




关键字(keyword)
-
被Java赋予了特殊含义,用作专门用途的字符串
-
全部都是
小写字母

关键字一共51个,其中
const、goto和_是保留字
true、false、null不在其中,它们看起来是关键字,实则是字面量,表示特殊的布尔值和空值
关键字分类
用于定义数据类型的关键字
| class | interface | enum | byte | short |
|---|---|---|---|---|
| int | long | float | double | char |
| boolean | void |
用于定义流程控制的关键字
| if | else | switch | case | default |
|---|---|---|---|---|
| while | do | for | break | continue |
| return |
用于定义访问权限修饰符的关键字
| private | protected | public |
|---|
用于定义类、函数、变量修饰符的关键字
| abstract | final | static | synchronized |
|---|
用于定义类与类之间关系的关键字
| extends | implements |
|---|
用于定义建立实例及引用实例、判断实例的关键字
| new | this | super | instanceof |
|---|
用于异常处理的关键字
| try | catch | finally | throw | throws |
|---|
用于包的关键字
| package | import |
|---|
其他修饰符关键字
| native | strictfp* | transient | volatile | assert |
|---|---|---|---|---|
| const | goto |
用于定义数据类型值的字面值
| true | false | null |
|---|
标识符(identifier)
Java中变量、方法、类等要素命名时使用的字符序列,称为标识符。
凡是自己可以起名字的地方都叫标识符。
命名规则——必须遵守
-
是由字母大小写、数字(0-9)、下划线和$组成的字符序列
-
理论上可以用中文当标识符,但不推荐,容易乱码。因为Java采用Unicode字符集。
-
-
必须是字母大小写,下划线__或$开头,不能是数字开头
-
不可以直接使用保留字、关键字和特殊值作为标识符,但可以包含它们
-
Java中严格区分大小写,长度无限制(但最好不要太长)
-
不能包含空格
由于Java严格区分大小写,area、Area、AREA是不同的标识符
为了提高可读性,明明尽量避免采用缩写作为标识符。如numberOfStudents而不是numStuds
不要用$明明标识符,按照惯例,$应该应用在机器自动产生的源代码中
命名规范——建议遵守
-
注意,在起名字的时候,为了提高可读性,要“见名知意”
-
类名(class后面):大驼峰命名法,形式为XxxYyyZzz,即每一个单词首字母大写
-
变量名或方法名:小驼峰命名法,形式xxxYyyZzz,即从第二个单词开始首字母大写;如果只有一个单词则小写。
-
包名:全部小写,多个单词层级之间用
.分割,形式为xxx.yyy.zzz-
例如用公司域名倒置写包名:com.abc.xxx
-
-
常量名:全部大写,多个单词之间用
_分割,形式:XXX_YYY_ZZZ-
比如:MAX_VALUE
-
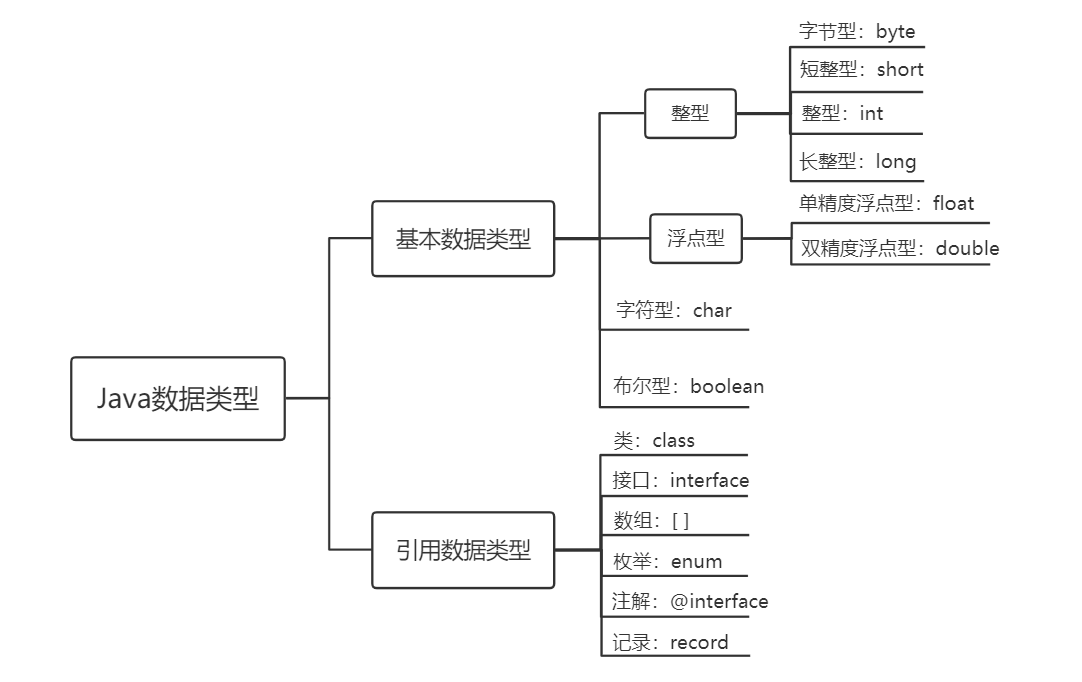
Java基本数据类型
整数类型
-
Java各整数类型有
固定的表示范围和字段长度,不受具体OS影响,保证Java程序的可移植性。
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| byte | 1B | -128~127 |
| short | 2B | -2^{15}~2^{15}-1 |
| int | 4B | -2^{31}~2^{31}-1 |
| long | 8B | -2^{63}~2^{63}-1 |
-
定义long类型的变量,赋值需要以
l或L为结尾 -
Java中变量声明通常为int型,除非不足以表示较大的数采用long
-
Java的整型常量
默认为int型
浮点类型
-
Java浮点类型有
固定的表示范围和字段长度,不受具体OS影响,保证Java程序的可移植性。
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| float | 4B | -3.043E38~3.043E38 |
| double | 8B | -1.798E308~1.798E308 |
-
float尾数可以精确到7位有效数字,很多情况下精度难以满足要求
-
double:双精度,精度是float的两倍,通常采用此类型
-
定义float类型的变量,赋值需要以
f或F作为后缀 -
Java浮点型常量
默认为double型 -
float表数范围比long大,但精度不高
关于浮点型精度
-
不是所有小数都可以精确的用二进制浮点数表示。二进制浮点数不能精确表示0.1、0.01、0.001这样的10的负次幂
-
浮点类型float、double的数据不适合在
不容许舍入误差的领域。如果需要精确数字计算或保留指定位数的精度,需要使用BigDecimal类
