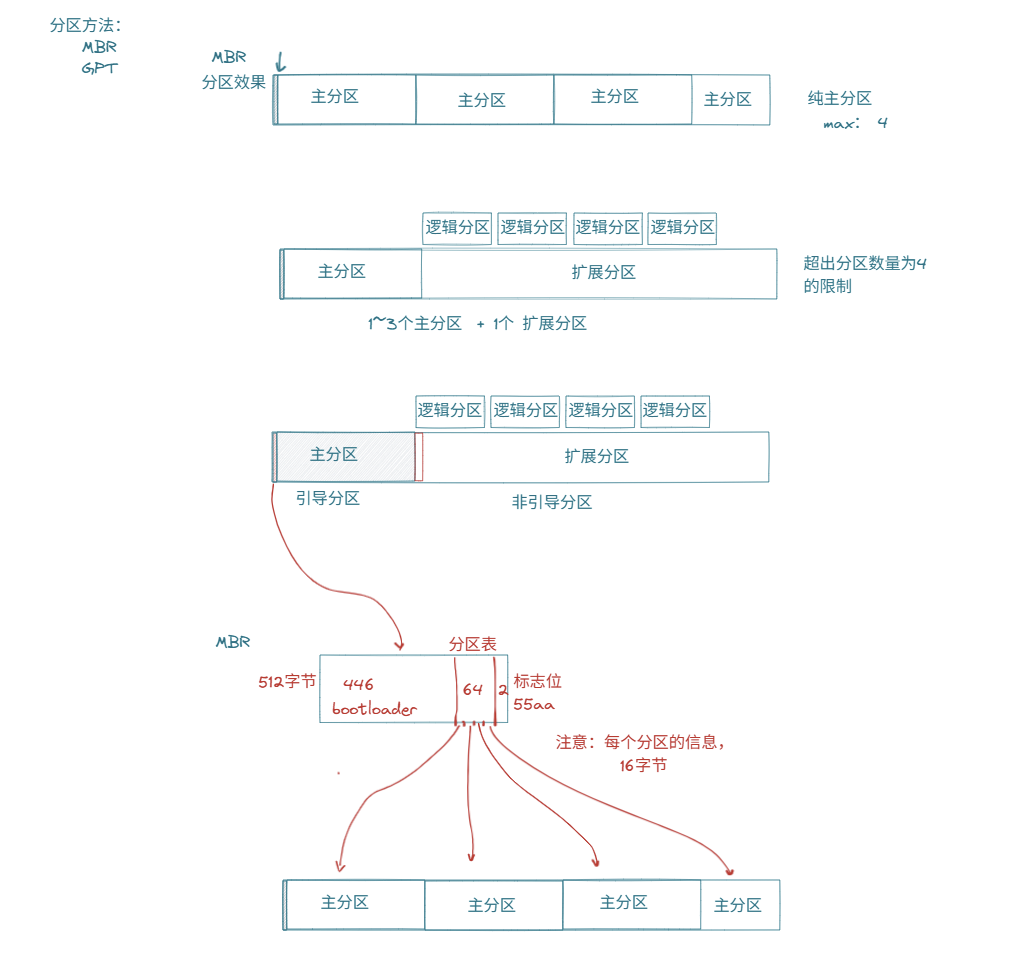
重要内容:MBR
MBR主要应用于磁盘的引导记录和分区管理
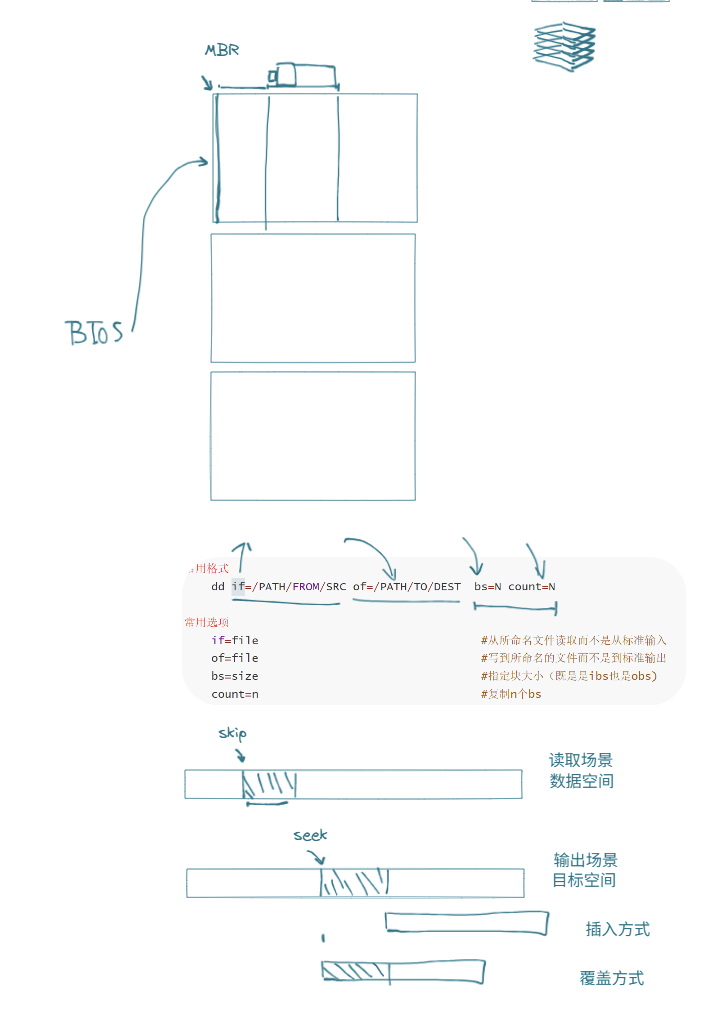
- 假设开机后主机内有三块盘,BIOS进入存储盘中,MBR充当引路人,是整块盘中最开始的起始位置,帮助BIOS找到操作系统所在的位置
lsblk -- 查看块设备(硬盘U盘等)
lsblk -f -- 查看除上面以外的UUID和文件系统类型
重要命令fdisk
默认情况下,fdisk可以看所有的盘的存储信息
fdisk -l -- 看全部的磁盘存储信息
fdisk -l /dev/sda -- 看具体磁盘信息
其他磁盘命令:
df -h -- 以方便人类阅读的方式显查看文件系统
du -sh file -- 查看目录的大小
dd if=/path/from/src of=/path/to/dest bs=N count=N -- 文件系统定制(操作磁盘分区),类似cp,但cp更日常,dd更底层
if -- 从哪里提取数据
of -- 准备把数据放到哪里
bs -- 传输数据的单位是什么(1M表示以1M为单位传输)
count -- 一共传多少块
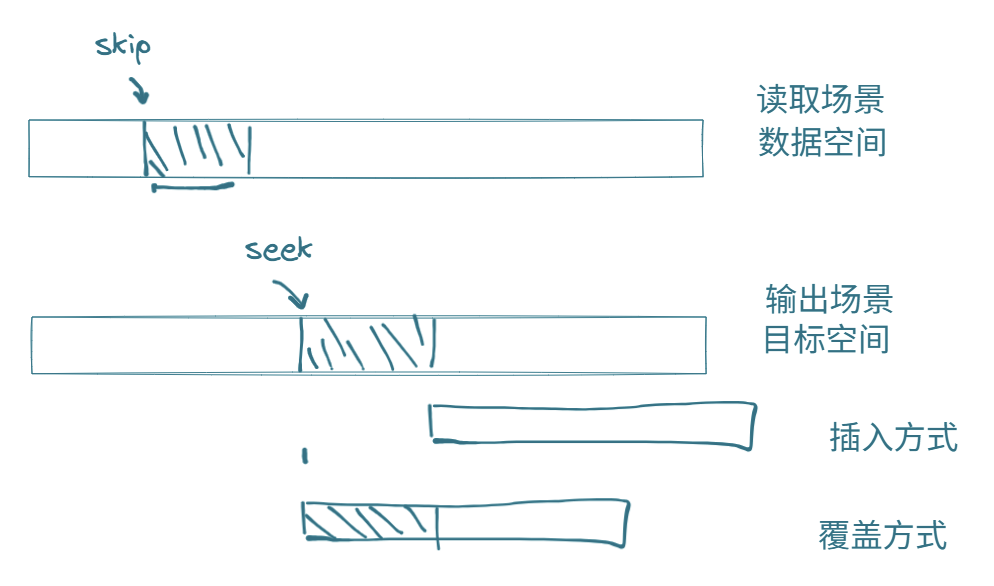
/dev/null --黑洞文件,放进去就拿不回来了,但dev/null里面放东西就再也拿不回来了
/dev/zero -- 可以无数次往外输出0
实践操作:
dd if=/dev/zero of=1M.file bs=1M count=1
ll -h 1M.file -- -h一般都是说人话的意思

