







RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
是否可将大型预训练的视觉语言模型直接集成到低级机器人控制中,以提高泛化能力并实现突现语义推理?
直接训练设计用于开放词汇视觉问答和视觉对话的视觉语言模型,以输出低级机器人动作,同时解决其他互联网规模的视觉语言任务。
RT2是在网络规模数据上训练的微调大型视觉语言模型衍生出来的模型家族,将动作编码为对应的语言文本token并协同微调训练。
相关工作
视觉语言模型
有两种主要形式:1.表示-学习模型CLIP,学习两种模态共同的嵌入;2.{视觉,文本}→{文本}形式的视觉语言模型。重点是如何将VLMs的能力扩展到机器人闭环控制中,通过赋予它们预测机器人动作的能力,从而利用VLMs中已经存在的知识,使其具有新的泛化能力。
机器人学习领域的泛化
从大量和多样化的数据集中学习,使机器人泛化到新的对象实例、新的对象和技能组合的任务、新的目标或语言指令、新颖语义对象类别任务和未知环境任务。
机器人操作的预训练
预训练的视觉表示:通过监督的ImageNet分类;数据增强;为机器人控制量身定制的目标。
预训练的语言模型:通常作为指令编码器或用于高级规划。
预训练的视觉-语言模型:使用VLMs用于视觉状态表示、用于识别物体、用于高层规划、提供监督或成功检测。CLIPort和MOO将预训练的VLM集成到端到端的视动操作策略中,但两者都将显著结构纳入到策略中,限制了其适用性。而本文工作不依赖受限的动作空间,无需标定相机,本文框架不需要引入仅有动作的模型层组件。
Vision-Language-Action Models
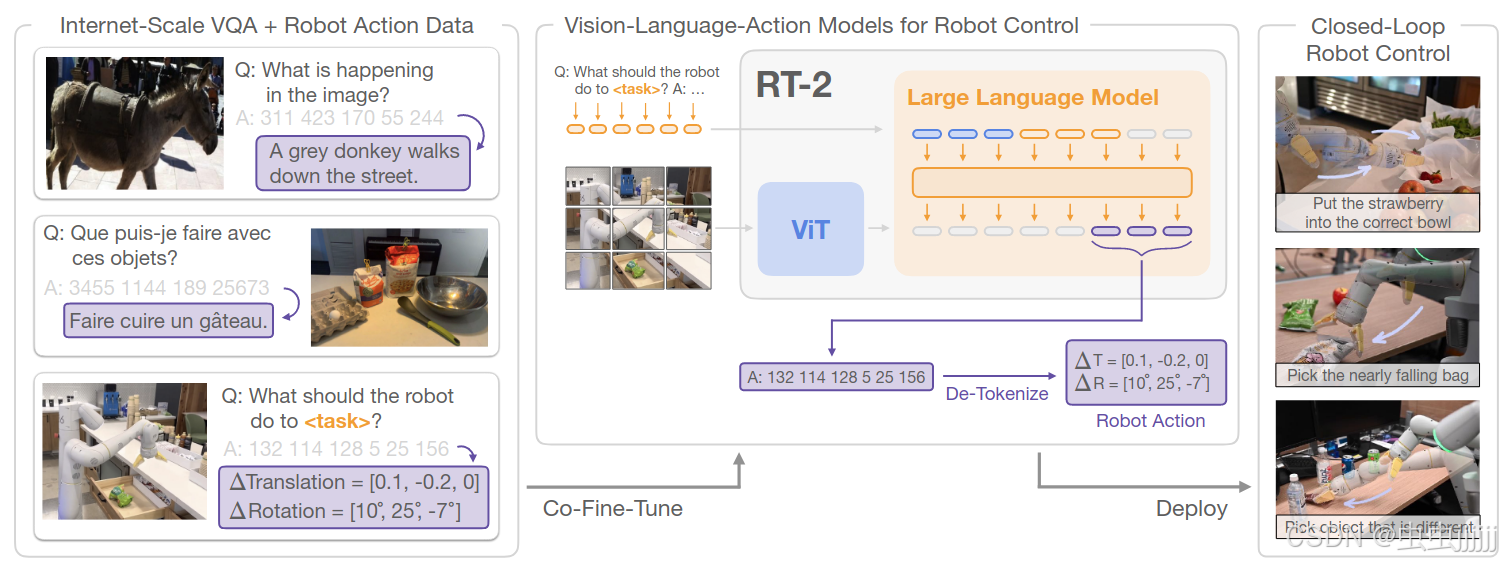
采用先前提出的VLMs作为VLA模型:PaLI-X和PaLM-E。
为了使视觉语言模型能够控制机器人,必须对其进行输出动作的训练。
本文将动作表示为模型中输出的token,将其以语言文本的形式输出,具体如下。用相应的token表示对应数字即可。
terminate Δposx Δposy Δposz Δrotx Δroty Δrotz gripperextension.terminate\ Δposx\ Δposy\ Δposz\ Δrotx\ Δroty\ Δrotz\ gripper_extension.terminate Δposx Δposy Δposz Δrotx Δroty Δrotz gripperextension.