字符类型
-
char型数据用来表示通常意义上的字符,占2字节
-
Java中支持用Unicode编码,它是一个16位编码方案。所以一个字符可以存储一个字母、一个汉字或其他书面语的一个字符。
-
大多数计算机采用ASCII码,它是表示所有
大小写字母、数字、标点符号以及控制字符的8位编码方案。Unicode码包含ASCII码,其中从\u0000到\u007F对应128个ASCII字符。字符 十进制编码值 Unicode值 '0' ~ '9' 48 ~ 57 \u0030 ~ \u0039 'A' ~ 'Z' 65 ~ 90 \u0041 ~ \u005A 'a' ~ 'z' 97 ~ 122 \u0061 ~ \u007A -
字符型变量:
-
使用单引号
''括起来的单个字符-
char ch = 'a'; char ch2 = '中'; char ch3 = '9';
-
-
直接使用Unicode值表示字符型常量
-
形式
\uXXXX,其中XXXX表示一个十六进制的整数 -
例如
\u0023表示'#'
-
-
允许使用转义字符
\将其后的字符转变为特殊字符型常量-
如char ch = '\n';表示换行符
-
转义序列 名称 Unicode码 十进制值 \b 退格键 \u0008 8 \t Tab键 \u0009 9 \n 换行符 \u000A 10 \f 换页符 \u000C 12 \r 回车符 \u000D 13 \\ 反斜杠 \u005C 92 \' 单引号 \u0027 39 \" 双引号 \u0022 34 -
char类型是可以运算的,因为它都有对应的Unicode码,可以看作一个数值。
要想显示转义字符\,需要写\\
布尔类型:boolean
-
boolean类型用来判断逻辑条件,一般用于流程控制语句中
-
if条件控制语句
-
while循环控制语句
-
for循环控制语句
-
do-while循环控制语句
-
-
boolean类型数据只有两个值:
true/false-
不可以使用0或非0的整数代替false和true,不同于C语言
-
Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达所操作的boolean值,在编译之后都使用java虚拟机中的int数据类型来代替:true用1表示,false用0表示
-
一般不谈boolean的占用空间大小,不过真正在内存中分配的时候其实是4B
-
逻辑判断语句
if(flag) //不要写成 if(flag == true)
if(!flag) //不要写成 if(flag == false)
变量
概念
-
内存中的一个存储区域,该区域的数据可以在同一类型范围内不断变化
-
变量的构成包含三个要素:
数据类型、变量名、存储的值 -
Java中变量声明的格式:
数据类型 变量名 = 变量值
-
变量的作用:用于在内存中保存数据。
-
使用变量注意:
-
Java中每个变量必须先声明,后使用(强类型)。
-
使用变量名来访问这块区域的数据。
-
变量的作用域:其定义所在的一对{ }内。
-
变量只有在其
作用域内才有效。出了作用域,变量不可以再被调用。 -
同一个作用域内,不能定义重名的变量。
-
Java中变量的数据类型
变量的使用
变量的声明
//存储一个整数类型的年龄
int age;
//存储一个小数类型的体重
double weight;
//存储一个单字符类型的性别
char gender;
//存储一个布尔类型的婚姻状态
boolean marry;
//存储一个字符串类型的姓名
String name;
//声明多个同类型的变量
int a,b,c; //表示a,b,c三个变量都是int类型。变量的数据类型可以是基本数据类型,也可以是引用数据类型
变量的赋值
用合适的常量值给已经声明的变量
举例1:可以使用合适类型的常量值给已经声明的变量赋值
age = 18;
weight = 109;
gender = '女';举例2:可以使用其他变量或者表达式给变量赋值
int m = 1;
int n = m;
int x = 1;
int y = 2;
int z = 2 * x + y;举例3:变量可以反复赋值
//先声明,后初始化
char gender;
gender = '女';
//给变量重新赋值,修改gender变量的值
gender = '男';
System.out.println("gender = " + gender);//gender = 男举例4:也可以将变量的声明和赋值一并执行
boolean isBeauty = true;
String name = "迪丽热巴";基本数据类型变量间运算规则
在Java程序中,不同的基本数据类型(只有7种,不包含boolean类型)变量的值经常需要进行相互转换。
转换的方式有两种:自动类型提升和强制类型转换。
自动类型转换

以下三种情况会发生自动类型转换:
-
当把存储范围小的值(常量值、变量的值、表达式计算的结果)赋给存储范围大的变量时
int i = 'A';//char自动升级为int,其实就是把字符的编码值赋值给i变量了
double d = 10;//int自动升级为double
long num = 1234567; //右边的整数常量值如果在int范围呢,编译和运行都可以通过,这里涉及到数据类型转换
//byte bigB = 130;//错误,右边的整数常量值超过byte范围