以上为特殊场景
8.2 存储管理
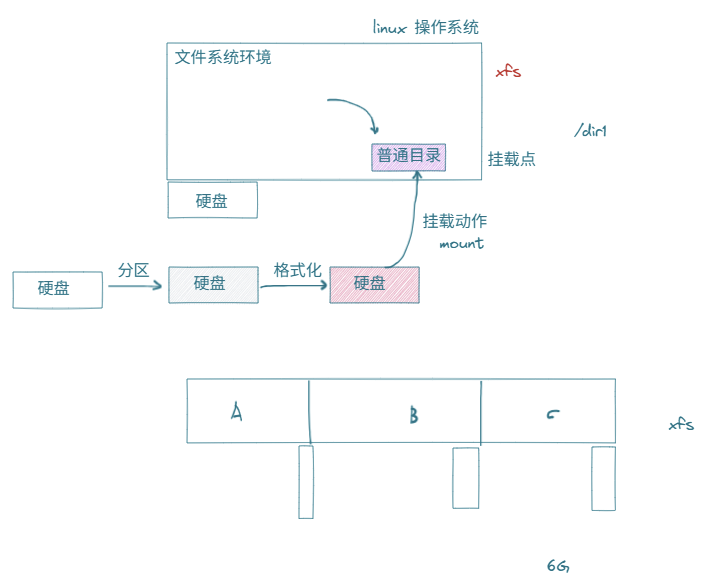
场景:原硬盘空间不够用了,需要买新硬盘
- 拿到硬盘后,进行分区
- 硬盘进行文件系统格式化(使其具有文件系统的能力,可以往里面存数据)
- 在文件系统环境中
- 提供一个普通目录,为新硬盘提供入口。一旦连接,这个目录就变成了挂载点,而硬盘与文件对接的动作叫做挂载,命令是mount
-
分区分为引导分区和非引导分区,扩展分区中有逻辑分区
-
在MBR风格的分区场景下,能够支持最多4个主分区或3个主分区+1个扩展分区
MBR分区的标识是dos(rocky默认分区),GPT的标识是gpt(Ubuntu默认分区)
8.2.1 MBR具体解析
现在说的是一小块引导区域的结构,MBR占一个扇区,512字节
- 和主引导程序有关:bootloader 446字节
- 中间64字节是分区表
- 最后2字节是标志位 55aa(有的话就是曾经有过分区)
hexdump -n 512 -Cv /dev/sda
8.2.2 fdisk分区
fdisk -l 设备名 -- 查看分区信息
fdisk 设备名 -- 管理分区,进入终端操作