协同微调
策略同时接触到来自Web规模数据的抽象视觉概念和低级别的机器人动作,而不仅仅是机器人动作,在协同微调过程中,通过增加机器人数据集上的采样权重来平衡每个训练批次中机器人和web数据的比例。
输出约束
VLA需要输出有效的动作token才可以在机器人上执行,为了确保RT - 2在解码过程中输出有效的动作令牌,在模型出现机器人动作任务时仅通过采样有效的动作令牌来约束其输出词汇表,而在标准的视觉语言任务上仍然允许模型输出全范围的自然语言令牌。
实时推理
将RT-2模型部署在多TPU云服务中,并在网络上查询服务。对于55B模型可以在1-3Hz的频率,对于5B模型,可以在5Hz左右的频率运行。
实验过程
利用预训练的VLM训练了两个具体的RT-2实例:RT-2-PaLI-X的55B和5B版本;RT-2-PaLM-E的12B版本;对于RT-2的训练采用了PaLI-X和PaLM-E的超参数进行训练。
基线
RT-1:基于Transformer的模型,没有使用基于VLM的预训练。
VC-1:专门为机器人任务设计的使用预训练视觉表示的视觉基础模型,由于其包含语言条件,本文通过通用语言编码器单独嵌入语言命令增加语言条件,视觉语言编码输入与RT-1类似的骨干预测机器人动作token。
R3M:使用预训练的视觉语言表示来改进策略,在训练过程中逐渐解冻。
MOO:VLM作为单独模块用于增强感知,其表示不用于策略学习。
RT - 2在已知的任务上的执行效果?在新的对象、背景和环境中的泛化能力?
对于已知任务,36个用于拾取物体,35个用于敲击物体,35个用于将事物竖直放置,48个用于移动物体,18个用于打开和关闭各种抽屉,36个用于从抽屉中拾取和放置物体。

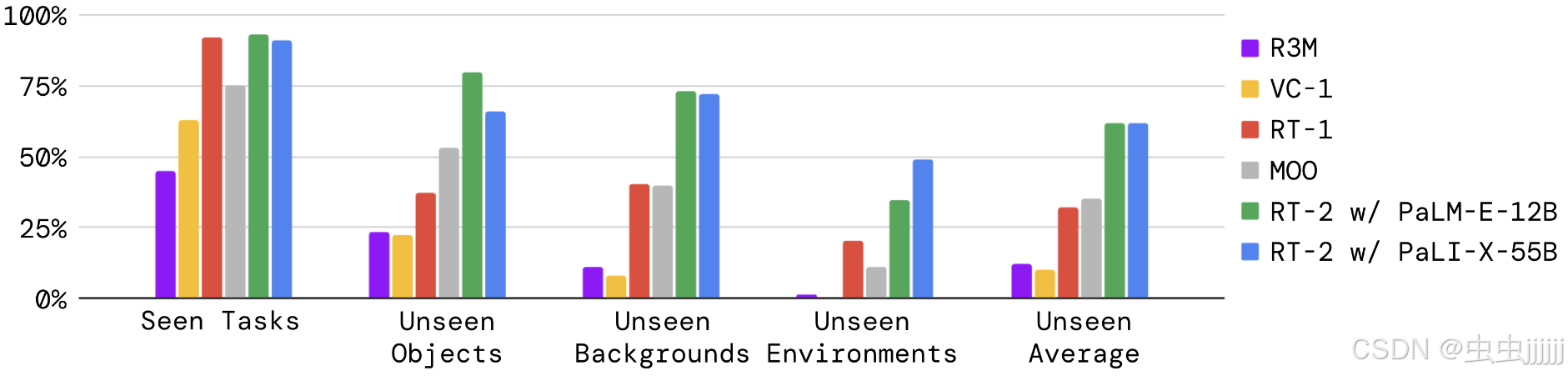
RT-1和RT-2在可见任务上表现相似,其他基线成功率较低,在泛化实验中,RT-2模型与其他基线相差明显。RT-2中12B的版本泛化能力比55B的更好。
是否能在RT-2中观察到涌现能力?