long bigNum = 12345678912L;//右边的整数常量值如果超过int范围,必须加L,显式表示long类型。否则编译不通过-
当存储范围小的数据类型与存储范围大的数据类型变量一起混合运算时,会按照其中最大的类型运算。
int i = 1;
byte b = 1;
double d = 1.0;
double sum = i + b + d;//混合运算,升级为double
当byte、short、char数据类型的变量进行算术运算时,按照int类处理
byte b1 = 1;
byte b2 = 2;
byte b3 = b1 + b2;//编译报错,b1 + b2自动升级为int
char c1 = '0';
char c2 = 'A';
int i = c1 + c2;//至少需要使用int类型来接收
System.out.println(c1 + c2);//113 强制类型转换

规则:将取值范围大(或容量大)的类型强制转换成取值范围小(或容量小)的类型。
自动类型提升是Java自动执行的,而强制类型转换是自动类型提升的逆运算,需要我们自己手动执行。
转换格式
数据类型1 变量名 = (数据类型1)被强转数据值; //()中的数据类型必须<=变量值的数据类型
-
当把存储范围大的值(常量值、变量的值、表达式计算的结果值)强制转换为存储范围小的变量时,可能会
损失精度或溢出。int i = (int)3.14;//损失精度 double d = 1.2; int num = (int)d;//损失精度 int i = 200; byte b = (byte)i;//溢出 -
当某个值想要提升数据类型时,也可以使用强制类型转换。这种情况的强制类型转换是
没有风险的,通常省略。 -
声明long类型变量时,可以出现省略后缀的情况。float则不同。
long l1 = 123L; long l2 = 123;//如何理解呢? 此时可以看做是int类型的123自动类型提升为long类型 //long l3 = 123123123123; //报错,因为123123123123超出了int的范围。 long l4 = 123123123123L; //float f1 = 12.3; //报错,因为12.3看做是double,不能自动转换为float类型 float f2 = 12.3F; float f3 = (float)12.3;
与String类型之间的运算
字符串类型:String
-
String属于引用数据类型
-
使用
""来表示一个字符串,内部可以包含0个或多个字符 -
声明方式:String str = "Hello"
运算规则
-
任意八种基本数据类型的数据与String类型只能进行连接“+”运算,且结果一定也是String类型
System.out.println("" + 1 + 2);//12 int num = 10; boolean b1 = true; String s1 = "abc"; String s2 = s1 + num + b1; System.out.println(s2);//abc10true //String s3 = num + b1 + s1;//编译不通过,因为int类型不能与boolean运算 String s4 = num + (b1 + s1);//编译通过 -
String类型不能通过强制类型()转换,转为其他的类型
String str = "123"; int num = (int)str;//错误的 int num = Integer.parseInt(str);//正确的,后面才能讲到,借助包装类的方法才能转
Integer.parseInt(str):将数字符号的字符串转为整数
方法
-
str.length():获取字符串长度,返回一个数值。空字符串返回0 -
str.charAt(index):用于提取str钟的某个特定字符,其中下标index的取值范围是0到str.length()-1之间。注意:str.charAt(str.length())会返回StringIndexOutOfBoundsException异常
-
String s3 = s1.concat(s2):将s1和s2合并构成s3也等价于String s3 = s1 + s2
注意“+”仅在两端操作数至少有一个是字符串时是连接作用,否则是算数运算符。并且也支持"+=",如
message += "Hello World"
注意区分:
System.out.println("i + j is " + i + j) 和 System.out.println("i + j is " + (i + j)) -
转载字符串
-
str.toLowerCase():返回一个全小写的新的字符串
-
str.toUpperCase():返回一个全大写的新的字符串
-
str.trim():删除字符串两边的空白字符并返回一个新字符串。(空白字符:
' ','\t','\n','f','r'等)
-
-
读入
Scanner sc = new Scanner (System.in);
String s = sc.nextLine()-
基于标记的输入:读入用空白分割的单个字符
-
next()
-
nextByte()
-
nextShort()
-
nextInt()
-
nextLong()
-
nextFloat()
-
nextDouble()
-
-
基于行的输入
-
nextLine()
-
不要在基于标记的输入之后使用基于行的输入!
