






 本文介绍了使用Datalore进行K-means算法实现的过程,包括如何上传本地文件并调用数据,同时对比了Datalore与Jupyter Notebook的功能特性。
本文介绍了使用Datalore进行K-means算法实现的过程,包括如何上传本地文件并调用数据,同时对比了Datalore与Jupyter Notebook的功能特性。
前言
主要做大数据相关开发,今天突然想用python实现一下K-means算法。但是公司电脑没有python环境,索性装了anaconda3.8。发现多了一个机器学习相关开发工具叫datalore。刚上手感觉是jupyter notebook的的升级版,用着还挺好用的。登录账号以后还可以共享自己的项目,有点github内味了。(当然还是有很大不同的)
但是问题随之也来了,测试k-means算法需要用我本地的数据。datalore这东西比较新百度找了一圈没找到,自己研究了一下。
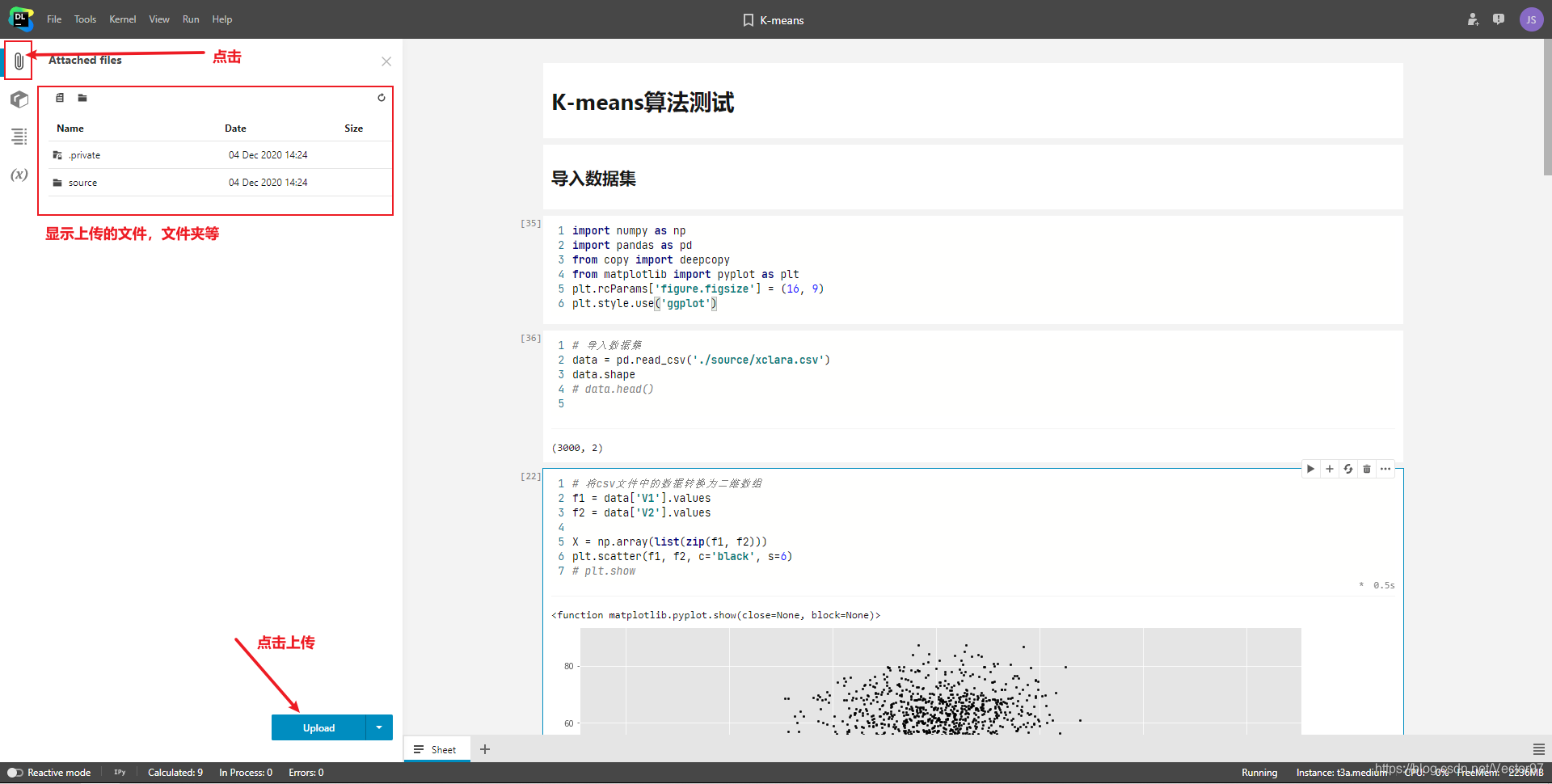
上传文件
方式一
这个web IDE主页面如下。想要将本地文件上传需要点击对应notebook右侧的三个点的菜单。
