




前言
导包等一些基础的准备问题就不说了,有问题留言。
微信公众号:大数据报文
Main
虽然说的是streamming,但是这里会分别说流处理和批处理。
流处理
val ds = df
//注意这里的as("value")是必须的,因为写入kafka的数据一定要有value,根据实际情况也需要指定key
.selectExpr(formats($"USERID", $"ADDRESS", $"XQMC").as("value"),lit("data_increment_data.kafka.kafIns.water.t_water.*.*.*").as("key"))
.writeStream
.format("kafka")
//注意这里的参数kafka.bootstrap.servers,而不是bootstrap.servers,写成这样会提示没有bootstrap.servers参数
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.start()
批处理
//注意事项与流处理一样,只是这里不需要指定outputmode,action由start变成了save()
waterDF.select(formats($"USERID", $"ADDRESS", $"XQMC").as("value"),lit("data_increment_data.kafka.kafIns.water.t_water.*.*.*").as("key"))
.write
.format("kafka")
.option("kafka.bootstrap.servers", "master:9098")
.option("topic", "water")
.save()
sink结果
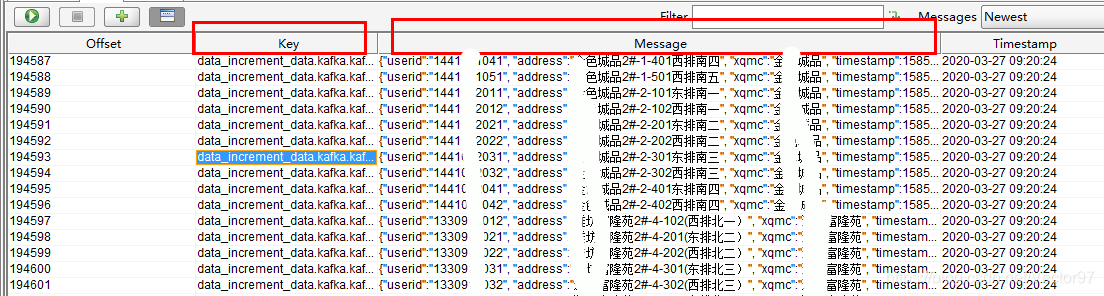
可以看到指定了key和value都写入到指定位置了。
错误处理
由于上述,把option("kafka.bootstrap.servers", "master:9098"),错写成option("bootstrap.servers", "master:9098"),导致报错
Caused by: org.apache.kafka.common.config.ConfigException: Missing required configuration "bootstrap.servers" which has no default value。
如果不注意,看到这个问题很奇怪,因为我明明指定了bootstrap.servers了啊,但是其实是指定错了。
总结
有些有头无尾,只写了数据如何sink到kafka并没有说如何接入kafka的数据。下次有机会补上。有问题也可以留言。

















 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