-
比较
-
s1.equals(s2):如果s1和s2相同,返回True
-
s1.equalsIgnoreCase(s2):如果s1和s2相同,返回True,不区分大小写
-
s1.compareTo(s2):返回一个大于0,等于0或小于0的整数,分别表示s1是否大于等于或小于s2。这个整数是字典序差值。
-
s1.compareToIgnoreCase(s2):同3,且不区分大小写
-
s1.startsWith(prefix):若以特定前缀开始,返回true
-
s1.endsWith(suffix):若以特定后缀结束,返回true
-
s1.contains(s2):若s2是s1的子字符串,返回true
-
不能用
==操作符判断两个字符串内容是否相等!如 if (string1 == string2)
事实上只能检测string1和string2是否指向同一个对象
-
获得子串 str.substring(beginIndex,endIndex):返回从beginIndex开始到endIndex-1的子串。endIndex可省略,表示从beginIndex到字符串结束。
若beginIndex==endIndex返回空字符串,若beginIndex>endIndex,则发生运行时错误。
-
查找字符串的字符或子串
-
str.indexOf(ch):返回字符串中出现的第一个ch的下标,没有则返回-1
-
str.indexOf(ch,fromIndex):返回字符串中fromIndex之后出现的第一个ch的下标,如果没有返回-1
-
str.indexOf(str1):返回字符串中出现的第一个字符串str1出现的下标,没有匹配的返回-1
-
str.indexOf(str1,fromIndex):返回字符串中fromIndex之后出现的第一个str1的下标,如果没有返回-1
-
str.lastIndexOf(ch):返回字符串中出现的最后一个ch的下标,如果没有返回-1
-
str.lastIndexOf(ch,fromIndex):返回字符串中fromIndex出现的最后一个ch的下标,如果没有返回-1
-
str.lastIndexOf(str1):返回字符串中出现的最后一个str1的下标,如果没有返回-1
-
str.lastIndexOf(str1,fromIndex):返回字符串中fromIndex出现的最后一个str1的下标,如果没有返回-1
//例:提取姓名 ,如Kim Jones
int k = str.indexOf(' ');
String firstName = str.substring(0,k);
String lastName = str.substring(k + 1);-
与数值间的转换
-
数值型字符串转换为数值
int value = Integer.parseInt(str); //str = "123" int value2 = Integer.parseDouble(str2); //str2 = "123.2"如若不是数值型字符串会发生运行时错误
-
数值转换为字符串
String s = number + "";
-
运算符
运算符的分类
-
按照
功能分为:算术运算符、赋值运算符(增强)、比较(或关系)运算符、逻辑运算符、位运算符、条件运算符、Lambda运算符
| 分类 | 运算符 |
|---|---|
| 算术运算符(7个) | +、-、*、/、%、++、-- |
| 赋值运算符(12个) | =、+=、-=、*=、/=、%=、>>=、<<=、>>>=、&=、|=、^=等 |
| 比较(或关系)运算符(6个) | >、>=、<、<=、==、!= |