操作系统的定制:
手动分区,创建新的分区
上午的内容整体梳理一下
我们需要增加新硬盘,先分区(fdisk),后格式化(下午),再挂载(下午)到目录上
查看磁盘分区:fdisk -l
查看文件系统信息:df -h
查看目录大小:du -sh
查看块设备:lsblk
8.3 挂载动作操作
格式化的命令:
mkfs -t ext4 /dev/sda = mkfs.ext4 /dev/sda -- 把/dev/sda格式化为ext4
blk命令:
blkid -- 查看UUID -- 格式化后留下的唯一的标识
接下来进行实操,对分区硬盘进行格式化
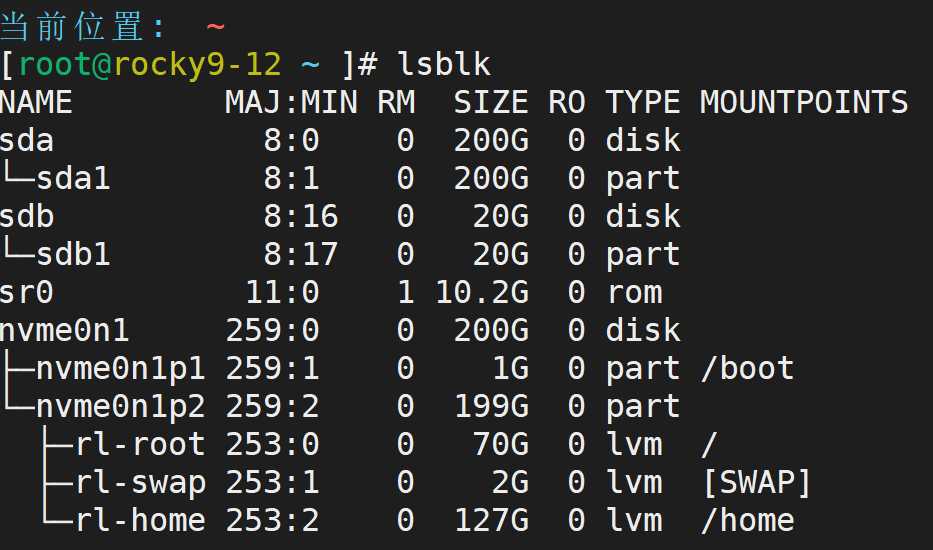
准备两个分过区的磁盘(sda1和sdb1)
mkfs.ext4 /dev/sda1
mkfs.xfs /dev/sdb1
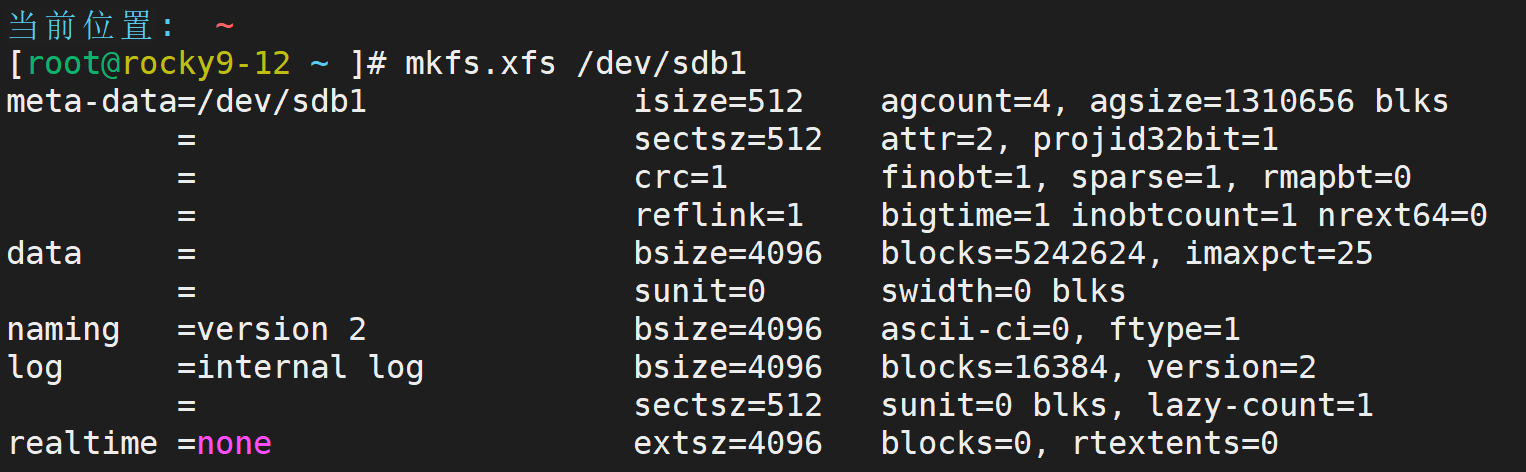
查看就用blkid
接下来,我们进行挂载命令
两条命令:
mount 设备 挂载点 -- 进行挂载
umount 设备 挂载点 -- 取消挂载
mount /dev/sda1 /dir3
mount /dev/sdb1 /dir4
mount -- 查看挂载状态
umount /dir3
umount /dir4
挂载规则:
- 一个挂载点同一时间只能挂载一个设备
- 一个挂载点同一时间挂载了多个设备,只能看到最后一个设备
- 一个设备可以同时挂载到多个挂载点
- 通常挂载点一般是已存在的空目录
但是,mount的劣势是临时有效,也就是下次重启时会失效,想要解决这个问题,我们要用到fstab命令
fstab是一个文件,在/etc/fstab
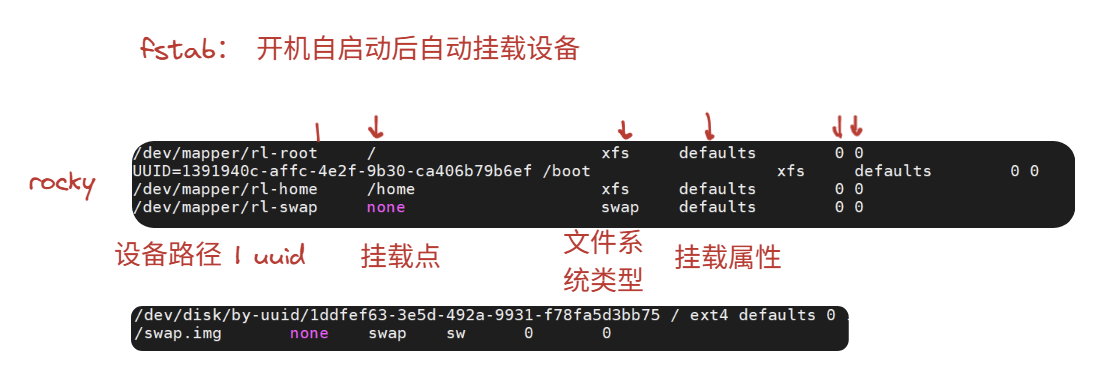
想要修改,通过vim
8.4 RAID
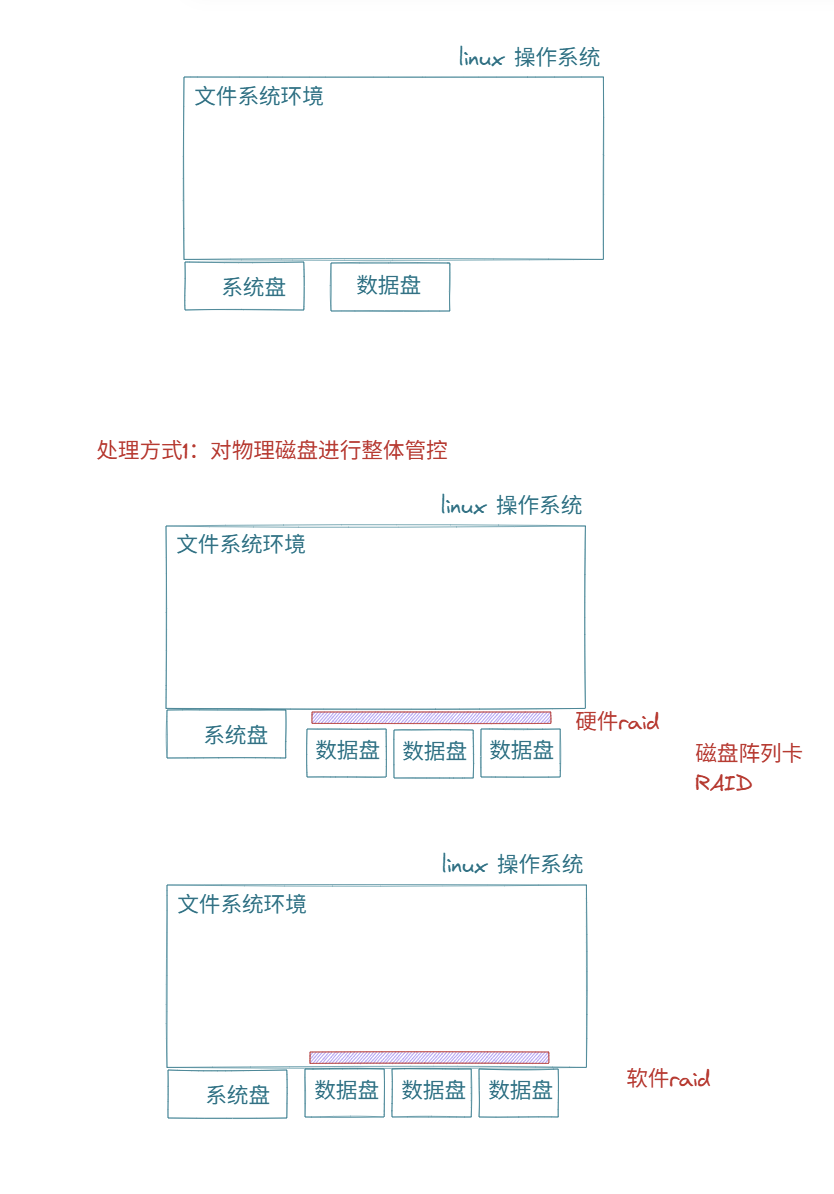
如果数据盘损坏了,我们有办法解决吗?
有两个办法
第一个办法:使用磁盘阵列卡RAID对物理盘进行管控


