



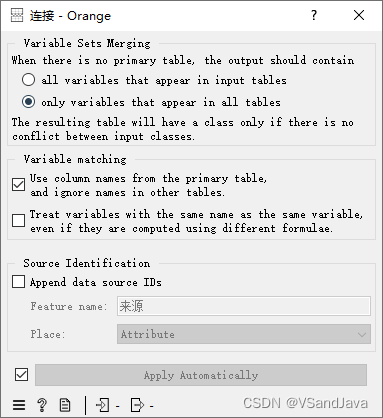
连接
将来自多个来源的数据进行串联。
输入
主要数据:定义属性集的数据集
附加数据:附加的数据集
输出
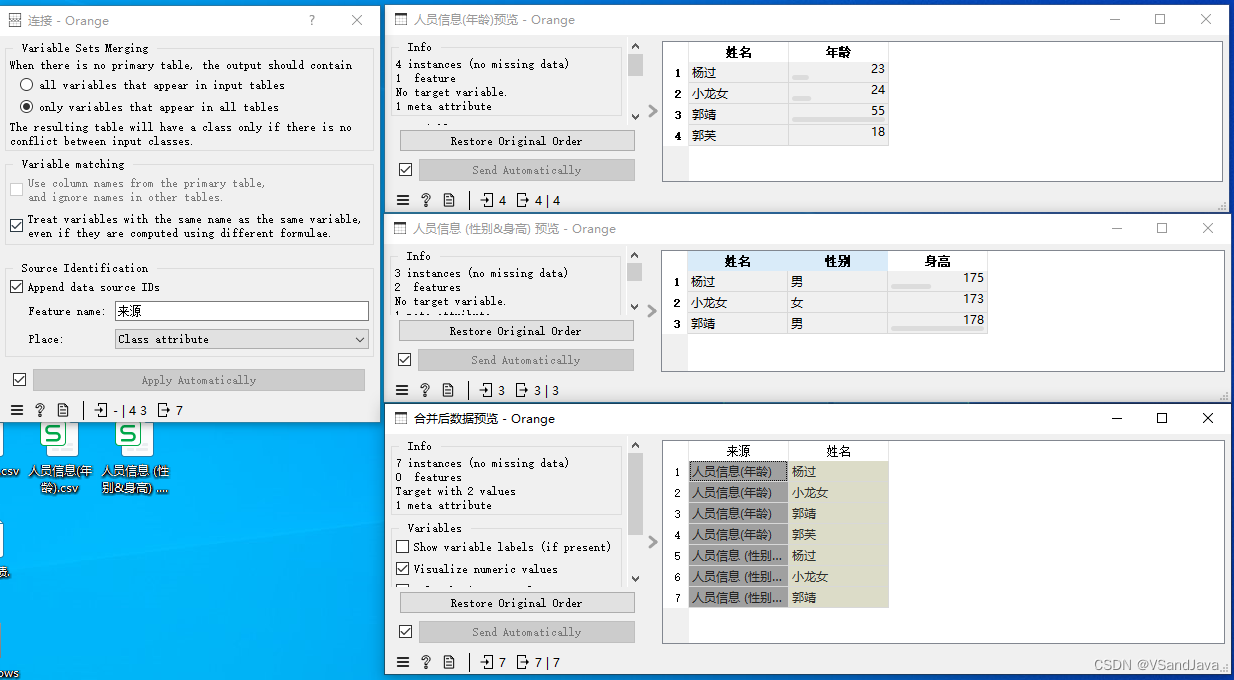
数据:串联后的数据 该组件用于串联多个实例集(数据集)。
合并方式是“垂直”的,即两个各包含10和5个实例的集合并成一个新的包含15个实例的集。
追加标识"Place"选项说明:
Class attribute(类属性):选择此项会将来源标识存放在数据集的类别标签(label)处。类属性通常用于作为预测目标的分类标签,在进行分类任务的数据挖掘时尤其关键。如果你的目的是基于数据来源进行分类或者比较不同源数据的特定属性,那么可以选择这个选项。
Attribute(属性):选择此项会将来源标识存放在数据集的常规属性区域。在Orange3中,属性通常指数据集中的变量或特征,直接用于数据分析和建模的输入。将来源标识存为一个普通属性意味着它可以像数据集中的其他特征一样参与计算和分析,适用于那些希望将数据来源作为分析因素之一的情况。
Meta attribute(元属性):选择此项会将来源标识存放在元属性区域。元属性用于存储额外信息,它们不直接参与主要的分析计算过程,但可用于记录数据的附加信息,如样本的收集日期、数据来源等。选用元属性来存放来源标识适合那些希望保留数据来源信息但不想让它干扰数据主要分析流程的场景。
简而言之,这三个选项让用户能够根据分析目的和需求,灵活选择数据来源标识在合并后数据集中的存储位置。无论是作为分析的一部分(类属性或属性),还是仅作为参考信息(元属性),这都为数据分析过程提供了更多的自定义可能性。
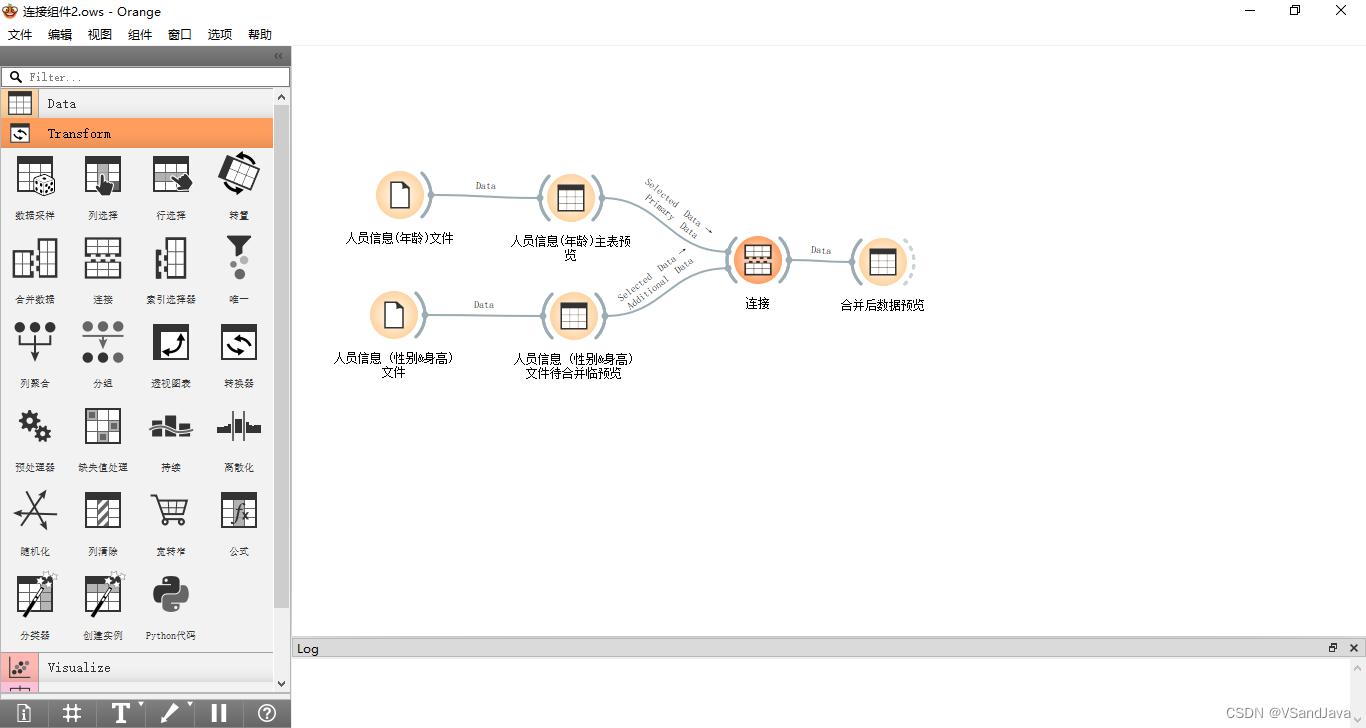
流程
视频教程:关注我抖音号:Orange3dev