| 逻辑运算符(6个) | &、|、^、!、&&、|| |
| 位运算符(7个) | &、|、^、~、<<、>>、>>> |
| 条件运算符(1个) | (条件表达式)?结果1:结果2 |
| Lambda运算符(1个) | ->(第18章时讲解) |
-
按照
操作数个数分为:一元运算符(单目运算符)、二元运算符(双目运算符)、三元运算符 (三目运算符)
| 分类 | 运算符 |
|---|---|
| 一元运算符(单目运算符) | 正号(+)、负号(-)、++、--、!、~ |
| 二元运算符(双目运算符) | 除了一元和三元运算符剩下的都是二元运算符 |
| 三元运算符 (三目运算符) | (条件表达式)?结果1:结果2 |
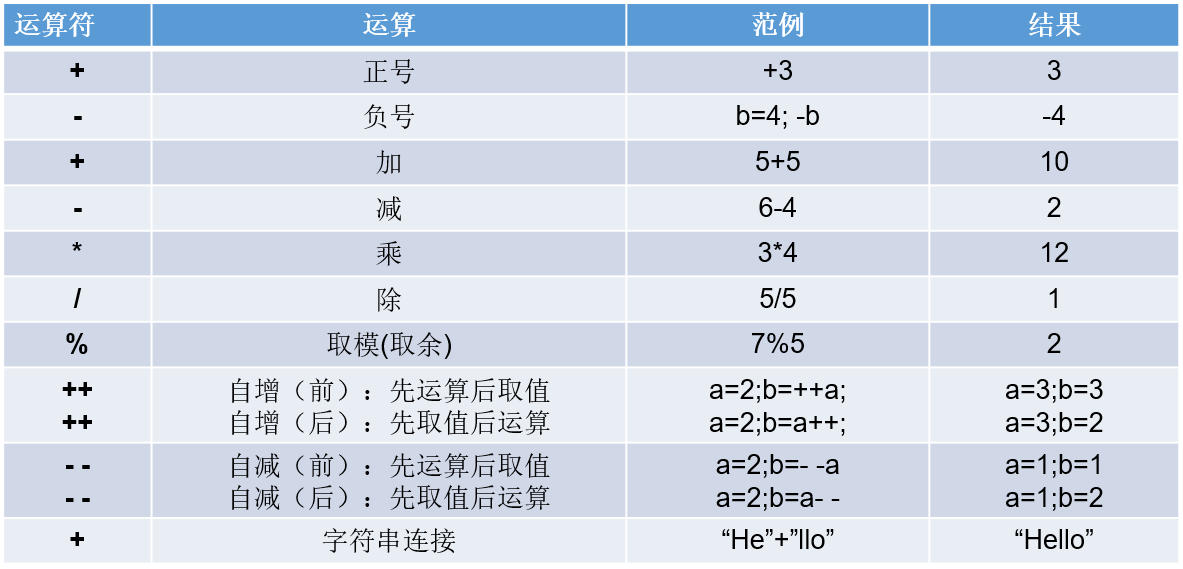
算术运算符
+,-,*,/,%
加(+): 有字符串参与就是拼接,结果也是字符串; 没有字符串参与就是求和,结果就是数字; 减(-):正常减 乘(*):正常乘 除(/): 整数 / 整数 结果一定是整数(向0取整) 被除数 / 除数,如果都是整数的话,那么除数不能为0,否则会发生ArithmeticException异常 如果是小数的话,那么除数为0,结果是Infinity 无穷 模(就是取余数,%): 被模数 % 模数 的结果的正负号与被模数相同
自增自减
自增(++):让自增变量本身+1 自减(--):让自增变量本身-1 以自增为例:
-
当自增表达式独立一个语句时,例如:a++; ++a; 此时++在前在后没有区别,都是自增变量+1
-
当自增表达式与其他的计算合为一个语句时,就有区别了
-
++在前,先自增再取值计算
-
++在后,先取值放一边,然后自增,最后用取出来的值计算
-
赋值运算符
-
符号:=
-
当“=”两侧数据类型不一致时,可以使用自动类型转换或使用强制类型转换原则进行处理。
-
支持
连续赋值。
-
-
扩展赋值运算符: +=、 -=、*=、 /=、%=
| 赋值运算符 | 符号解释 |
|---|---|
+= | 将符号左边的值和右边的值进行相加操作,最后将结果赋值给左边的变量 |
-= | 将符号左边的值和右边的值进行相减操作,最后将结果赋值给左边的变量 |
*= | 将符号左边的值和右边的值进行相乘操作,最后将结果赋值给左边的变量 |
/= | 将符号左边的值和右边的值进行相除操作,最后将结果赋值给左边的变量 |
%= | 将符号左边的值和右边的值进行取余操作,最后将结果赋值给左边的变量 |
public class SetValueTest1 {
public static void main(String[] args) {
int i1 = 10;
long l1 = i1; //自动类型转换
byte bb1 = (byte)i1; //强制类型转换
int i2 = i1;
//连续赋值的写法
int a2,b2;
a2 = b2 = 10;
int a3 = 10,b3 = 20;
//举例说明+= -= *= /= %=
int m1 = 10;
m1 += 5; //类似于 m1 = m1 + 5的操作,但不等同于。
System.out.println(m1);//15
//如何实现一个变量+2的操作呢?
// += 的操作不会改变变量本身的数据类型。其他拓展的运算符也如此。
//写法1:推荐
short s1 = 10;
s1 += 2; //编译通过,因为在得到int类型的结果后,JVM自动完成一步强制类型转换,将int类型强转成short
System.out.println(s1);//12
//写法2:
short s2 = 10;