RAID0: 把所有数据分块后,放到两个盘里,提高效率
RAID1: 把数据分块后,提供一份备份,不担心数据损坏
RAID5: 有奇偶校验,结合两个原始副本,重现损坏数据
8.5 lvm(逻辑卷管理器)
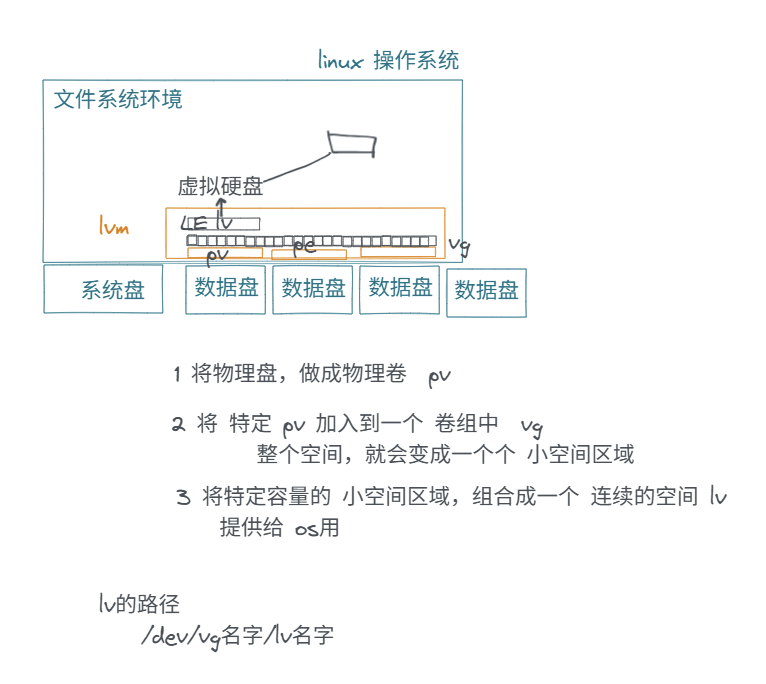
pvs,lvs,vgs -- 查看卷组信息
pvdisplay,lvdisplay,vgdislpay
lvscan -- 查看lv总体信息
实践操作过程:
先创建pv: pvcreate /dev/sda1
pv有了,可以创建vg了: vgcreate -s 16M testvg /dev/sda1
vg有了,再创建lv: lvcreate -l 100 -n lv1 testvg -- 从testvg创建lv1,大小为100个PE
lvcreate -L 5G -n lv2 testvg -- 从testvg中创建lv2,大小为5G
mkdir /mount/lvm -p
mkfs.ext4 /dev/testvg/lv1 -- 格式化lv,使其具有文件系统的能力
接下来就可以进行挂载了
mount /dev/testvg/lv1 /mount/lvm
8.5.1 扩展逻辑卷
先把lv增加,再把文件系统容量增加
lvextend -L +1G /dev/testvg/lv1
resize2fs /dev/testvg/lv1
8.5.2 缩减逻辑卷
缩减影响较大,需要先取消挂载,检查一下文件有没有损坏,先缩
umount /dev/tsetvg/lv1
df -h
resize2fs /dev/testvg/lv1 3G
删除时,从上往下一一删除
8.5.3 逻辑卷快照
快照就是数据备份,但是和VMware里面的快照不一样,这里的快照是一次性的。
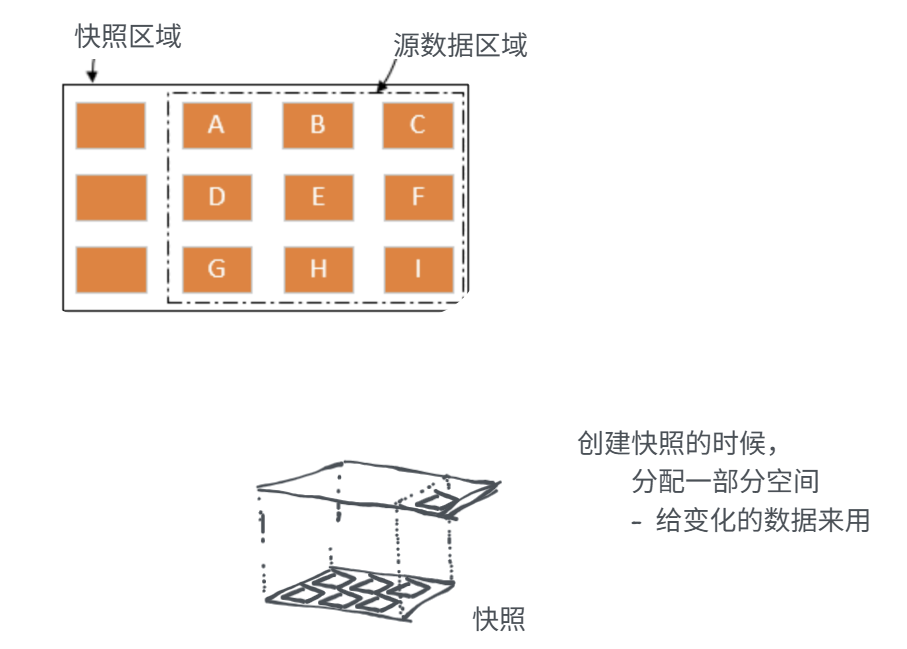
原来的数据不变,发生改变时,复制一份新数据到新空间里
什么时候要用了,把下面的直接拿就可以了
快照就是lv,只是用的-s
快照与原逻辑卷必须位于同一个卷组(VG)中
具体内容参照pdf
cp /etc/fstab /mount/lvm
mkdir /mount/lvm_snapshot
lvcreate -n lv1_snapshot -s -L 100M -p r /dev/testvg/lv1
还原快照需要先umount所有挂载
lvconvert --merge /dev/testvg/lv1_snapshot
第九天 Shell编程基础
9.1 概述
需要把基础打牢,即可进阶
Shell是解释语言
Shell脚本:把执行成功的命令放到一个脚本里,自动化运行
mkdir scripts
cd scripts/
vim get_netinfo.sh
# 获取ip地址信息
ifconfig eth0 | grep -w inet | awk '{print $2}' | xargs echo "IP: "
# 获取掩码地址信息
ifconfig eth0 | grep -w inet | awk '{print $4}' | xargs echo "NetMask: "
# 获取广播地址信息
ifconfig eth0 | grep -w inet | awk '{print $6}' | xargs echo "Broadcast: "
# 获取MAC地址信息
ifconfig eth0 | grep ether | awk '{print $2}' | xargs echo "MAC Address: "

