




 论文提出了Agile Amulet,一种用于显著性目标检测的高效框架,通过上下文注意力引导低层特征学习,实现更快、更准确的显著区域检测。与现有方法相比,该框架减少了模型大小,提高了计算效率,并在7个大型数据集上表现出优越性能。
论文提出了Agile Amulet,一种用于显著性目标检测的高效框架,通过上下文注意力引导低层特征学习,实现更快、更准确的显著区域检测。与现有方法相比,该框架减少了模型大小,提高了计算效率,并在7个大型数据集上表现出优越性能。
这是一篇发表在CVPR 2018上的论文,论文提出了一种用于显著性目标检测的敏捷聚合多层特征框架,简称为Agile Amulet。
显著目标检测目的是识别图像中最为显著的物体或区域,它可以作为许多对象相关应用的第一步,例如实例检索,语义分割,视觉跟踪和行人再识别等。
Introduction
Agile Amulet和现有的显著性目标检测工作类似,使用多层次的卷积特性来预测显著性的映射,利用这个contextual attention的模块快速地找出最显著的物体或区域。它能引导低层次的特征学习,并且迫使原网络更关注于信息丰富的对象区域。另外论文还提出了一种新的聚合多层特征方法,可以显著降低模型参数和复杂度。
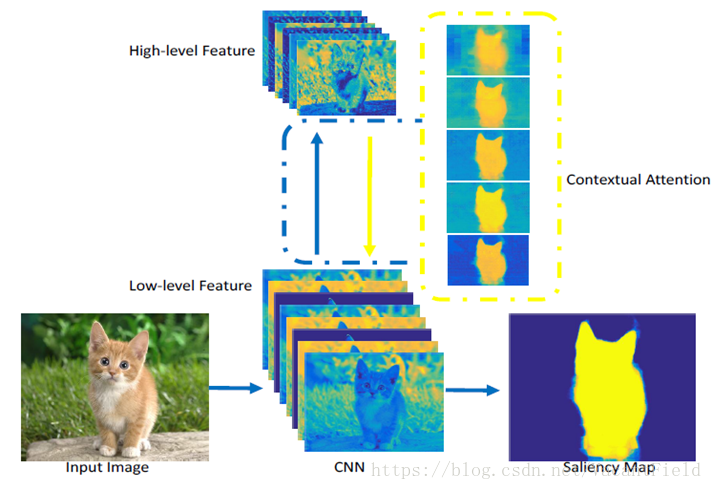
现有的基于深度学习的显著性方法,能够通过利用预训练的深度CNN和多重损失监督,达到一个很不错的检测精度。但在作者的观点看来,主要都存在如下缺点:
首先是CNN架构被过度地设计了,比如在DSS方法中,引入了一系列密集的短连接来融合深层和浅层的特征,这样会带来的一个结果是网络变得冗余和计算效率降低。
第二个是训练过程空间和时间的消耗很大,因为他们的框架中引入了更多计算效率低下的卷基层。
第三个不足之处是显著性预测的速度没有达到预期。当前速度最快的DHS方法在Titan X上跑256*256的图像速度只达到了22.5帧每秒。
总的来说,论文主要有如下4点贡献:
1.论文的方法能明显提高显著性检测的性能,这个能在7个大型数据集上体现出来。
2.论文介绍的上下文attention能够用来快速提取显著区域并进行有效的低层次特征学习指引。
3.提出一种新的多层特征融合方法能够降低模型的大小并且提高计算效率。
4.在进行测试的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2466
2466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