//s2 = s2 + 2;//编译报错,因为将int类型的结果赋值给short类型的变量s时,可能损失精度
s2 = (short)(s2 + 2);
System.out.println(s2);
//如何实现一个变量+1的操作呢?
//写法1:推荐
int num1 = 10;
num1++;
System.out.println(num1);
//写法2:
int num2 = 10;
num2 += 1;
System.out.println(num2);
//写法3:
int num3 = 10;
num3 = num3 + 1;
System.out.println(num3);
}
}哪些运算符改变变量的值?
++/--
=,+=,-=,*=,/=,%=
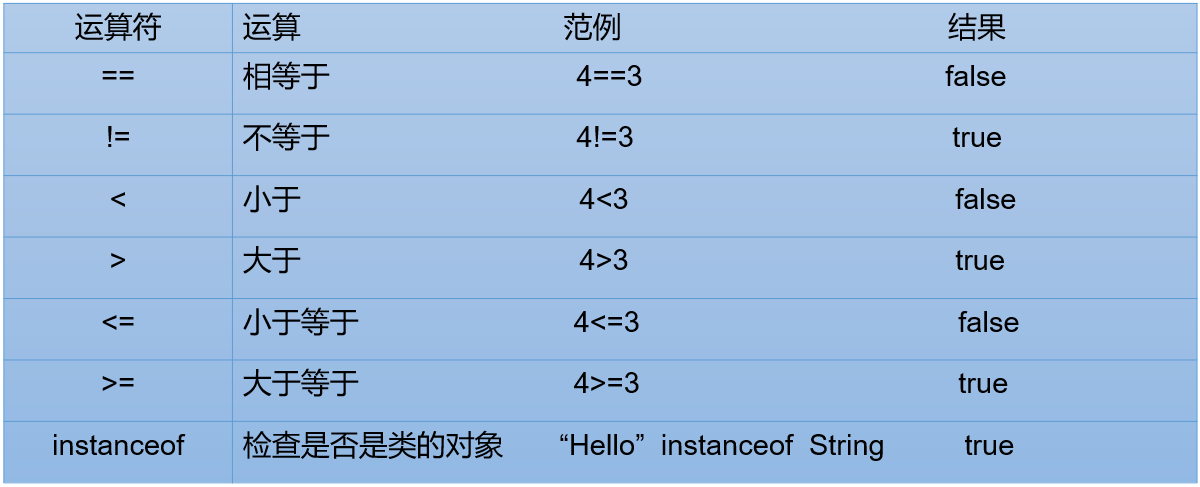
关系运算符
-
比较运算符的结果都是boolean型,也就是要么是true,要么是false。
-
> < >= <= :只适用于基本数据类型(除boolean类型之外)
== != :适用于基本数据类型和引用数据类型
-
比较运算符“
==”不能误写成“=”
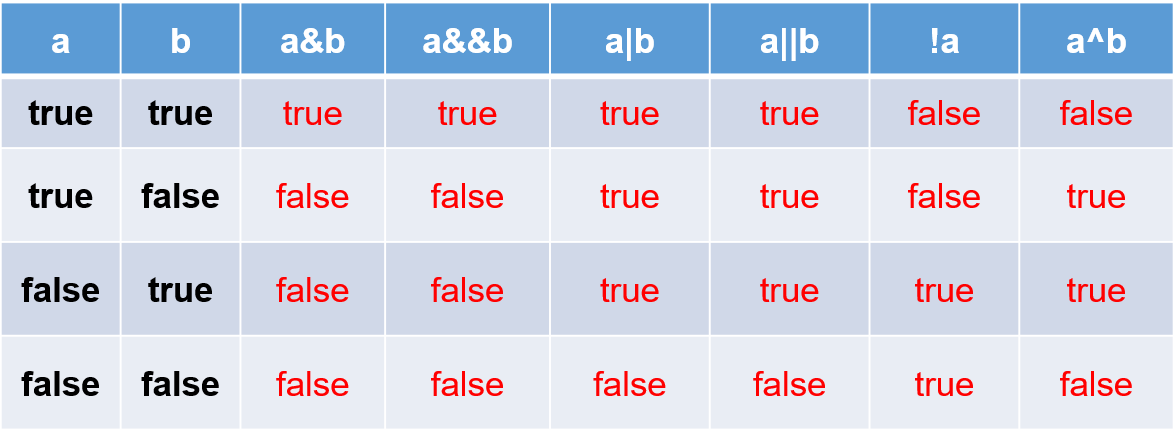
逻辑运算符
-
逻辑运算符,操作的都是boolean类型的变量或常量,而且运算得结果也是boolean类型的值。
-
运算符说明:
-
& 和 &&:表示"且"关系,当符号左右两边布尔值都是true时,结果才能为true。否则,为false。
-
| 和 || :表示"或"关系,当符号两边布尔值有一边为true时,结果为true。当两边都为false时,结果为false
-
! :表示"非"关系,当变量布尔值为true时,结果为false。当变量布尔值为false时,结果为true。
-
^ :当符号左右两边布尔值不同时,结果为true。当两边布尔值相同时,结果为false。
-
理解:
异或,追求的是“异”!
-
-
逻辑运算符用于连接布尔型表达式,在Java中不可以写成 3 < x < 6,应该写成x > 3 & x < 6 。
区分“&”和“&&”:
-
相同点:如果符号左边是true,则二者都执行符号右边的操作
-
不同点:
-
& : 如果符号左边是false,则继续执行符号右边的操作
-
&& :如果符号左边是false,则不再继续执行符号右边的操作
-
推荐使用 &&
-
区分“|”和“||”:
-
相同点:如果符号左边是false,则二者都执行符号右边的操作
-
不同点:
-
| : 如果符号左边是true,则继续执行符号右边的操作
-
|| :如果符号左边是true,则不再继续执行符号右边的操作
-
-
推荐使用 ||
-
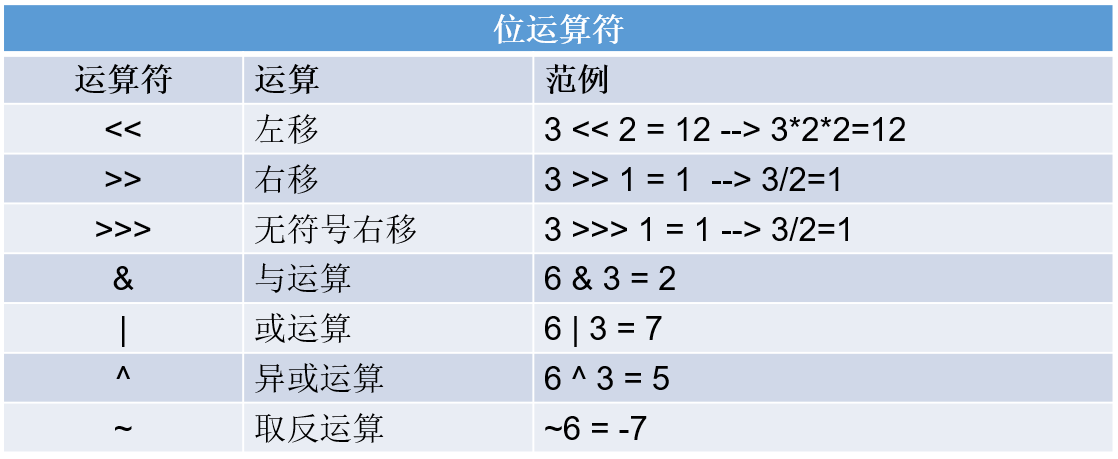
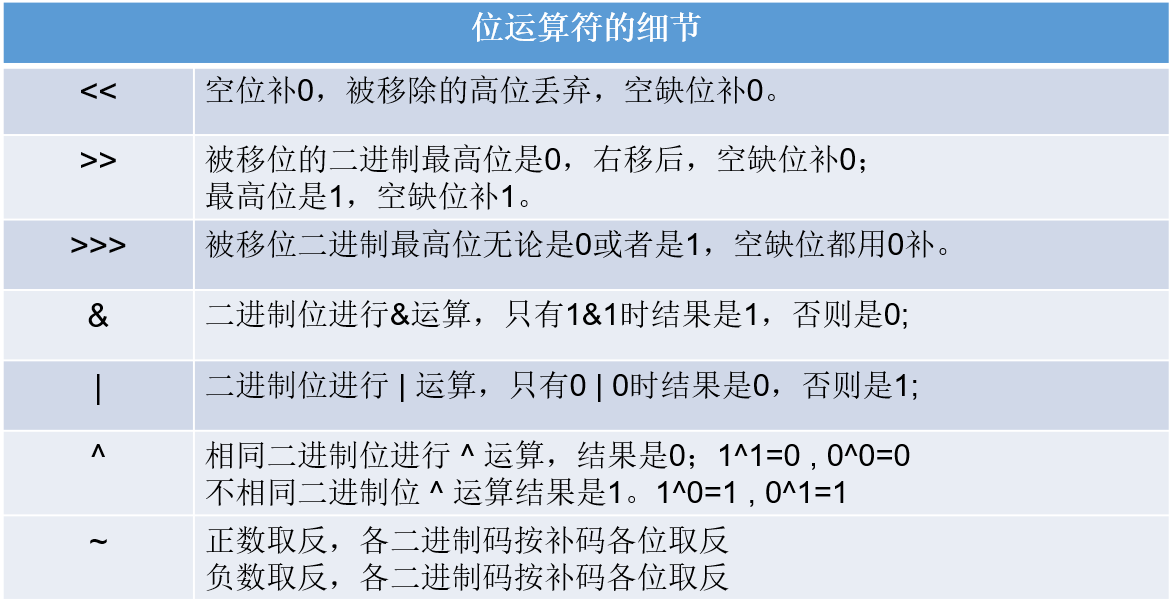
位运算符
-
位运算符的运算过程都是基于二进制的补码运算
左移
-
左移几位,等于乘以2的几次方(正负数都适用)
-
左边几位,二进制补码左边截掉几位,右边补几个0
右移
-
右移几位,等于除以2的几次方(如果不能整除,向下取整)
-
右移几位,二进制补码右边截掉几位,左边补几个0或1,原来最高位是0补0,是1补1
无符号右移
-
对于正数来说,无符号右移与普通右移相同
-
对于负数来说,右移几位,二进制补码右边截掉几位,左边补几个0,负数变正数
以上三种移位,只有负数的>>右移会在最高位补1,其余移位都是补0。
以上三种移位,左移和负数的无符号右移会出现符号位改变。左移可能出现正变负,负变正,负数的无符号右移让负数变正数。