- 脚本执行有很多种方法,推荐使用/bin/bash来执行
- 方法二的坏处是可能遇到权限问题的限制
/bin/bash -x -- 查看脚本运行的具体流程
-
脚本命名要有意义,文件后缀是
.sh -
脚本文件首行是而且必须是脚本解释器
#!/bin/bash -
脚本文件解释器后面要有脚本的基本信息等内容
- 脚本文件中尽量不用中文注释;
- 尽量用英文注释,防止本机或切换系统环境后中文乱码的困扰
- 常见的注释信息:脚本名称、脚本功能描述、脚本版本、脚本作者、联系方式等
-
脚本文件常见执行方式:
bash 脚本名 -
脚本内容执行:从上到下,依次执行
-
代码书写优秀习惯;
- 成对内容的一次性写出来,防止遗漏。
如:()、{}、[]、''、``、“” []中括号两端要有空格,书写时即可留出空格[],然后再退格书写内容。- 流程控制语句一次性书写完,再添加内容
- 成对内容的一次性写出来,防止遗漏。
-
通过缩进让代码易读:(即该有空格的地方就要有空格)
9.2 Shell变量
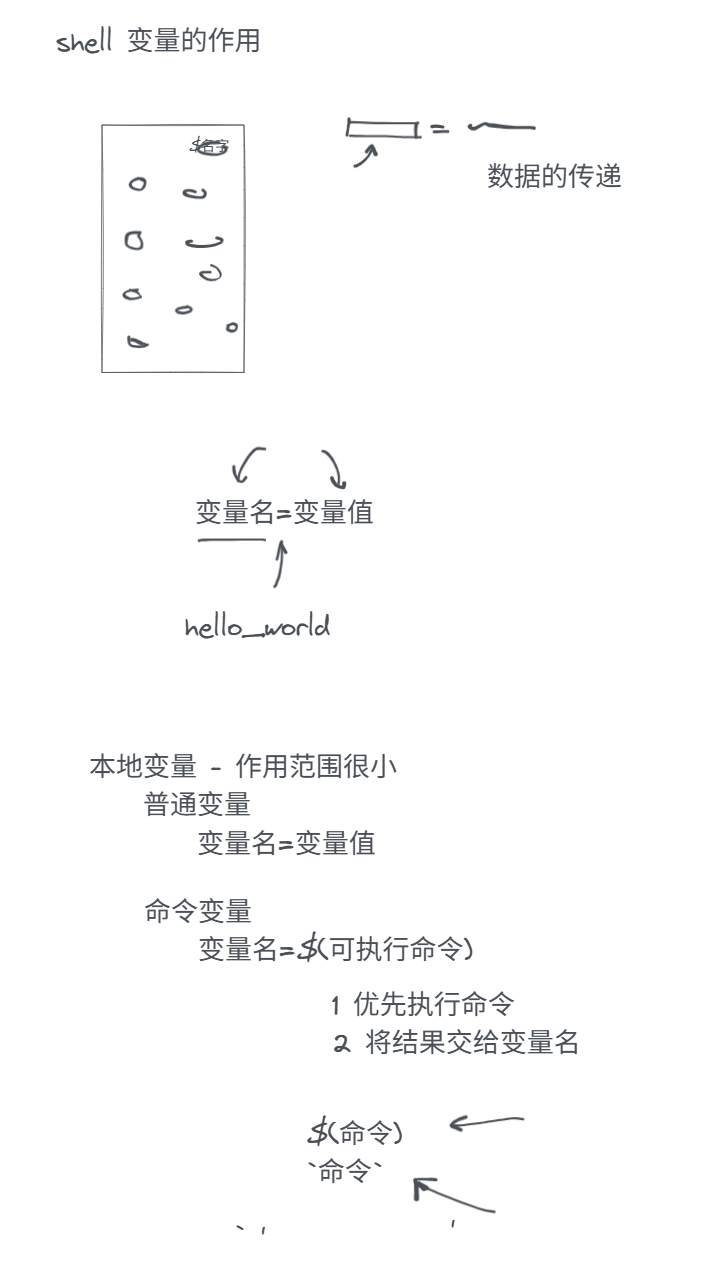
变量好处:替代
常见变量类型:本地变量、全局变量、shell内置变量
-
本地变量:普通变量、命令变量
-
普通变量:
变量名=变量值作用范围仅仅是一个终端