涌现能力:在机器人学习领域,期望模型能够从web规模数据预训练中迁移语义和视觉概念,包括关系和名词,能够有效地迁移,即使在那些在机器人数据中没有看到的概念的情况下。
定性评估
"把草莓放入正确的碗里"和"拾起即将从桌子上掉下来的袋子"两个任务虽然没有展示新的技能,但是体现了一定的物理和语义推理能力,这是从预训练中学习到的。
定量评估
评估中取RT-1和VC-1两个基线与本文模型进行比较。将机器人策略涌现能力分为3类:符号理解-操作对象未出现在演示集中;推理能力-“把苹果移到颜色相同的杯子里”和多语言理解-’ mueve la manzana al vaso verde ';人类识别任务-“将可乐罐搬到戴眼镜的人身上”。
在较大的VLM上预训练的模型在平均意义上具有更好的符号理解、推理和人物识别性能,但基于较小PaLM - E的模型在涉及数学推理的任务上具有优势。
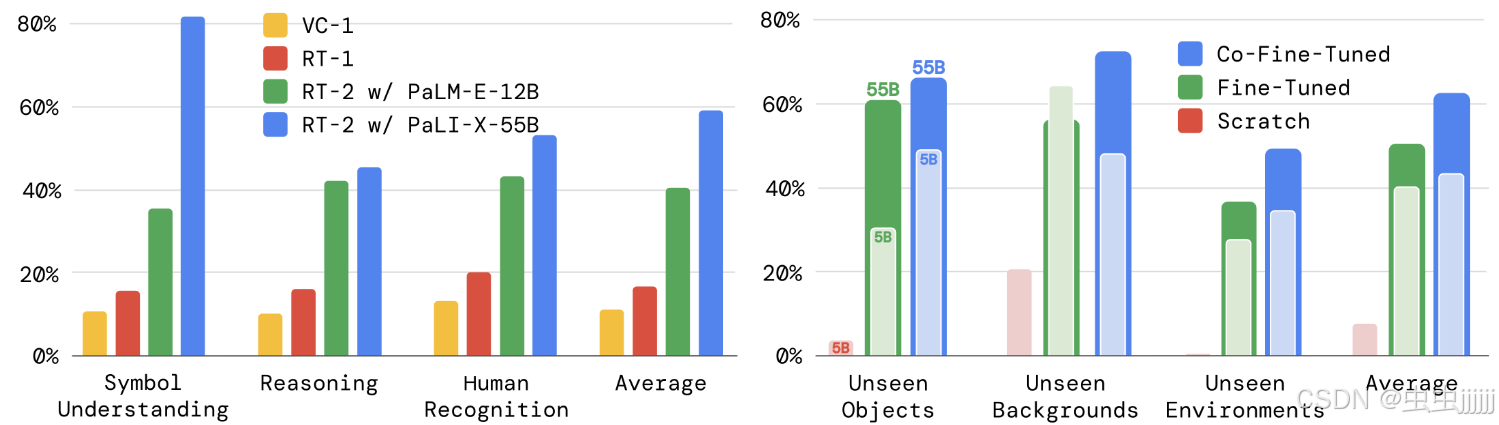
参数设计消融实验
三种训练路线:从头训练Scatch;仅使用演示数据微调;协同微调。联合微调的性能最好。
RT - 2能否表现出类似于视觉语言模型的思维链推理的迹象?
对数据进行了扩充,首先用自然语言描述机器人即将采取的行动的目的,然后是实际的行动令牌,例如指令:我饿了;计划:挑选rxbar巧克力;动作:1 128 124 136 121 158 111 255。
定性观察到,具有思维链推理的RT - 2能够回答更复杂的命令,因为它首先被赋予了用自然语言规划其动作的位置。

局限性
机器人并没有获得执行新动作的能力,该模型的物理技能仍然局限于在机器人数据中看到的技能分布,但它以新的方式学习部署这些技能。未来工作的一个令人兴奋的方向是研究如何通过新的数据收集范式(如人类的视频)来获得新的技能。
模型的计算成本很高,并且由于这些方法应用于需要高频控制的设置,实时推断可能成为一个主要的瓶颈。未来研究的一个令人兴奋的方向是探索量化和蒸馏技术,以使这些模型能够在更高的速率或更低成本的硬件上运行。


















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