当移动的位数超过当前类型的总位数时,会先处理移位 n % 当前的总位数 = 最终的移位数
-
&:相同为1
-
|:有一个是1就是1
-
^:不同是1
-
~:如果对应位是1,则结果是0;若0结果为1.
案例
//交换两个数 public class BitExer { public static void main(String[] args) { int m = 10; int n = 5; System.out.println("m = " + m + ", n = " + n); //优点:容易理解,适用于不同数据类型 缺点:需要额外定义变量 //int temp = m; //m = n; //n = temp; //优点:没有额外定义变量 缺点:可能超出int的范围;只能适用于数值类型 //m = m + n; //15 = 10 + 5 //n = m - n;//10 = 15 - 5 //m = m - n;//5 = 15 - 10 //优点:没有额外定义变量 缺点:不易理解;只能适用于数值类型 m = m ^ n; n = m ^ n; //(m ^ n) ^ n m = m ^ n; System.out.println("m = " + m + ", n = " + n); }
条件运算符
-
(条件表达式)? 表达式1:表达式2
-
条件表达式是boolean类型的结果,根据boolean的值选择表达式1或表达式2
-
如果运算后的结果赋给新的变量,要求表达式1和表达式2为同种或兼容的类型
public static void main(String[] args) {
int i = (1==2 ? 100 : 200);
System.out.println(i);//200
boolean marry = false;
System.out.println(marry ? "已婚" : "未婚" );
double d1 = (m1 > m2)? 1 : 2.0;
System.out.println(d1);
int num = 12;
System.out.println(num > 0? true : "num非正数");
}运算符优先级
| 优先级 | 运算符说明 | Java运算符 |
|---|---|---|
| 1 | 括号 | () |
| 2 | 成员访问 | .、[] |
| 3 | 正负号 | +、- |
| 4 | 单元运算符 | ++、--、~、! |
| 5 | 乘法、除法、求余 | *、/、% |
| 6 | 加法、减法 | +、- |
| 7 | 移位运算符 | <<、>>、>>> |
| 8 | 关系运算符 | <、<=、>=、>、instanceof |
| 9 | 等价运算符 | ==、!= |
| 10 | 按位与 | & |
| 11 | 按位异或 | ^ |
| 12 | 按位或 | | |
| 13 | 条件与 | && |
| 14 | 条件或 | || |
| 15 | 三元运算符 | ? : |
| 16 | 赋值运算符 | =、+=、-=、*=、/=、%= |
| 17 | 位赋值运算符 | &=、|=、<<=、>>=、>>>= |
不要过多的依赖运算的优先级来控制表达式的执行顺序,这样可读性太差,尽量
使用()来控制表达式的执行顺序。不要把一个表达式写得过于复杂,如果一个表达式过于复杂,则把它
分成几步来完成。例如: (num1 + num2) * 2 > num3 && num2 > num3 ? num3 : num1 + num2;
Ex1:计算机存储
-
了解进制和进制转换,进制如何表达(0x,0b...)