name=rxliang echo $name dan='dan-$name' 输出的就是dan-$name 类似喝醉了就在街上看谁就是谁,无法无天 shuang="shuang-$name" 输出的就是shuang-rxliang 假装醉了,看到帽子叔叔还是认识的(认识变量) -
命令变量:
addr=$(ifconfig ens160 | awk '/netm/{print $2}')
-
-
全局变量
env -- 查看全局变量 export 变量名 -- 把变量输出为全局变量 unset 变量名 -- 删除变量
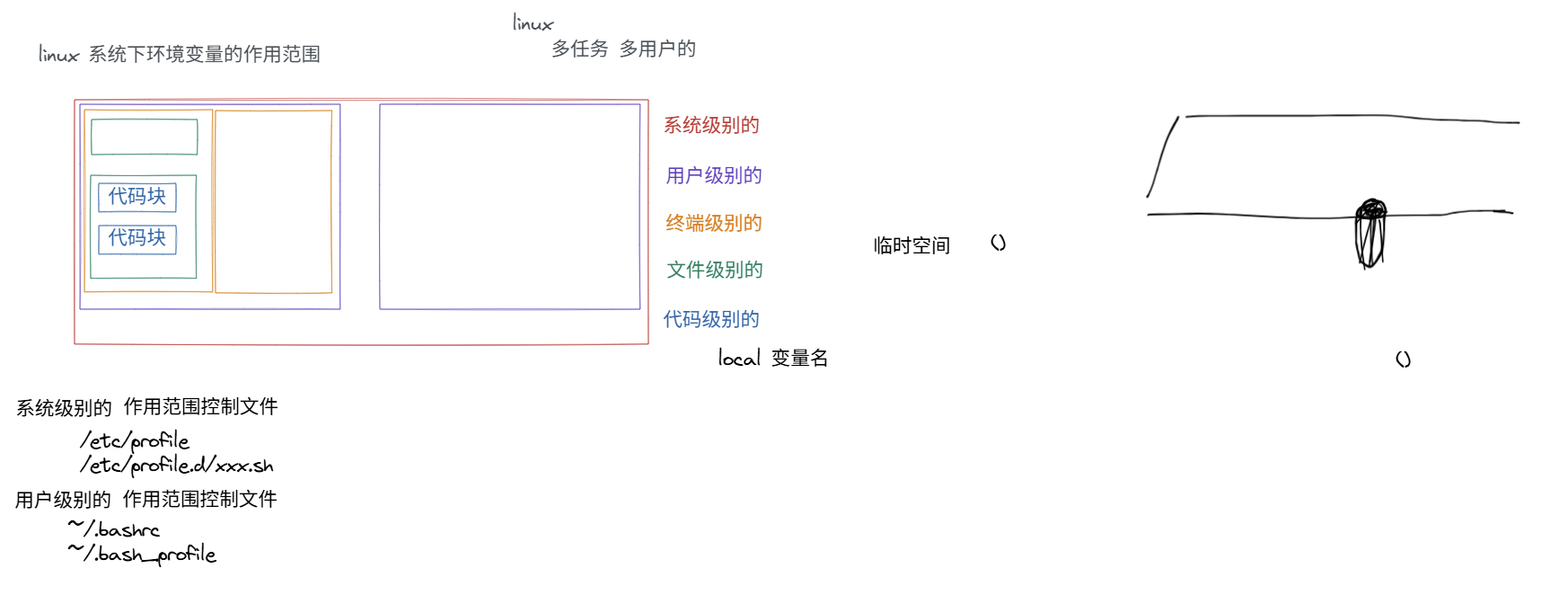
系统级别:/etc/profile 或 /etc/profile.d/ 变量放在这里,会立刻全局生效
创建/etc/profile.d/1.sh
输入NIHAO=xxx
exit后重新进入,在终端中输入echo $NIHAO 可以查看到xxx
su - rxliang
依旧可以看到
想让其失效
方法一:直接unset
方法二:先删除文件,后exit并重新登录
用户级别:~/.bashrc 或 ~/,bash_profile
作用范围:跨终端,但不跨用户
export:作用是,修饰过的环境变量有家族继承属性(放在文件级别,代码级别也能用)
举例:
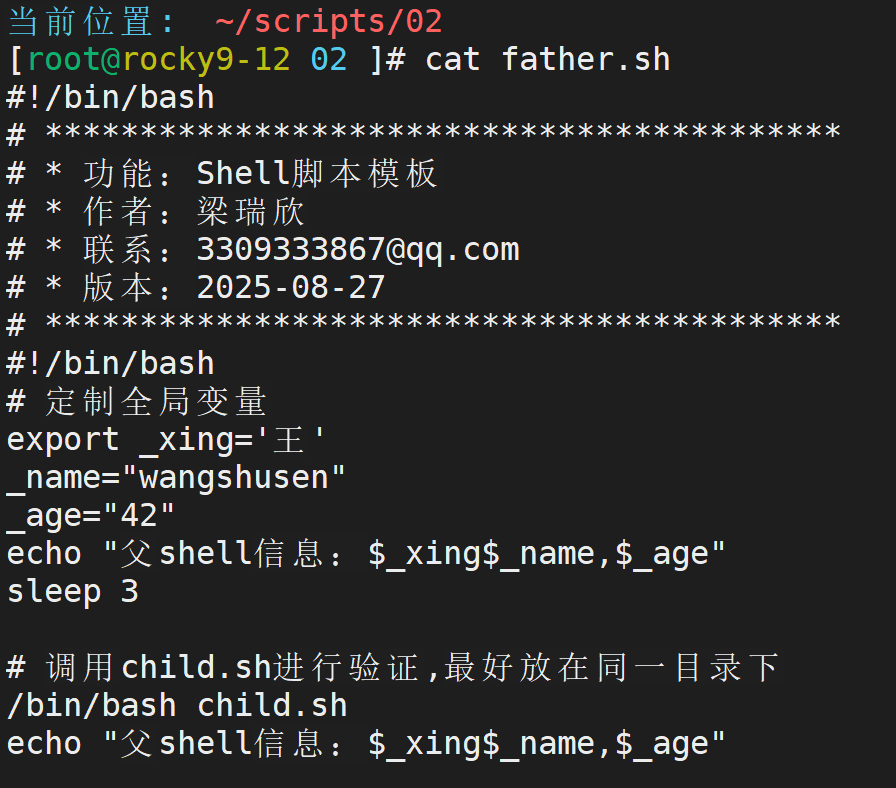
定制父脚本
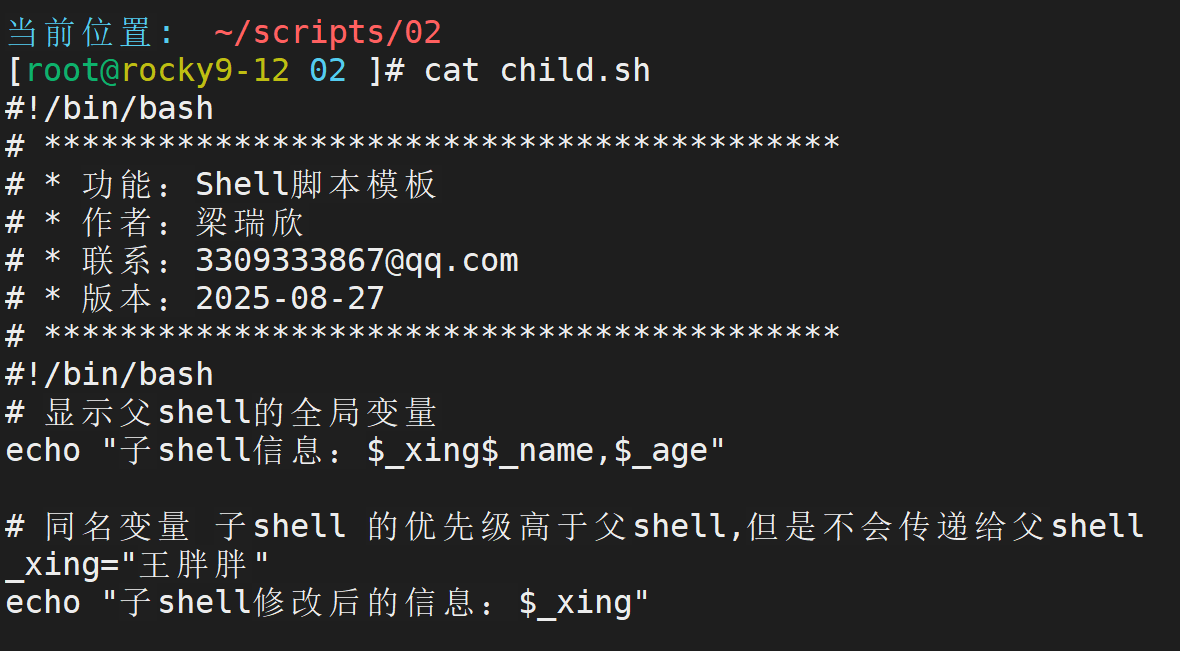
定制子脚本

执行结果
由此可以看出,加了export 的变量在子脚本中依然可以使用,但是不加却只能在自己的脚本中使用
-
内置变量(脚本相关)