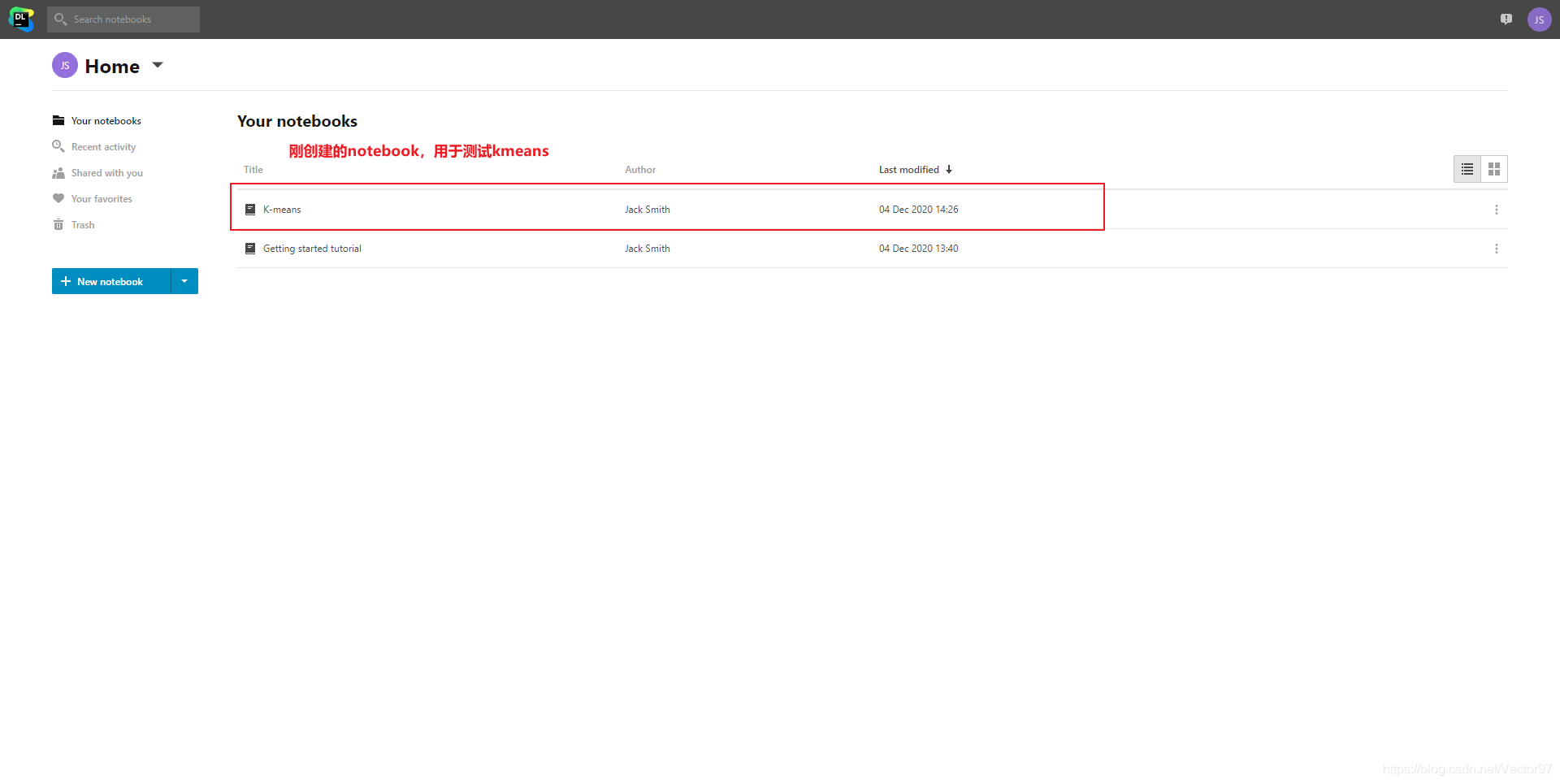
选择下面的attach file(如果要上传文件夹也点这个)
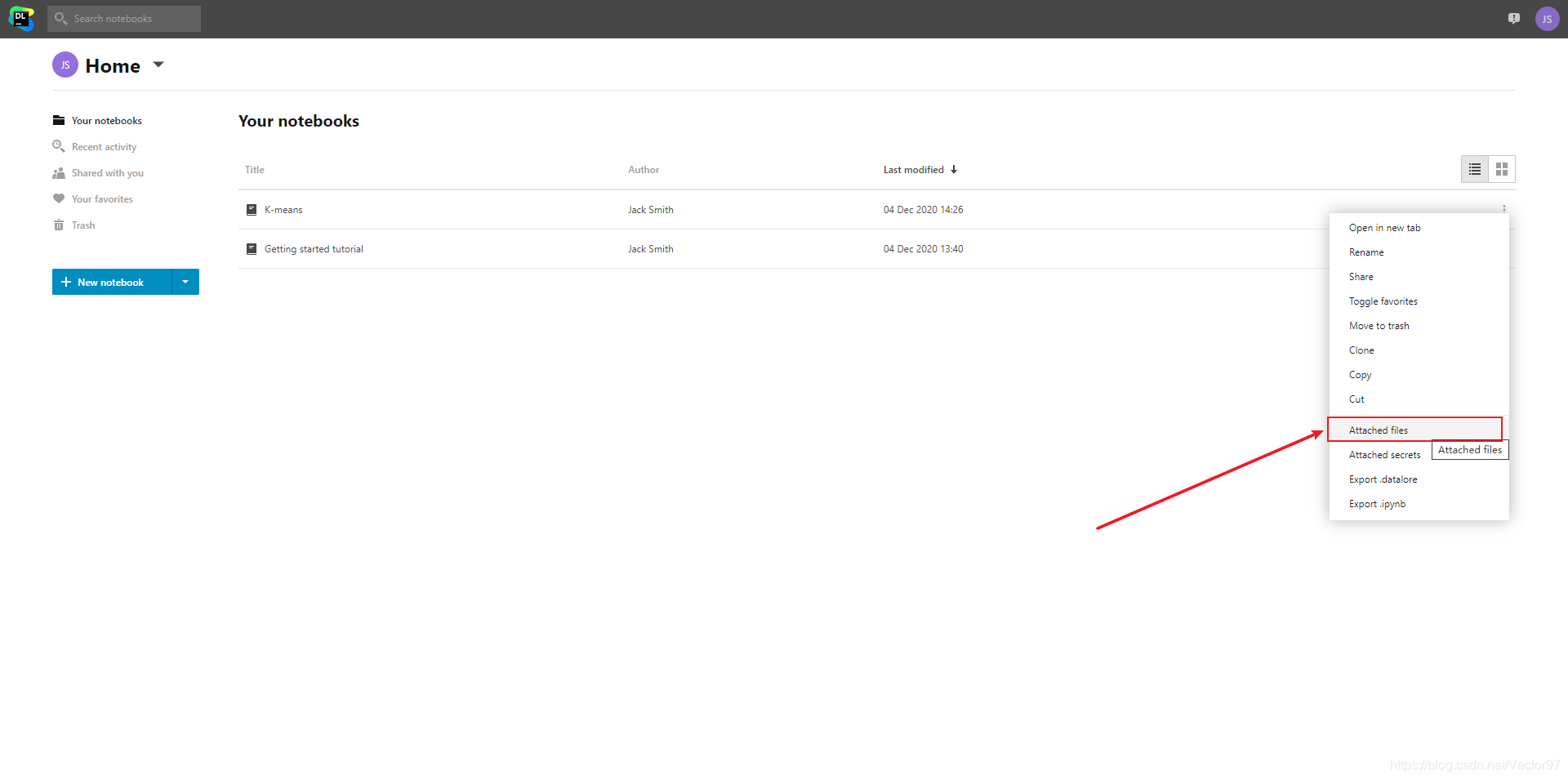
出现下面弹出,可以直接点击上传,也可以像我一样创建一个文件夹,将文件存储在对应的文件夹中
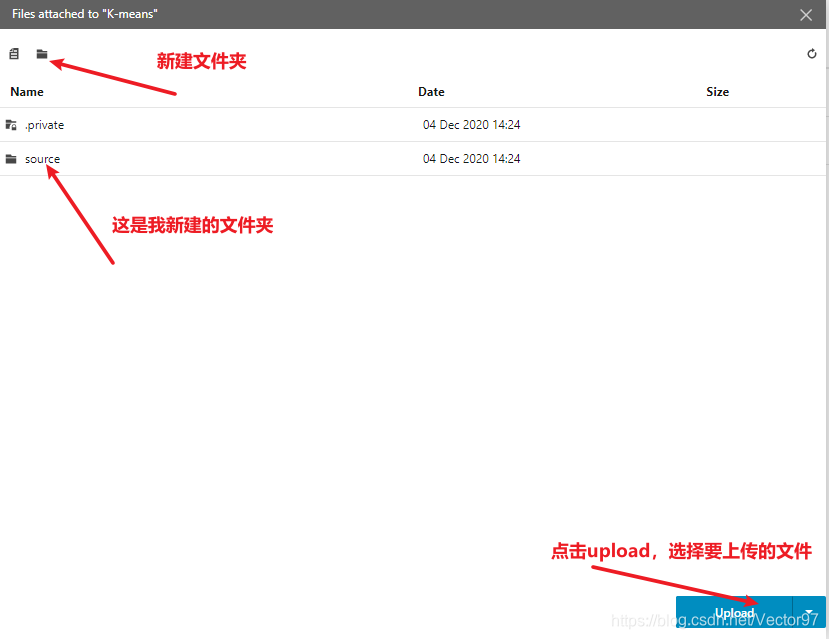
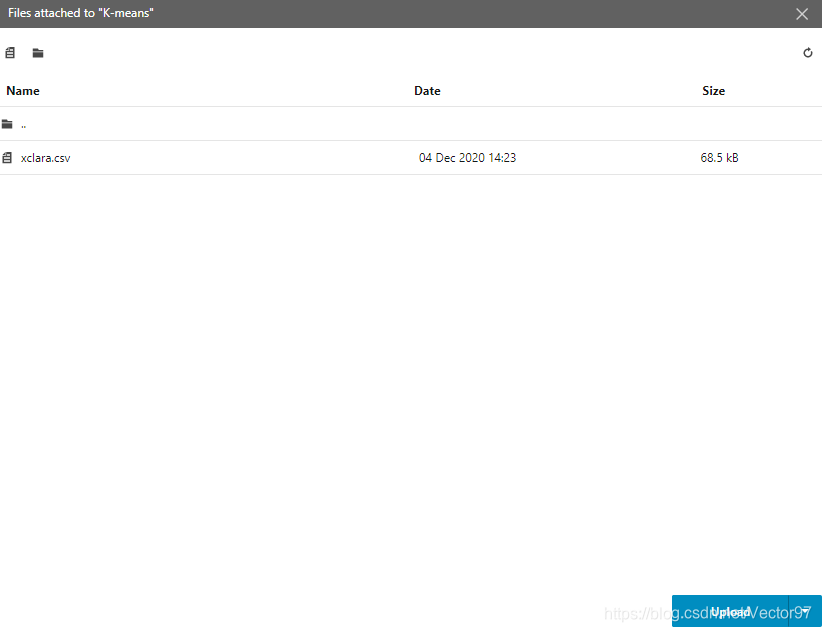
双击文件夹可以进入到文件夹中,下图是我上传的文件——一个csv数据文件
