




 本文介绍了两种深度学习方法,《Deeply Supervised Salient Object Detection with Short Connections》和《Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection》,用于显著目标检测。前者使用DSS网络结构,在测试时混合2、3、4层的side-out以获得更佳效果,并采用CRF进行边界修正。后者Amulet网络则通过多级特征提取、基于分辨率的特征融合、递归显著性图预测、边界保留细化和最终融合预测来提升检测性能。
本文介绍了两种深度学习方法,《Deeply Supervised Salient Object Detection with Short Connections》和《Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection》,用于显著目标检测。前者使用DSS网络结构,在测试时混合2、3、4层的side-out以获得更佳效果,并采用CRF进行边界修正。后者Amulet网络则通过多级特征提取、基于分辨率的特征融合、递归显著性图预测、边界保留细化和最终融合预测来提升检测性能。
1.《Deeply Supervised Salient Object Detection with Short Connections》
DSS网络结构如下:


在测试时为了得到更好的效果,只使用2,3,4层的side-out来混合。
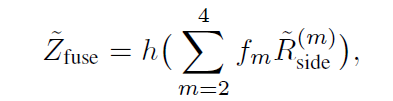
final输出如下:
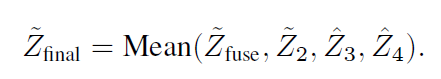
另外,还使用CRF作为post process 修正边界。CRF的实现借助开源包PyDenseCRF。因为只有两类,所以直接用CRF得到的每个像素显著的后验概率作为显著预测值,构成显著预测图。
CRF能量函数如下:



2.《Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection》
Amulet网络结构图如下:

(1)Multi-level feature extraction
VGG16, 抽取5个level的特征
(2)Resolution-based feature integration
通过下采样或上采样,每个level都融合feature exgtraction模块提取的所以level特征。

(3)Recursive saliency map prediction.
每个level的预测使用当前level特征和上一层level的预测信息。
使用深度监管策略。
(4)Boundary preserved refinement
通过第一个level得到边界图Bl,然后用Bl修正每层level预测图

(5) fusion saliency prediction (FSP) as the final output.


















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