echo $? 命令执行有没有成功?(成功为0,不成功非0,具体是什么数字不重要)
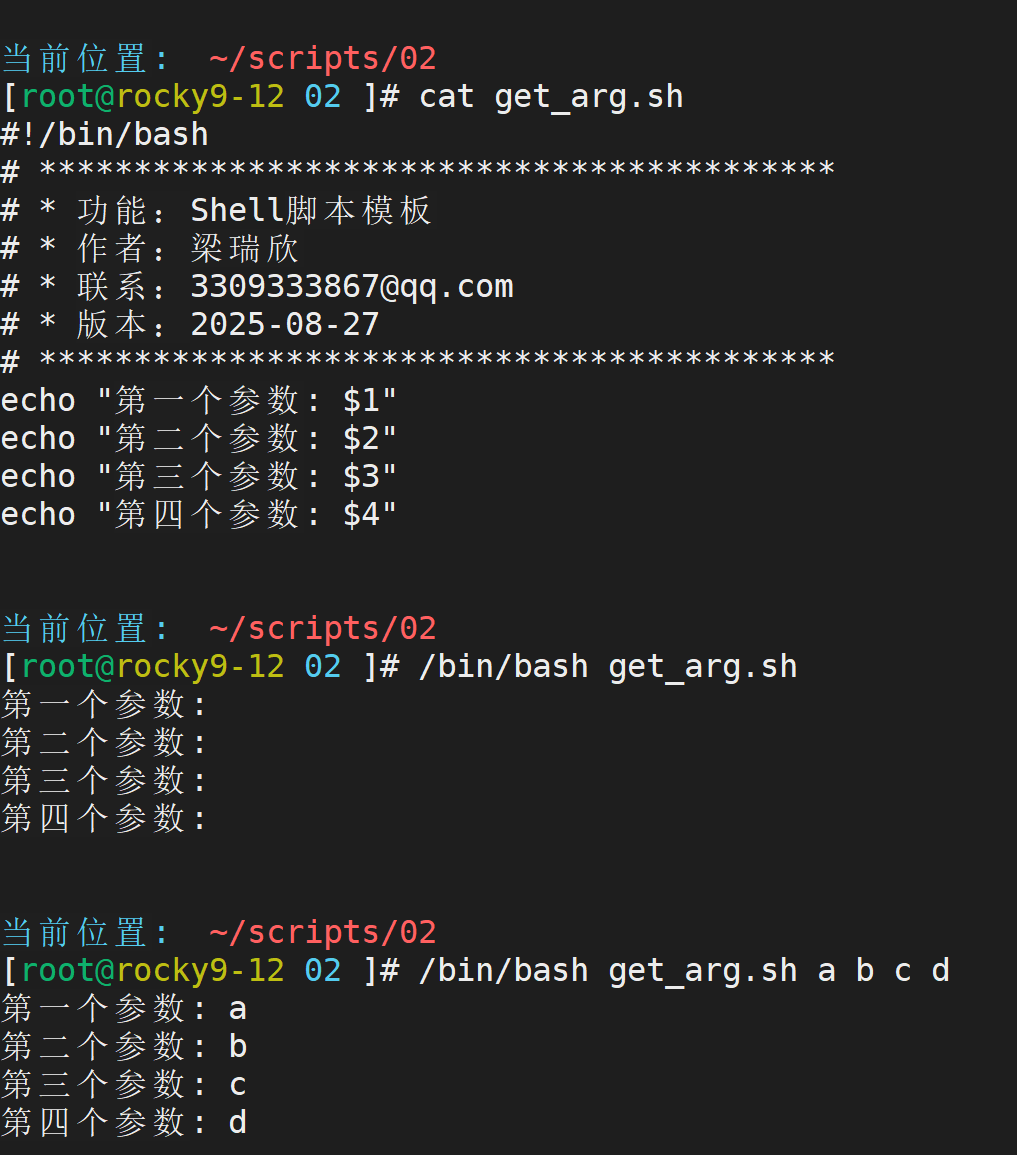
$n 参数之间用空格隔开
但是如果参数个数对不上,肯定不行,需要在运行前先查看参数个数
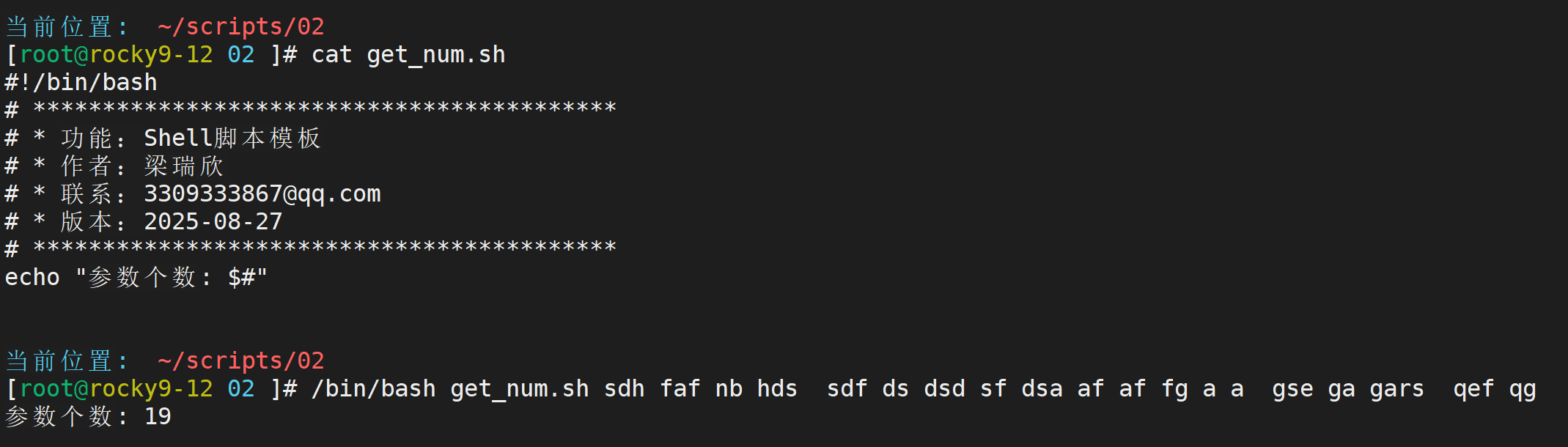
$# 计算参数个数
- 内置变量(字符串相关)

最标准的方式:"${file}"
"${file:0:5}" -- 上面的0,1,2是下标索引,表示字符所在位置
${变量名:-默认值} -- 变量a如果有内容,输出变量a,否则输出默认值
${变量名+默认值} -- 无论a是否有内容,都输出默认值
9.3 脚本交互
read -p -s "请输入密码:" passwd -- -s表示静默输入
echo $passwd
9.4 表达式
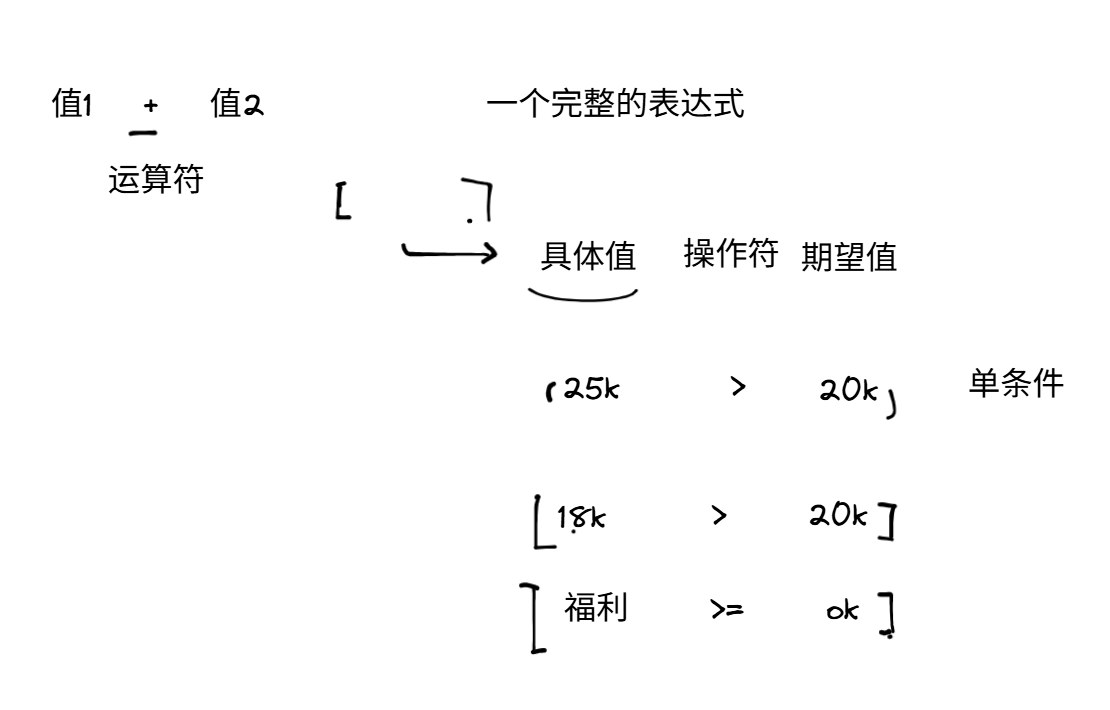
-
计算:
$[] -- 整数运算 let a=3+5 -- 整数运算 expr 4 + 6 -- 整数运算 echo "scale=2; 4 + 5"| bc -- 小数运算
let a++ -- a=a+1
let a+=2 -- a=a+2
echo $a
-
表达式:上面图片中有具体值和期望值的比较,我怎么知道有没有比较成功?