方式二
写完上面的方式以后发现了更简单的方式。。如下图
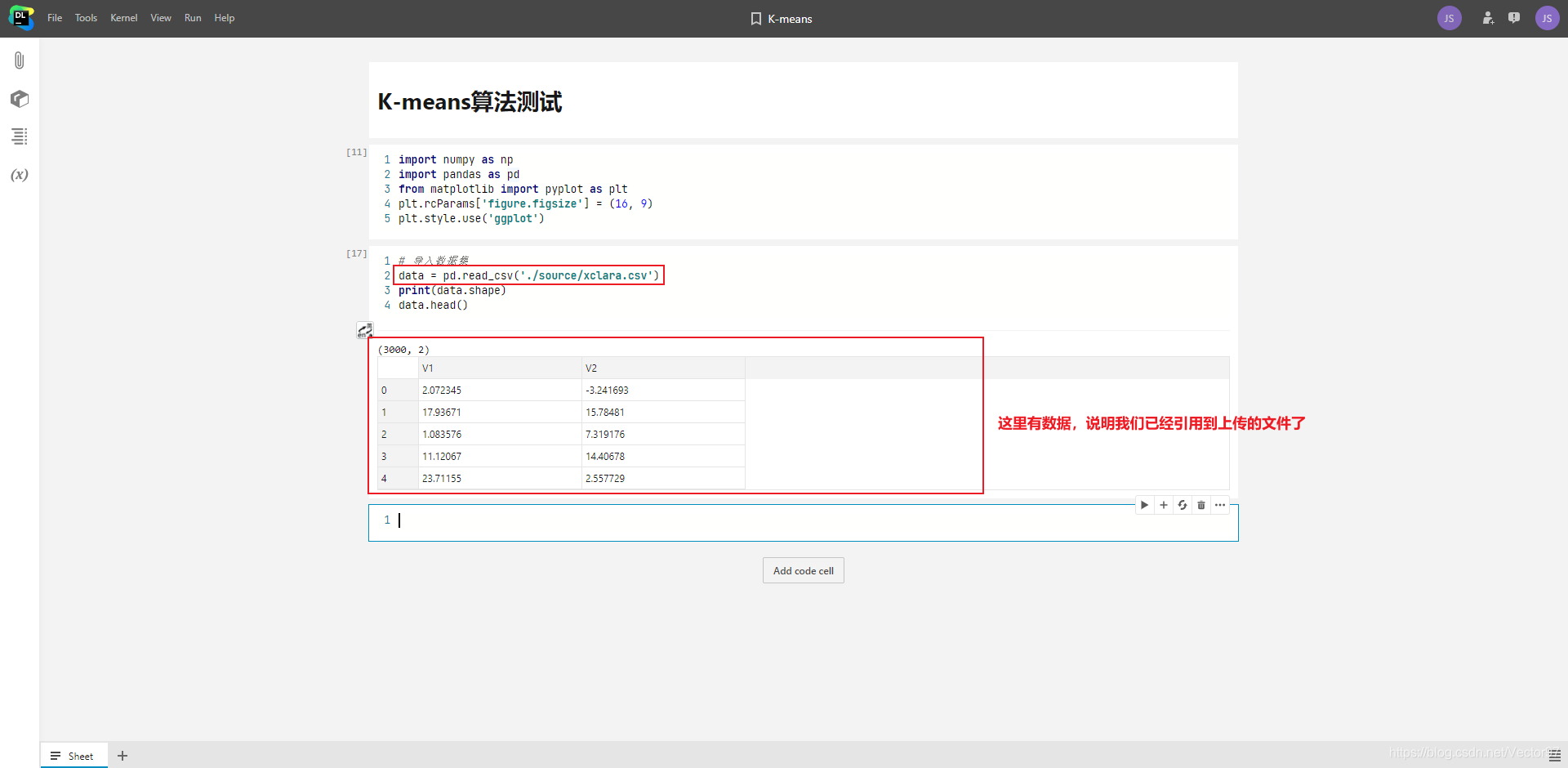
在代码中引用文件
刚才我是把文件上传到了我创建的 k-means notebook中了,所以下面的代码也是进入k-means notebook中写的。
在上一节中,我在k-means notebook中创建了一个名为source的文件夹,并上传了一个名为xclara.csv的文件,所以路径为下面的路径。读者可以作为参考。
datalore的优点
上面说了感觉datalore是jupyter的升级版。他包含两个方面的意思:
