








 超级会员免费看
超级会员免费看

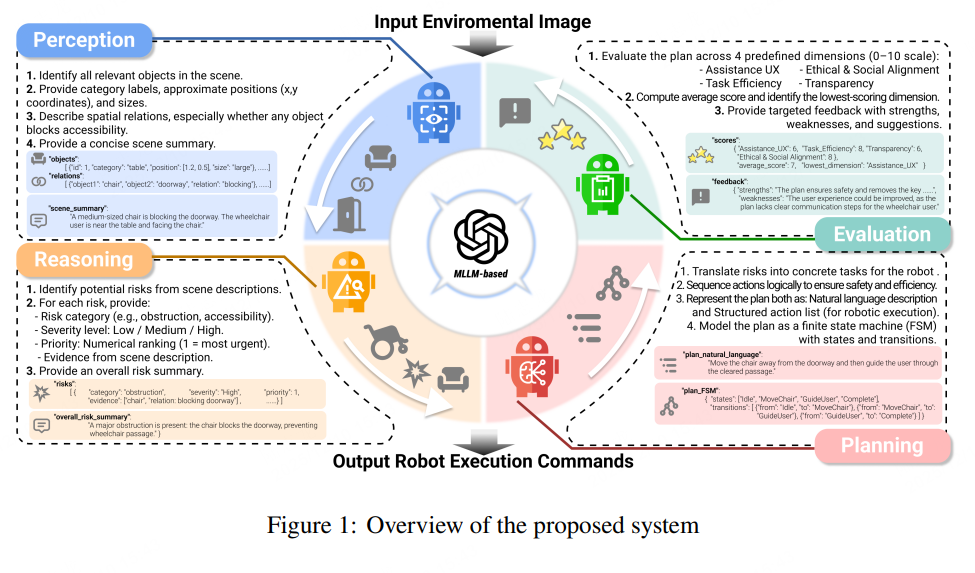
一、文章主要内容总结
该研究针对智能家居中残障人士辅助机器人的需求,提出了一种基于多模态大型语言模型(MLLMs)的多智能体协作系统MARS(Multi-Agent Robotic System),旨在解决现有系统在风险感知规划、用户个性化适配及语言计划落地执行等方面的不足。
系统核心架构包含四大智能体模块,形成“感知-推理-规划-评估”的闭环流程:
- 视觉感知智能体:融合CLIP和DeepLab v3等模型,提取环境图像的全局语义特征、目标分割及空间信息,生成结构化场景描述;
- 风险评估与推理智能体:基于预定义风险分类表(涵盖障碍物、可达性、碰撞风险等6大类),结合语义推理量化风险严重程度、紧急性及优先级;
- 规划智能体:将风险任务映射为机器人可执行的动作序列(如障碍物清除、路径引导),并考虑动作可行性与执行成本;
- 评估与优化智能体:从辅助用户体验、任务效率、透明度、伦理社会适配四大维度评估计划,通过闭环反馈迭代优化。
实验方面,在自建多场景数据集(含室内简单/复杂场景、漫画风格场景)及跨域数据集(如LLM-SAP、Home Fire Dataset)上验证,结果表明MARS在风险感知规划、多智能体协同执行等方面优于现有主流多模态模型(如LLaVA

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