测试表达式
测试表达式
test aaa == aaa
echo $? -- 输出0,则条件成立;输出1,则条件不成立
(以上的方法不建议)
[ aaa == aaab] -- 有边界,比较好分辨,[ 在中间写 ]
echo $? -- 推荐使用
逻辑表达式

[ aaa == bbb ] && echo "成立" -- 左边不成立,输出1,右边同时不成立,不输出结果
[ aaa == aaa ] && echo "成立" -- 左边成立,输出0,右边同时成立,输出结果
[ aaa == bbb ] || echo "不成立" -- 左边不成立,输出1,右边成立,输出结果
[ aaa == aaa ] || echo "不成立" -- 左边成立,输出0,右边 不成立,不输出结果
[ aaa == aaa1 ] && echo "成立" || echo "不成立" -- 从左向右输出,1,1,0,因此最后输出结果是“不成立”
字符串表达式
str1 == str2
str1 != str2
-z str -- 空值判断,判断为空,与实际比较
-n "str" -- 判断非空,与实际比较
string=nihao
[ -z $string ]
echo $? -- 输出0
[ -n "$string1" ] -- 没有内容,不空
echo $? -- 输出1,判断错误
文件表达式
[ -f 文件名 ] && echo "exist" -- 判断文件是否存在,假设存在
[ -d 文件名 ] && echo "exist" -- 判断文件是否存在,假设不存在
[ -x 文件名 ] || chmod +x 文件名 -- 判断文件有没有执行权限,如果没有,加权限
[ -x 文件名 ] && chmod -x 文件名 -- 判断文件有没有执行权限,如果有,减权限
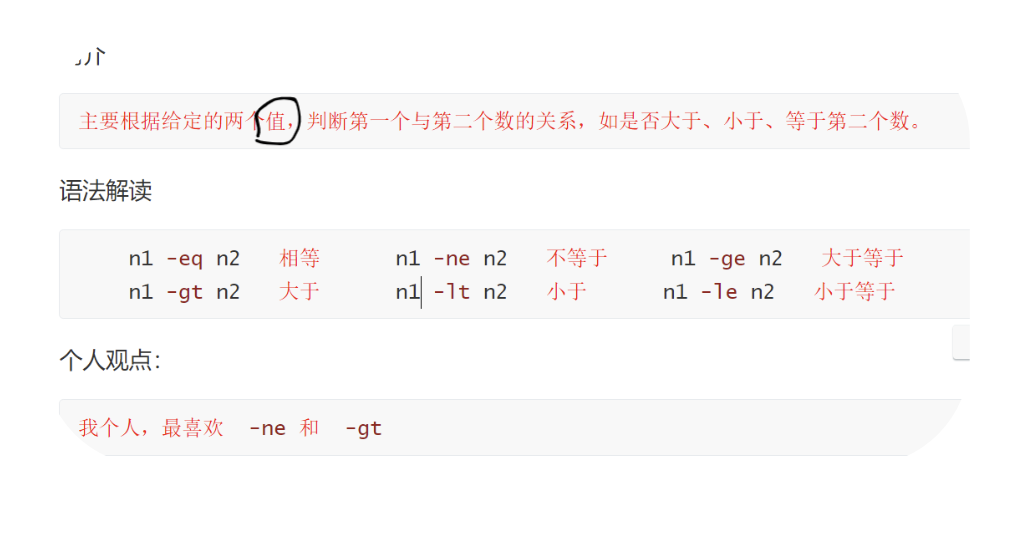
数字表达式
[ 3 -ne 5 ] -- not equal
echo $?
[ 3 -gt 5 ] -- greater than
echo $?
9.5 表达式进阶
多条件的表现样式
[ 条件1 && 条件2 ] or [ 条件1 ] && [ 条件2 ]
==
=~ -- 模糊查询
如果有正则表达式,就用[[ ]]
string=value
[[ $string == va* ]]
echo $? -- 得出0
[ ] : 简单表达式
[[ ]]: 扩展表达式

[]内进行多条件判断,中间要加-a 或 -o
user=root
passwd=123456
[ $user == "root" -a $passwd == "123456" ] -- 两个同时成立,整体成立
[ $user == "root" -o $passwd == "1234566666" ] -- 两个有一个成立,整体成立
9.6 数组实践
增删改查
- 增
array_name=(value0 value1 value2 value3)


- 删
unset array_name[index] -- 删除单个元素
unset array_name -- 删除整个数组
- 改
array[1]=666
- 查
declare | grep array
echo ${array[]}
扩展:

declare -A array_name-- 定制关联数组需要先声明
array_name=([]=xxx []=xxx)
9.7 分支逻辑
-
单分支if语句
只有一个条件,只有一个结果
-
双分支if语句
一个条件,两个输出
-
多分支if语句
多个条件,多个输出
但是一直要输入if很麻烦,可以用case来代替

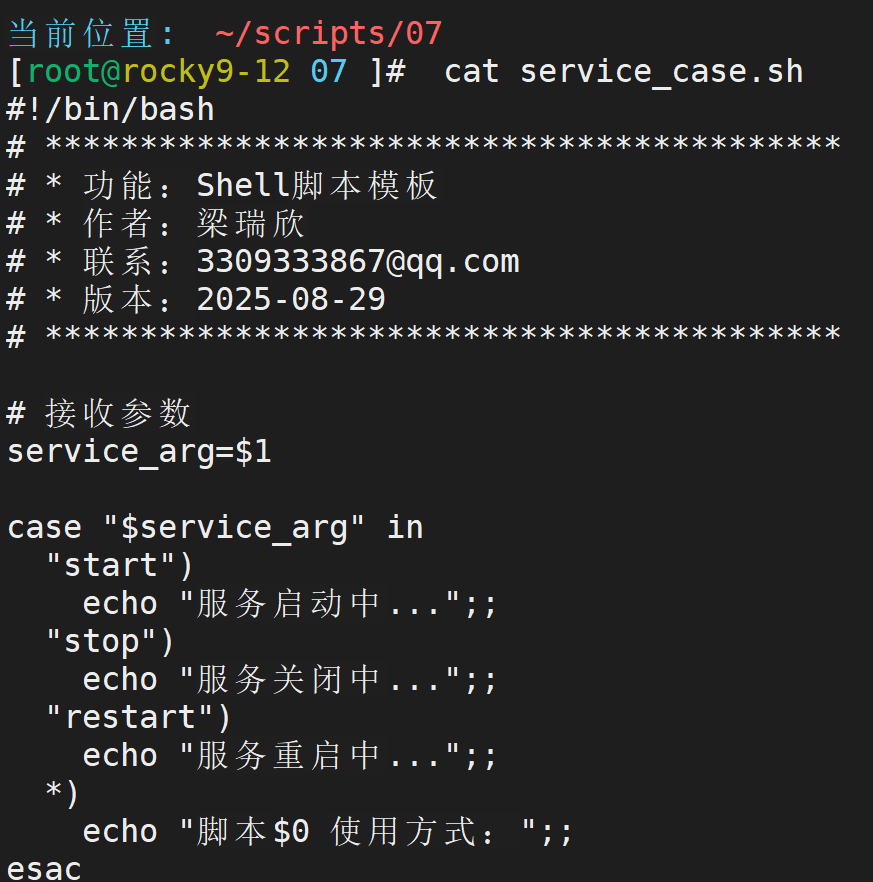
- 注意,*) 一定要放在最后,不然会覆盖掉后面的case
9.8 循环逻辑
结构:
关键字 [ ]
do
执行语句
done
-
for循环
for i in do done

















 1362
1362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