-
符号位、原码、反码、补码了解
-
了解整数、浮点数(IEEE754)存储方式
Ex2:字符集
字符集
-
编码与解码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。
-
字符编码(Character Encoding) : 就是一套自然语言的字符与二进制数之间的对应规则。
-
字符集:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
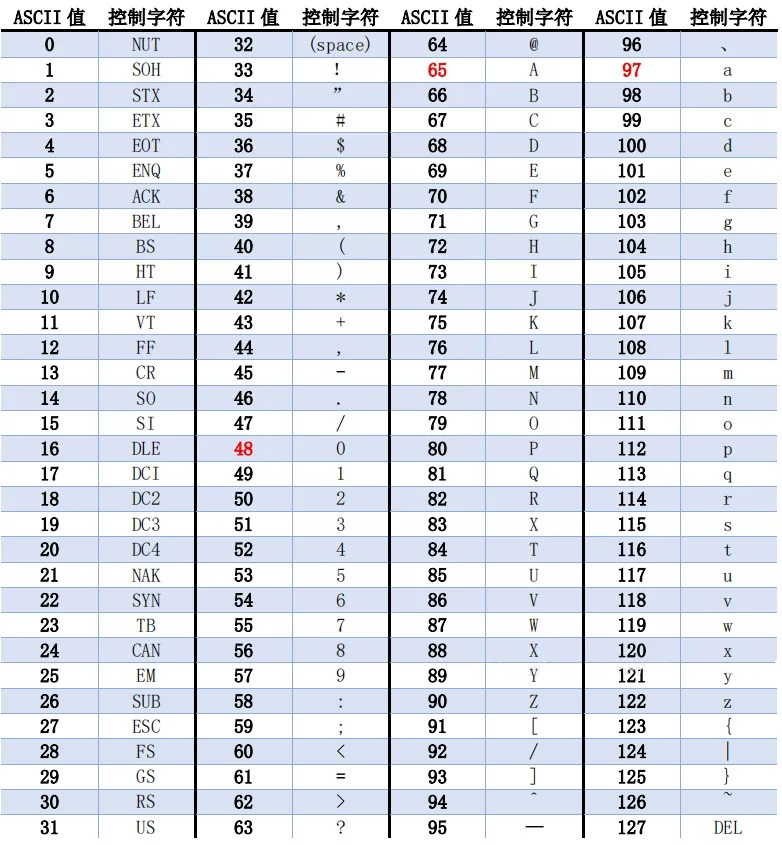
ASCII码
-
ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码):上个世纪60年代,美国制定了一套字符编码,对
英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码。 -
ASCII码用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
-
基本的ASCII字符集,使用7位(bits)表示一个字符(最前面的1位统一规定为0),共
128个字符。比如:空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。 -
缺点:不能表示所有字符。
ISO-8859-1字符集
-
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰语、德语、意大利语、葡萄牙语等
-
ISO-8859-1使用单字节编码,兼容ASCII编码。
GBXXX字符集
-
GB就是国标的意思,是为了
显示中文而设计的一套字符集。 -
GB2312:简体中文码表。一个小于127的字符的意义与原来相同,即向下兼容ASCII码。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含
7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,这就是常说的"全角"字符,而原来在127号以下的那些符号就叫"半角"字符了。 -
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了
双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。 -
GB18030:最新的中文码表。收录汉字
70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
Unicode码
-
Unicode编码为表达
任意语言的任意字符而设计,也称为统一码、标准万国码。Unicode 将世界上所有的文字用2个字节统一进行编码,为每个字符设定唯一的二进制编码,以满足跨语言、跨平台进行文本处理的要求。 -
Unicode 的缺点:这里有三个问题:
-
第一,英文字母只用一个字节表示就够了,如果用更多的字节存储是
极大的浪费。 -
第二,如何才能
区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢? -
第三,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,
不够表示所有字符。
-
-
Unicode在很长一段时间内无法推广,直到互联网的出现,为解决Unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现。具体来说,有三种编码方案,UTF-8、UTF-16和UTF-32。
UTF-8
-
Unicode是字符集,UTF-8、UTF-16、UTF-32是三种
将数字转换到程序数据的编码方案。顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。其中,UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。 -
互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。UTF-8 是一种
变长的编码方式。它可以使用 1-4 个字节表示一个符号它使用一至四个字节为每个字符编码,编码规则:-
128个US-ASCII字符,只需一个字节编码。
-
拉丁文等字符,需要二个字节编码。
-
大部分常用字(含中文),使用三个字节编码。
-
其他极少使用的Unicode辅助字符,使用四字节编码。
-

















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