https://www.douyin.com/user/MS4wLjABAAAAicBGZTE2kX2EVHJPe8Ugk3_nlJk9Nha8OZh4Bo_nTu8
1-Orange3安装
2-Orange3汉化DIY
3-Orange3创建快方式
4-数据导入(文件&数据表格组件)
5-数据导入(Python组件)
6-Python库安装(SQL表组件)
7-数据导入(Mysql)
8-数据导入(数据绘画和公式组件)
9-数据修改(域编辑和保存组件)
10-数据可视化(调色板&数据信息组件)
11-数据可视化(特征统计组件)
12-数据预处理(行选择组件)
13-特征选择(Rank组件)
14-数据转换(数据采样组件)
15-数据预处理(列选择组件)
16-数据预处理(转置组件)
17-数据预处理(合并数据组件)
18-数据预处理(连接组件)无主表且列数不同
19-数据预处理(连接组件)主附表
20-数据预处理(索引选择器组件)
21-数据预处理(唯一组件)
22-数据预处理(列聚合组件)
23-数据预处理(分组组件)
24-数据预处理(透视图表组件)
25-数据预处理(转换器组件)-表格互为模板
26-数据预处理(转换器组件)-转换示例
27-数据预处理(预处理器组件)-基本信息
28-数据预处理(预处理器组件)-特征选择
29-数据预处理(预处理器组件)-填充缺失值并标准化特征
30-数据预处理(预处理器组件)-离散化连续变量
31-数据预处理(预处理器组件)-连续化离散变量
32-数据预处理(预处理器组件)-主成分分析PCA与CUR分解
33-数据预处理(缺失值处理组件)
34-数据预处理(连续化组件)
35-数据预处理(离散化组件)

















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