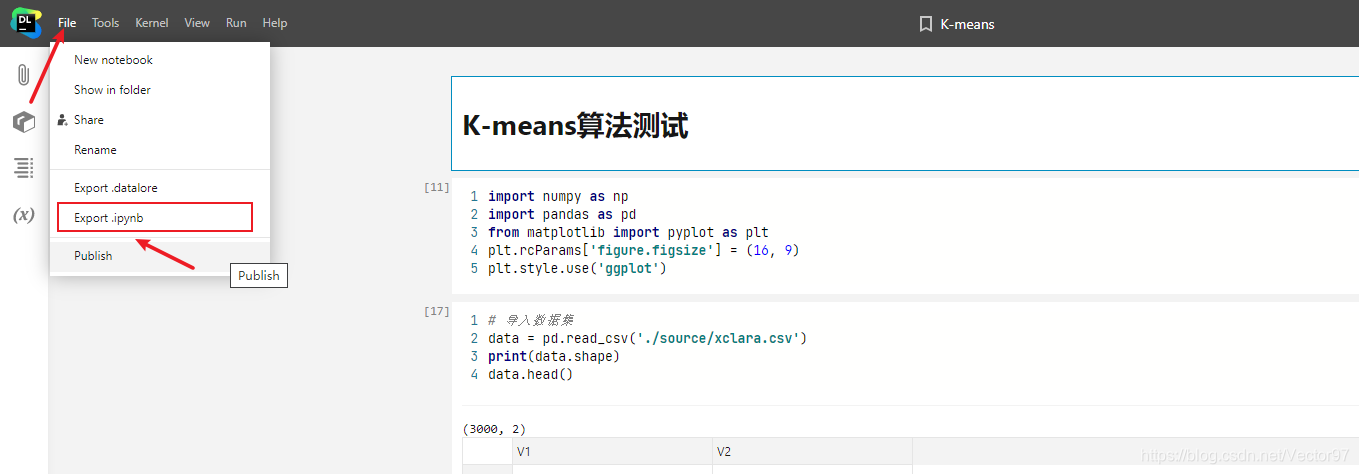
- 一方面他的使用逻辑跟jupyter很像,都是通过notebook组织项目,而且如上面的编码,使用逻辑跟jupyter也很像。比如可以切换编程模式/markdown模式等。另外它跟notebook是兼容的,比如下图可以到处jupyter支持的文件格式。
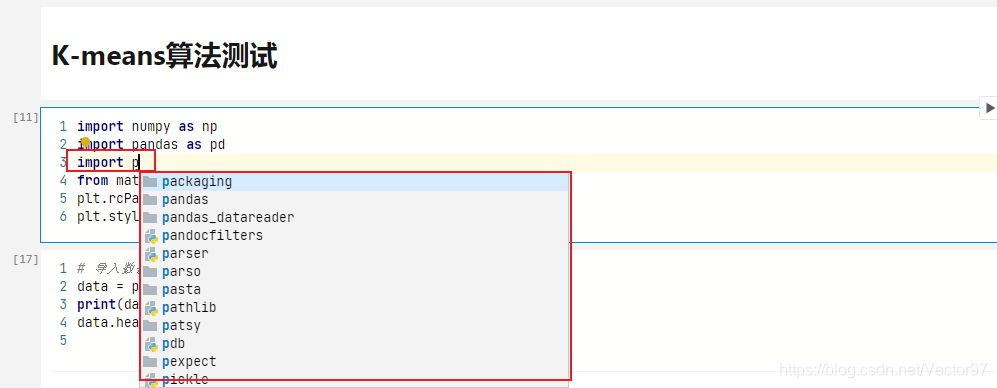
- 另一方面,datalore支持代码提示功能!!!如下图。作为一个IDE来说,代码提示几乎是刚需,Java这种语言就不用说了,python虽然比较简单,api普遍也比较短,但是没有代码提示就像是在摸黑走回家的路,即使这路你再熟悉,摸黑能回家,也不如白天回家更得心应手(脚)对吧。所以代码提示还是很重要的!
缺点
写上面的段落的时候只是简单的尝鲜了一下。这个工具也刚出来不久,用的过程中发现好像还有一些bug,总体体验不是特别好。
大家可以先观望一下,等过段时间再用。


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









